 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation in Multi-View Embedding for Cross-Modal Video Retrieval
Oct 25, 2021


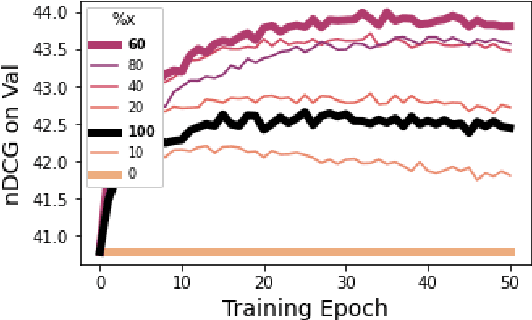
Given a gallery of uncaptioned video sequences, this paper considers the task of retrieving videos based on their relevance to an unseen text query. To compensate for the lack of annotations, we rely instead on a related video gallery composed of video-caption pairs, termed the source gallery, albeit with a domain gap between its videos and those in the target gallery. We thus introduce the problem of Unsupervised Domain Adaptation for Cross-modal Video Retrieval, along with a new benchmark on fine-grained actions. We propose a novel iterative domain alignment method by means of pseudo-labelling target videos and cross-domain (i.e. source-target) ranking. Our approach adapts the embedding space to the target gallery, consistently outperforming source-only as well as marginal and conditional alignment methods.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021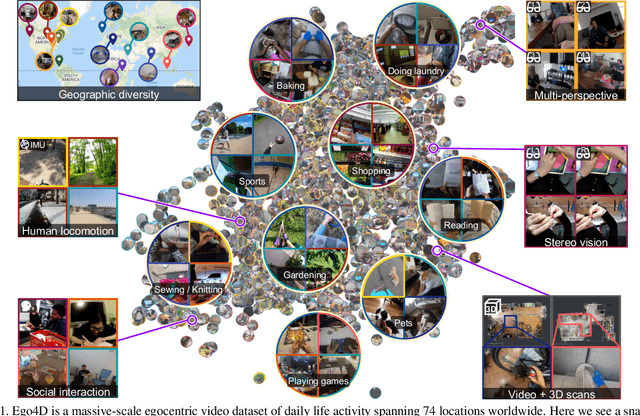
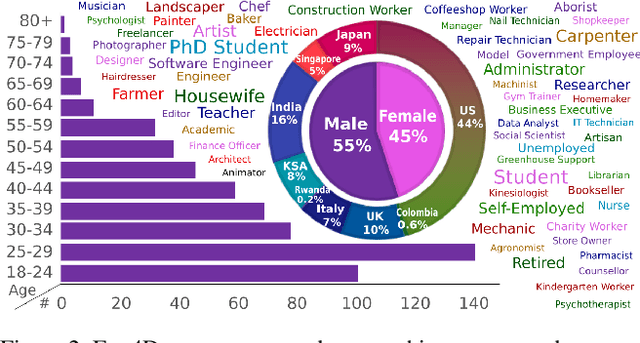

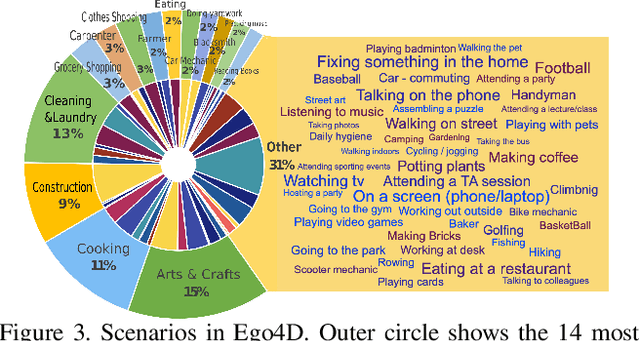
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Rescaling Egocentric Vision
Jun 23, 2020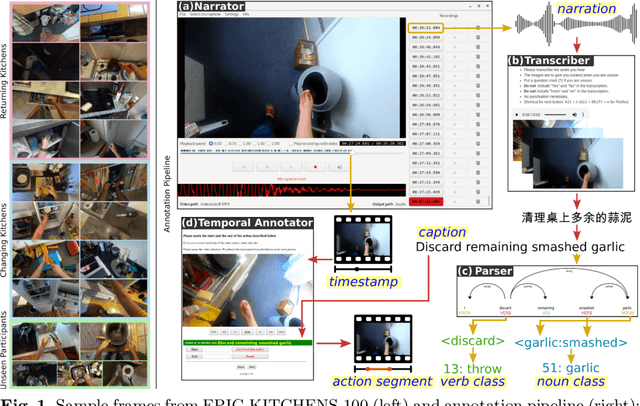
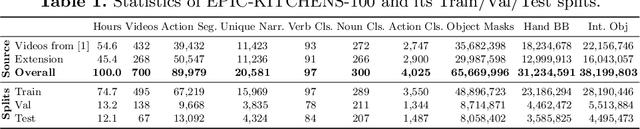
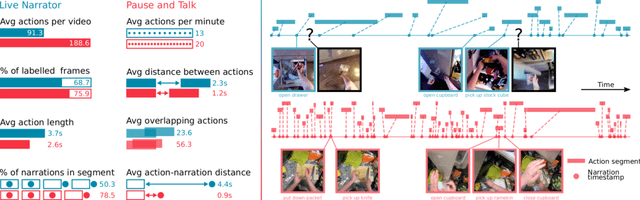
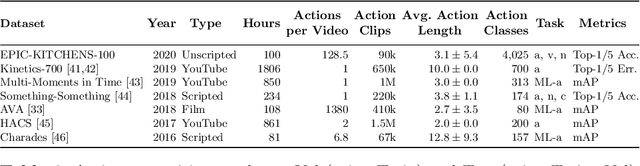
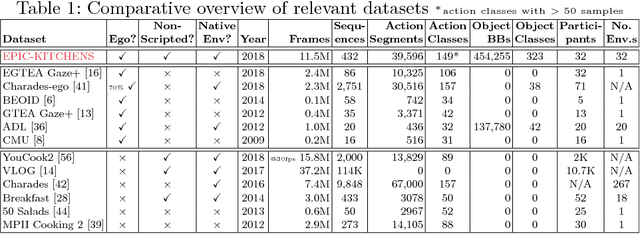
This paper introduces EPIC-KITCHENS-100, the largest annotated egocentric dataset - 100 hrs, 20M frames, 90K actions - of wearable videos capturing long-term unscripted activities in 45 environments. This extends our previous dataset (EPIC-KITCHENS-55), released in 2018, resulting in more action segments (+128%), environments (+41%) and hours (+84%), using a novel annotation pipeline that allows denser and more complete annotations of fine-grained actions (54% more actions per minute). We evaluate the "test of time" - i.e. whether models trained on data collected in 2018 can generalise to new footage collected under the same hypotheses albeit "two years on". The dataset is aligned with 6 challenges: action recognition (full and weak supervision), detection, anticipation, retrieval (from captions), as well as unsupervised domain adaptation for action recognition. For each challenge, we define the task, provide baselines and evaluation metrics. Our dataset and challenge leaderboards will be made publicly available.
The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines
Apr 29, 2020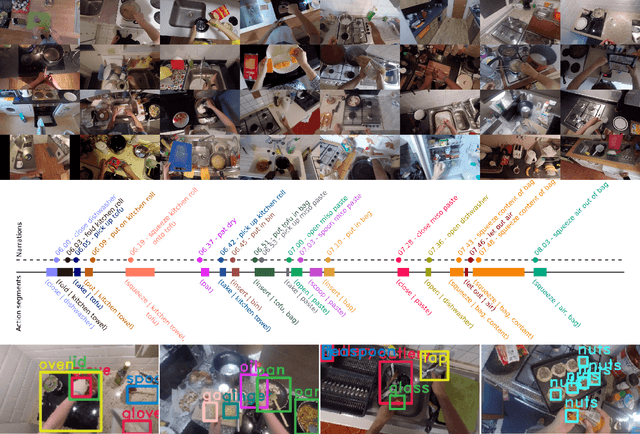
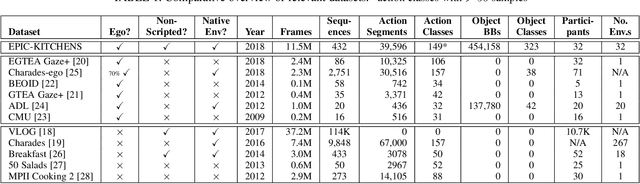

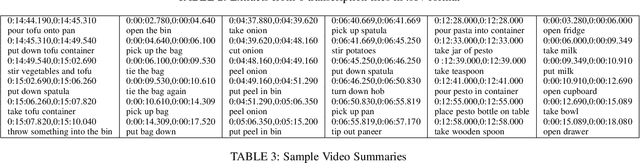
Since its introduction in 2018, EPIC-KITCHENS has attracted attention as the largest egocentric video benchmark, offering a unique viewpoint on people's interaction with objects, their attention, and even intention. In this paper, we detail how this large-scale dataset was captured by 32 participants in their native kitchen environments, and densely annotated with actions and object interactions. Our videos depict nonscripted daily activities, as recording is started every time a participant entered their kitchen. Recording took place in 4 countries by participants belonging to 10 different nationalities, resulting in highly diverse kitchen habits and cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labelled for a total of 39.6K action segments and 454.2K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos after recording, thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and. anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. We introduce new baselines that highlight the multimodal nature of the dataset and the importance of explicit temporal modelling to discriminate fine-grained actions e.g. 'closing a tap' from 'opening' it up.
Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
Jan 27, 2020

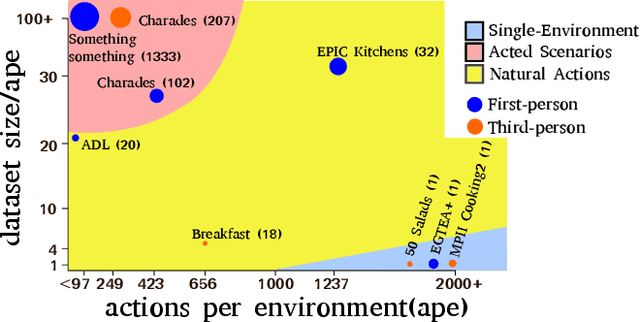

Fine-grained action recognition datasets exhibit environmental bias, where multiple video sequences are captured from a limited number of environments. Training a model in one environment and deploying in another results in a drop in performance due to an unavoidable domain shift. Unsupervised Domain Adaptation (UDA) approaches have frequently utilised adversarial training between the source and target domains. However, these approaches have not explored the multi-modal nature of video within each domain. In this work we exploit the correspondence of modalities as a self-supervised alignment approach for UDA in addition to adversarial alignment. We test our approach on three kitchens from our large-scale dataset, EPIC-Kitchens, using two modalities commonly employed for action recognition: RGB and Optical Flow. We show that multi-modal self-supervision alone improves the performance over source-only training by 2.4% on average. We then combine adversarial training with multi-modal self-supervision, showing that our approach outperforms other UDA methods by 3%.
Scaling Egocentric Vision: The EPIC-KITCHENS Dataset
Jul 31, 2018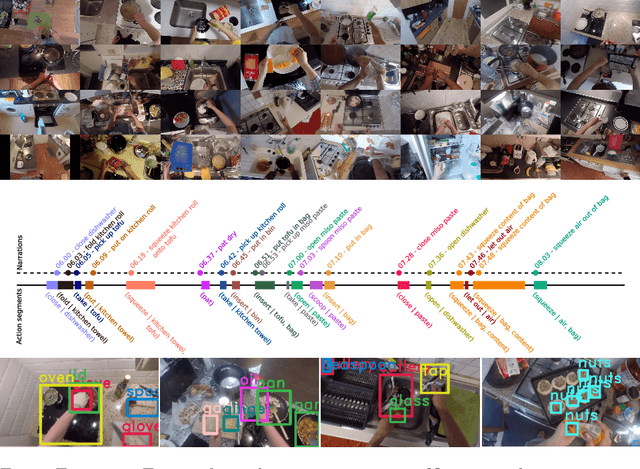


First-person vision is gaining interest as it offers a unique viewpoint on people's interaction with objects, their attention, and even intention. However, progress in this challenging domain has been relatively slow due to the lack of sufficiently large datasets. In this paper, we introduce EPIC-KITCHENS, a large-scale egocentric video benchmark recorded by 32 participants in their native kitchen environments. Our videos depict nonscripted daily activities: we simply asked each participant to start recording every time they entered their kitchen. Recording took place in 4 cities (in North America and Europe) by participants belonging to 10 different nationalities, resulting in highly diverse cooking styles. Our dataset features 55 hours of video consisting of 11.5M frames, which we densely labeled for a total of 39.6K action segments and 454.3K object bounding boxes. Our annotation is unique in that we had the participants narrate their own videos (after recording), thus reflecting true intention, and we crowd-sourced ground-truths based on these. We describe our object, action and anticipation challenges, and evaluate several baselines over two test splits, seen and unseen kitchens. Dataset and Project page: http://epic-kitchens.github.io