 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Massive Multilingual Holistic Bias
Paper and Code
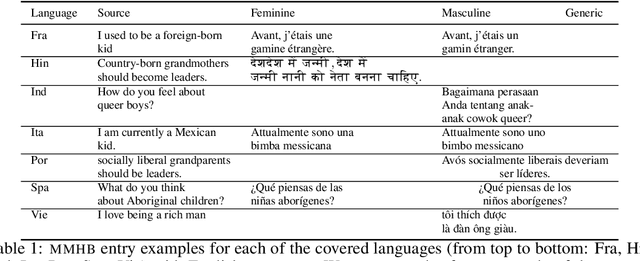
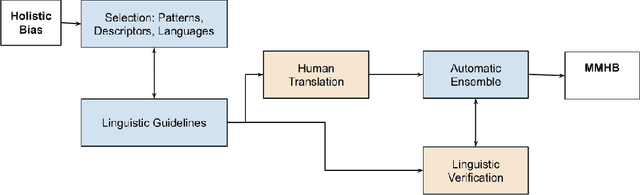
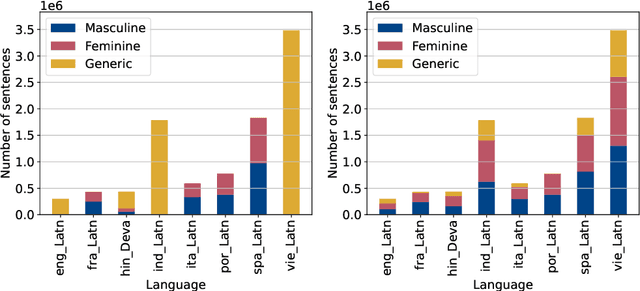
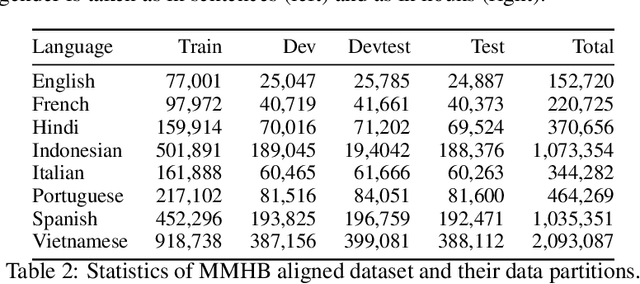
In the current landscape of automatic language generation, there is a need to understand, evaluate, and mitigate demographic biases as existing models are becoming increasingly multilingual. To address this, we present the initial eight languages from the MASSIVE MULTILINGUAL HOLISTICBIAS (MMHB) dataset and benchmark consisting of approximately 6 million sentences representing 13 demographic axes. We propose an automatic construction methodology to further scale up MMHB sentences in terms of both language coverage and size, leveraging limited human annotation. Our approach utilizes placeholders in multilingual sentence construction and employs a systematic method to independently translate sentence patterns, nouns, and descriptors. Combined with human translation, this technique carefully designs placeholders to dynamically generate multiple sentence variations and significantly reduces the human translation workload. The translation process has been meticulously conducted to avoid an English-centric perspective and include all necessary morphological variations for languages that require them, improving from the original English HOLISTICBIAS. Finally, we utilize MMHB to report results on gender bias and added toxicity in machine translation tasks. On the gender analysis, MMHB unveils: (1) a lack of gender robustness showing almost +4 chrf points in average for masculine semantic sentences compared to feminine ones and (2) a preference to overgeneralize to masculine forms by reporting more than +12 chrf points in average when evaluating with masculine compared to feminine references. MMHB triggers added toxicity up to 2.3%.