 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Towards Red Teaming in Multimodal and Multilingual Translation
Jan 29, 2024Assessing performance in Natural Language Processing is becoming increasingly complex. One particular challenge is the potential for evaluation datasets to overlap with training data, either directly or indirectly, which can lead to skewed results and overestimation of model performance. As a consequence, human evaluation is gaining increasing interest as a means to assess the performance and reliability of models. One such method is the red teaming approach, which aims to generate edge cases where a model will produce critical errors. While this methodology is becoming standard practice for generative AI, its application to the realm of conditional AI remains largely unexplored. This paper presents the first study on human-based red teaming for Machine Translation (MT), marking a significant step towards understanding and improving the performance of translation models. We delve into both human-based red teaming and a study on automation, reporting lessons learned and providing recommendations for both translation models and red teaming drills. This pioneering work opens up new avenues for research and development in the field of MT.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
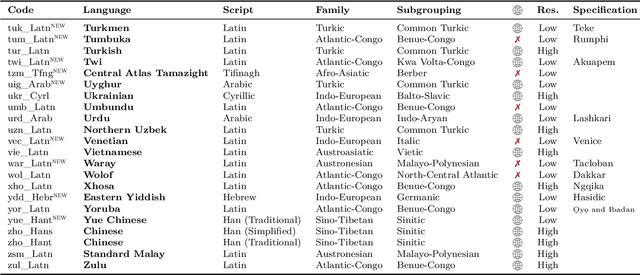
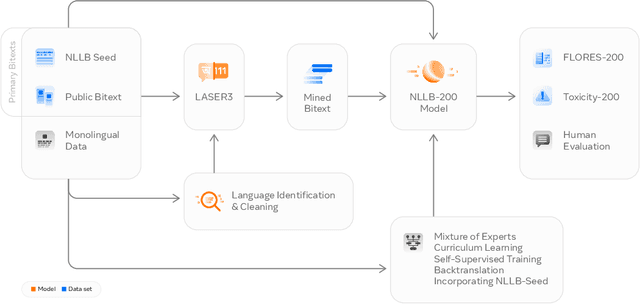
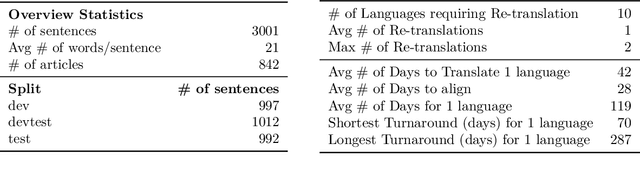
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.