 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Sub-meter resolution canopy height maps using self-supervised learning and a vision transformer trained on Aerial and GEDI Lidar
Apr 17, 2023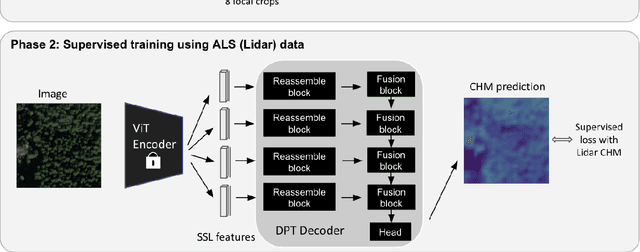
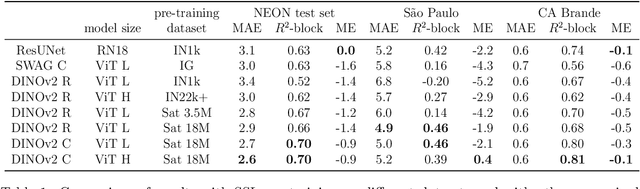
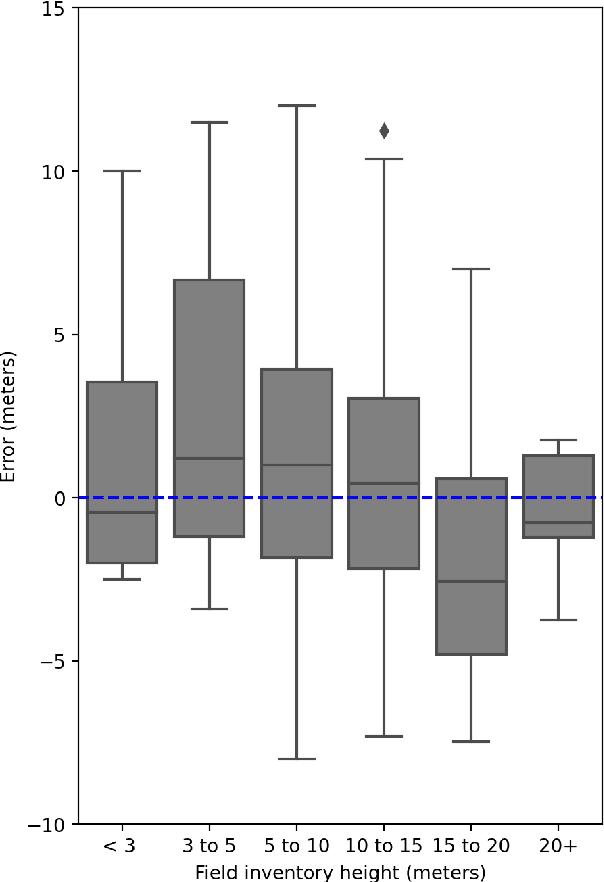
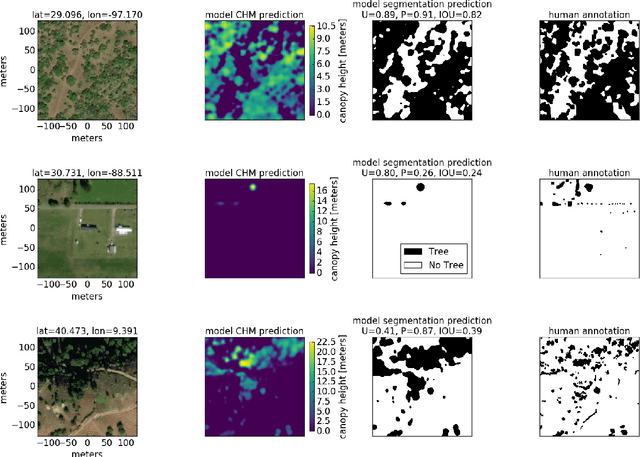
Vegetation structure mapping is critical for understanding the global carbon cycle and monitoring nature-based approaches to climate adaptation and mitigation. Repeat measurements of these data allow for the observation of deforestation or degradation of existing forests, natural forest regeneration, and the implementation of sustainable agricultural practices like agroforestry. Assessments of tree canopy height and crown projected area at a high spatial resolution are also important for monitoring carbon fluxes and assessing tree-based land uses, since forest structures can be highly spatially heterogeneous, especially in agroforestry systems. Very high resolution satellite imagery (less than one meter (1m) ground sample distance) makes it possible to extract information at the tree level while allowing monitoring at a very large scale. This paper presents the first high-resolution canopy height map concurrently produced for multiple sub-national jurisdictions. Specifically, we produce canopy height maps for the states of California and S\~{a}o Paolo, at sub-meter resolution, a significant improvement over the ten meter (10m) resolution of previous Sentinel / GEDI based worldwide maps of canopy height. The maps are generated by applying a vision transformer to features extracted from a self-supervised model in Maxar imagery from 2017 to 2020, and are trained against aerial lidar and GEDI observations. We evaluate the proposed maps with set-aside validation lidar data as well as by comparing with other remotely sensed maps and field-collected data, and find our model produces an average Mean Absolute Error (MAE) within set-aside validation areas of 3.0 meters.
A global method to identify trees inside and outside of forests with medium-resolution satellite imagery
May 13, 2020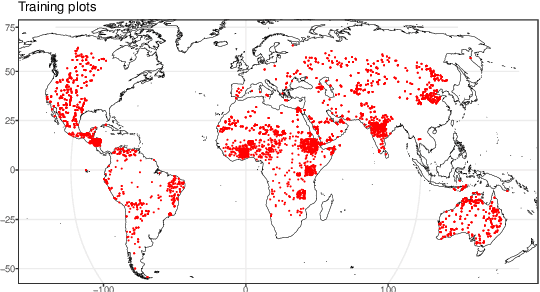
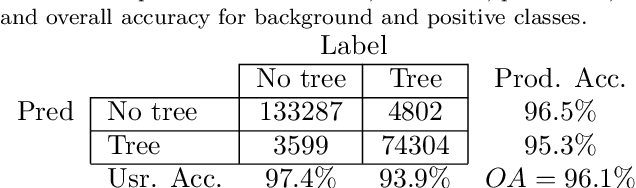
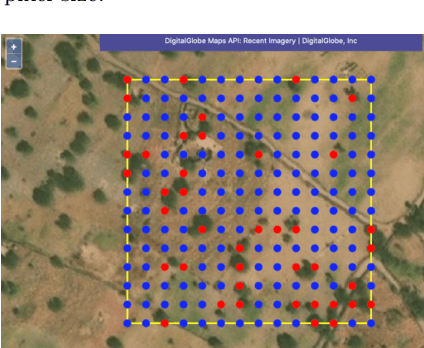
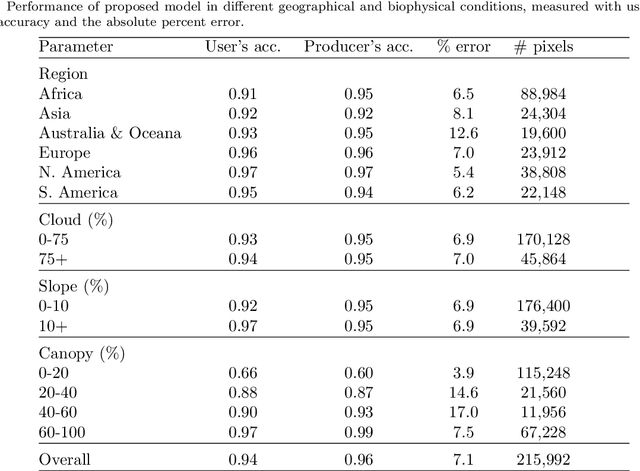
Scattered trees outside of dense forests are very important for carbon sequestration, supporting livelihoods, maintaining ecosystem integrity, and climate change adaptation and mitigation. In contrast to trees inside of forests, not much is known about the spatial extent and distribution of scattered trees at a global scale. Due to the very high cost of high-resolution satellite imagery, global monitoring systems rely on medium resolution satellites to monitor land use and land use change. However, detecting and monitoring scattered trees with an open canopy using medium resolution satellites is difficult because individual trees often cover a smaller footprint than the satellites resolution. Here we present a globally consistent method to identify trees inside and outside of forests with medium resolution optical and radar imagery. Biweekly cloud-free, pansharpened 10 meter Sentinel-2 optical imagery and Sentinel-1 radar imagery are used to train a fully convolutional network, consisting of a convolutional gated recurrent unit layer and a feature pyramid attention layer. Tested across more than 215,000 Sentinel-1 and Sentinel-2 pixels distributed from -60 to +60 latitude, the proposed model exceeds 75 percent users and producers accuracy identifying trees in hectares with a low to medium density (less than 40 percent) of canopy cover, and 95 percent user's and producer's accuracy in hectares with dense (greater than 40 percent) canopy cover. When applied across large, heterogeneous landscapes, the results demonstrate potential to map trees in high detail and consistent accuracy over diverse landscapes across the globe. This information is important for understanding current land cover and can be used to detect changes in land cover such as agroforestry, buffer zones around biological hotspots, and expansion or encroachment of forests.
Text mining policy: Classifying forest and landscape restoration policy agenda with neural information retrieval
Aug 07, 2019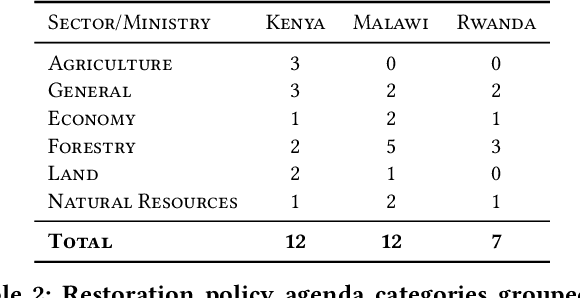
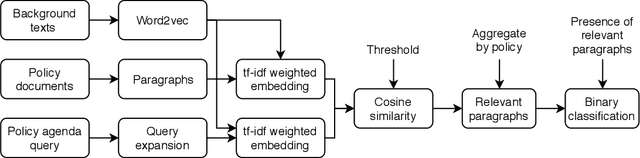


Dozens of countries have committed to restoring the ecological functionality of 350 million hectares of land by 2030. In order to achieve such wide-scale implementation of restoration, the values and priorities of multi-sectoral stakeholders must be aligned and integrated with national level commitments and other development agenda. Although misalignment across scales of policy and between stakeholders are well known barriers to implementing restoration, fast-paced policy making in multi-stakeholder environments complicates the monitoring and analysis of governance and policy. In this work, we assess the potential of machine learning to identify restoration policy agenda across diverse policy documents. An unsupervised neural information retrieval architecture is introduced that leverages transfer learning and word embeddings to create high-dimensional representations of paragraphs. Policy agenda labels are recast as information retrieval queries in order to classify policies with a cosine similarity threshold between paragraphs and query embeddings. This approach achieves a 0.83 F1-score measured across 14 policy agenda in 31 policy documents in Malawi, Kenya, and Rwanda, indicating that automated text mining can provide reliable, generalizable, and efficient analyses of restoration policy.
Spatio-temporal crop classification of low-resolution satellite imagery with capsule layers and distributed attention
Apr 23, 2019
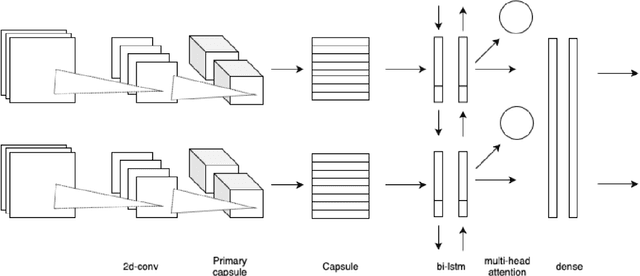
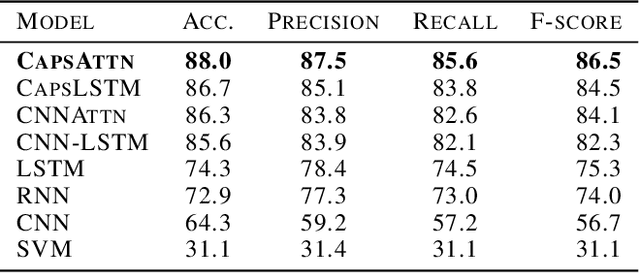
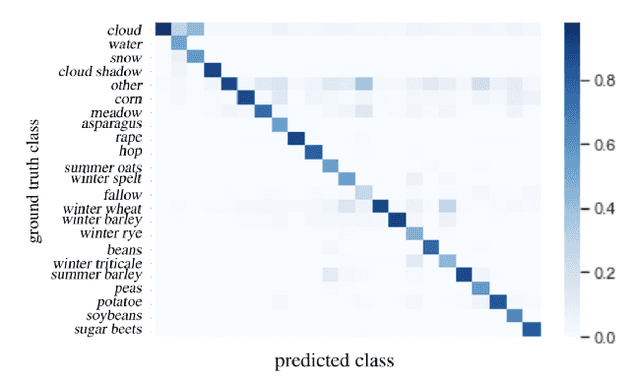
Land use classification of low resolution spatial imagery is one of the most extensively researched fields in remote sensing. Despite significant advancements in satellite technology, high resolution imagery lacks global coverage and can be prohibitively expensive to procure for extended time periods. Accurately classifying land use change without high resolution imagery offers the potential to monitor vital aspects of global development agenda including climate smart agriculture, drought resistant crops, and sustainable land management. Utilizing a combination of capsule layers and long-short term memory layers with distributed attention, the present paper achieves state-of-the-art accuracy on temporal crop type classification at a 30x30m resolution with Sentinel 2 imagery.
Imbalanced multi-label classification using multi-task learning with extractive summarization
Mar 16, 2019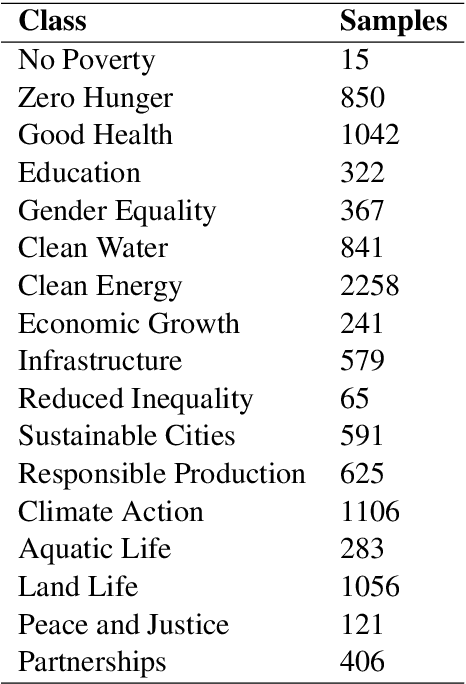
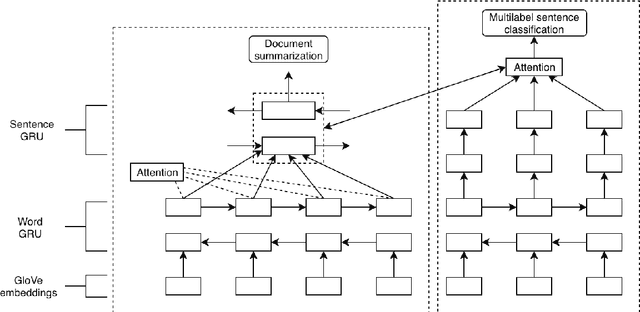
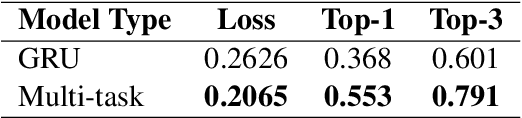
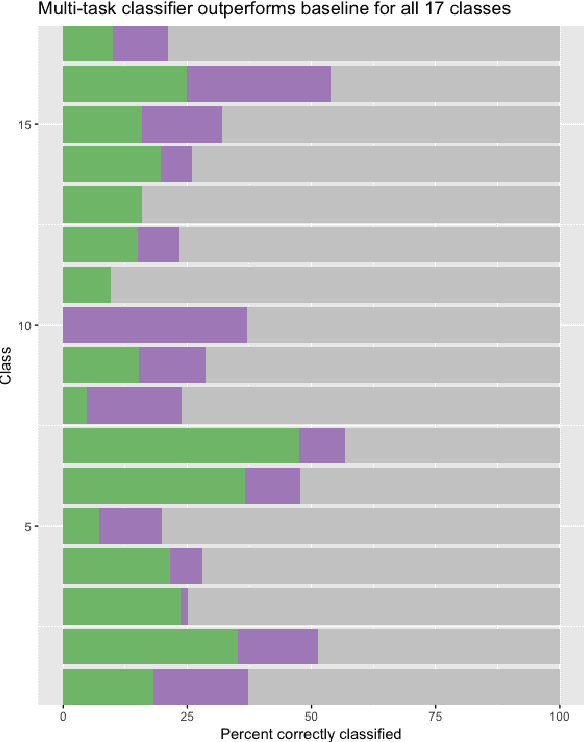
Extractive summarization and imbalanced multi-label classification often require vast amounts of training data to avoid overfitting. In situations where training data is expensive to generate, leveraging information between tasks is an attractive approach to increasing the amount of available information. This paper employs multi-task training of an extractive summarizer and an RNN-based classifier to improve summarization and classification accuracy by 50% and 75%, respectively, relative to RNN baselines. We hypothesize that concatenating sentence encodings based on document and class context increases generalizability for highly variable corpuses.