 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetro-Actions: Learning 'Close' by Time-Reversing 'Open' Videos
Paper and Code
Sep 20, 2019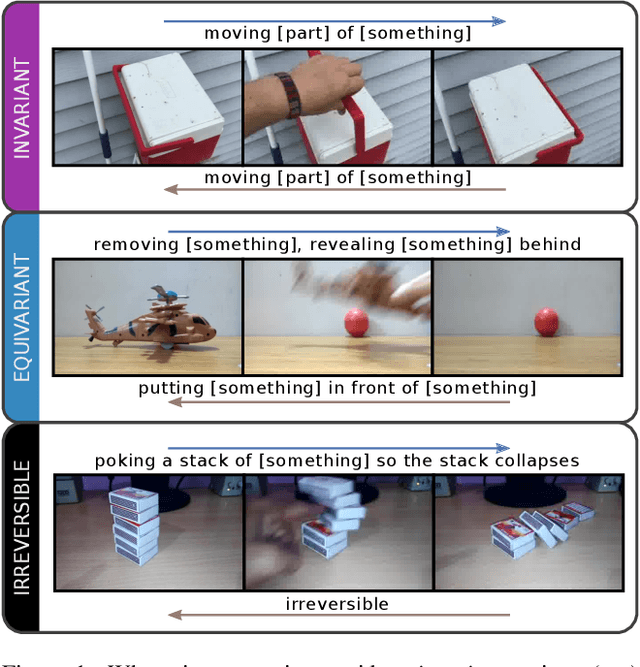
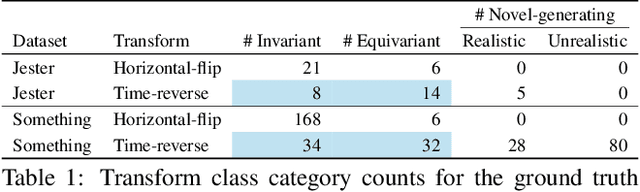

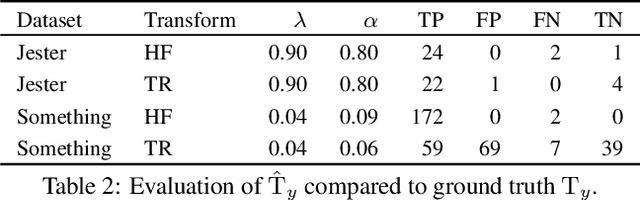
We investigate video transforms that result in class-homogeneous label-transforms. These are video transforms that consistently maintain or modify the labels of all videos in each class. We propose a general approach to discover invariant classes, whose transformed examples maintain their label; pairs of equivariant classes, whose transformed examples exchange their labels; and novel-generating classes, whose transformed examples belong to a new class outside the dataset. Label transforms offer additional supervision previously unexplored in video recognition benefiting data augmentation and enabling zero-shot learning opportunities by learning a class from transformed videos of its counterpart. Amongst such video transforms, we study horizontal-flipping, time-reversal, and their composition. We highlight errors in naively using horizontal-flipping as a form of data augmentation in video. Next, we validate the realism of time-reversed videos through a human perception study where people exhibit equal preference for forward and time-reversed videos. Finally, we test our approach on two datasets, Jester and Something-Something, evaluating the three video transforms for zero-shot learning and data augmentation. Our results show that gestures such as zooming in can be learnt from zooming out in a zero-shot setting, as well as more complex actions with state transitions such as digging something out of something from burying something in something.