 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualGPTScore: Visio-Linguistic Reasoning with Multimodal Generative Pre-Training Scores
Paper and Code

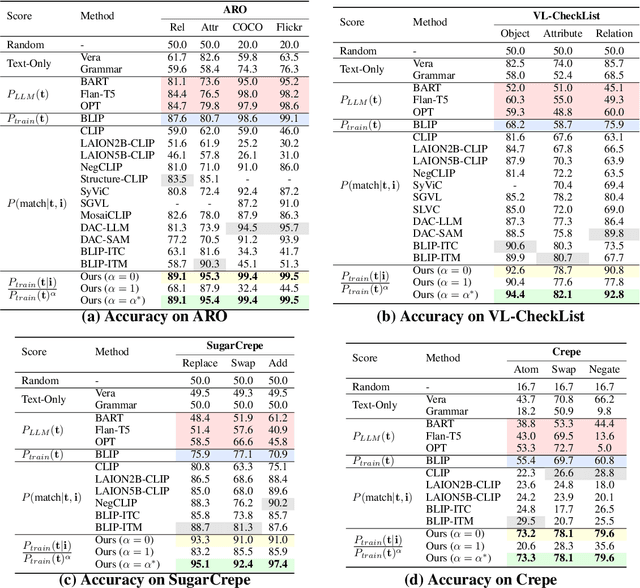
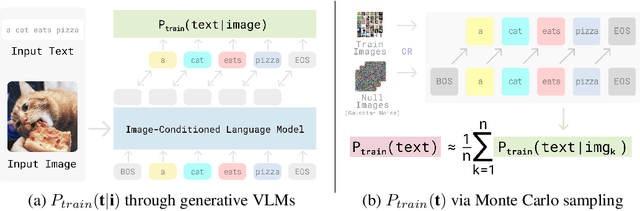
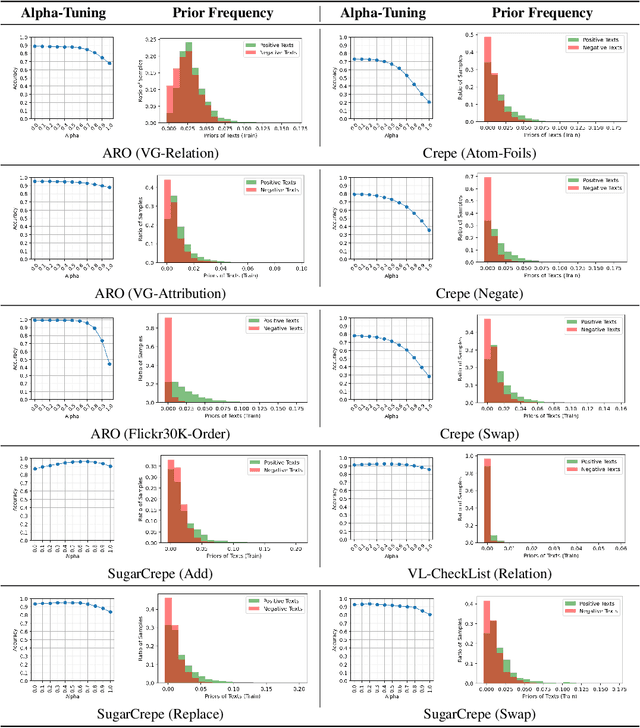
Vision-language models (VLMs) discriminatively pre-trained with contrastive image-text matching losses such as $P(\text{match}|\text{text}, \text{image})$ have been criticized for lacking compositional understanding. This means they might output similar scores even if the original caption is rearranged into a different semantic statement. To address this, we propose to use the ${\bf V}$isual ${\bf G}$enerative ${\bf P}$re-${\bf T}$raining Score (${\bf VisualGPTScore}$) of $P(\text{text}|\text{image})$, a $\textit{multimodal generative}$ score that captures the likelihood of a text caption conditioned on an image using an image-conditioned language model. Contrary to the belief that VLMs are mere bag-of-words models, our off-the-shelf VisualGPTScore demonstrates top-tier performance on recently proposed image-text retrieval benchmarks like ARO and Crepe that assess compositional reasoning. Furthermore, we factorize VisualGPTScore into a product of the $\textit{marginal}$ P(text) and the $\textit{Pointwise Mutual Information}$ (PMI). This helps to (a) diagnose datasets with strong language bias, and (b) debias results on other benchmarks like Winoground using an information-theoretic framework. VisualGPTScore provides valuable insights and serves as a strong baseline for future evaluation of visio-linguistic compositionality.