 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradpaint: Gradient-Guided Inpainting with Diffusion Models
Sep 18, 2023Denoising Diffusion Probabilistic Models (DDPMs) have recently achieved remarkable results in conditional and unconditional image generation. The pre-trained models can be adapted without further training to different downstream tasks, by guiding their iterative denoising process at inference time to satisfy additional constraints. For the specific task of image inpainting, the current guiding mechanism relies on copying-and-pasting the known regions from the input image at each denoising step. However, diffusion models are strongly conditioned by the initial random noise, and therefore struggle to harmonize predictions inside the inpainting mask with the real parts of the input image, often producing results with unnatural artifacts. Our method, dubbed GradPaint, steers the generation towards a globally coherent image. At each step in the denoising process, we leverage the model's "denoised image estimation" by calculating a custom loss measuring its coherence with the masked input image. Our guiding mechanism uses the gradient obtained from backpropagating this loss through the diffusion model itself. GradPaint generalizes well to diffusion models trained on various datasets, improving upon current state-of-the-art supervised and unsupervised methods.
Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval
Apr 20, 2022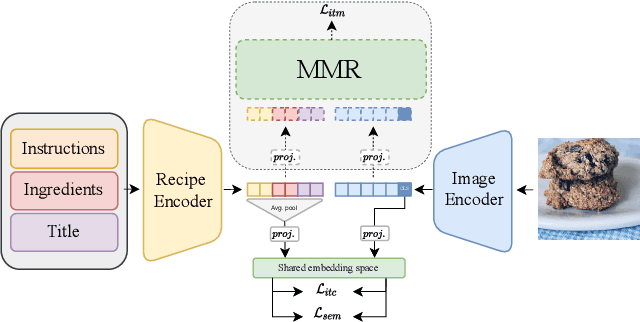

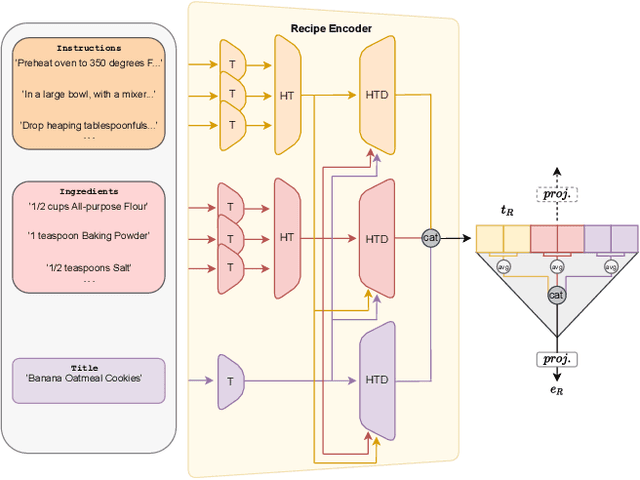
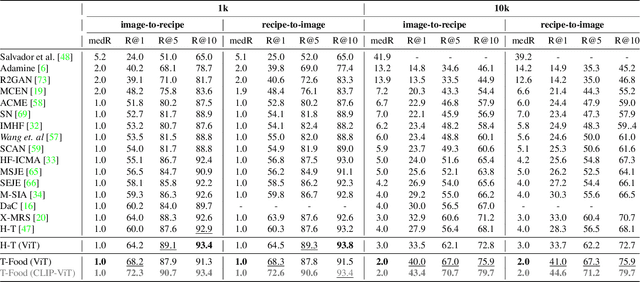
Cross-modal image-recipe retrieval has gained significant attention in recent years. Most work focuses on improving cross-modal embeddings using unimodal encoders, that allow for efficient retrieval in large-scale databases, leaving aside cross-attention between modalities which is more computationally expensive. We propose a new retrieval framework, T-Food (Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval) that exploits the interaction between modalities in a novel regularization scheme, while using only unimodal encoders at test time for efficient retrieval. We also capture the intra-dependencies between recipe entities with a dedicated recipe encoder, and propose new variants of triplet losses with dynamic margins that adapt to the difficulty of the task. Finally, we leverage the power of the recent Vision and Language Pretraining (VLP) models such as CLIP for the image encoder. Our approach outperforms existing approaches by a large margin on the Recipe1M dataset. Specifically, we achieve absolute improvements of 8.1 % (72.6 R@1) and +10.9 % (44.6 R@1) on the 1k and 10k test sets respectively. The code is available here:https://github.com/mshukor/TFood
FlexIT: Towards Flexible Semantic Image Translation
Mar 09, 2022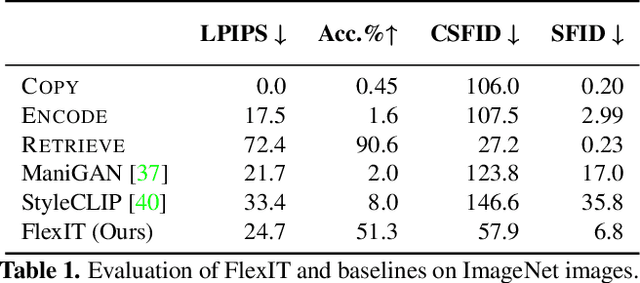
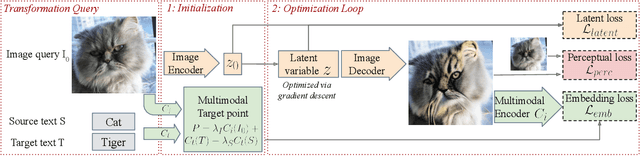

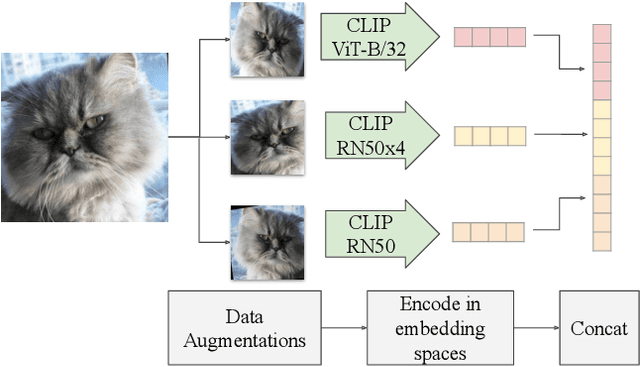
Deep generative models, like GANs, have considerably improved the state of the art in image synthesis, and are able to generate near photo-realistic images in structured domains such as human faces. Based on this success, recent work on image editing proceeds by projecting images to the GAN latent space and manipulating the latent vector. However, these approaches are limited in that only images from a narrow domain can be transformed, and with only a limited number of editing operations. We propose FlexIT, a novel method which can take any input image and a user-defined text instruction for editing. Our method achieves flexible and natural editing, pushing the limits of semantic image translation. First, FlexIT combines the input image and text into a single target point in the CLIP multimodal embedding space. Via the latent space of an auto-encoder, we iteratively transform the input image toward the target point, ensuring coherence and quality with a variety of novel regularization terms. We propose an evaluation protocol for semantic image translation, and thoroughly evaluate our method on ImageNet. Code will be made publicly available.