 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Convolutional networks with attention-based aggregation
Paper and Code

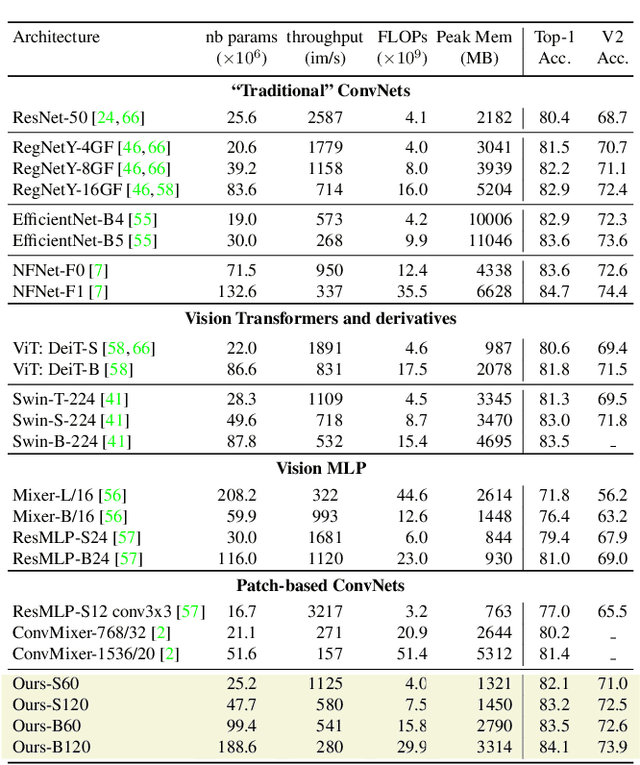

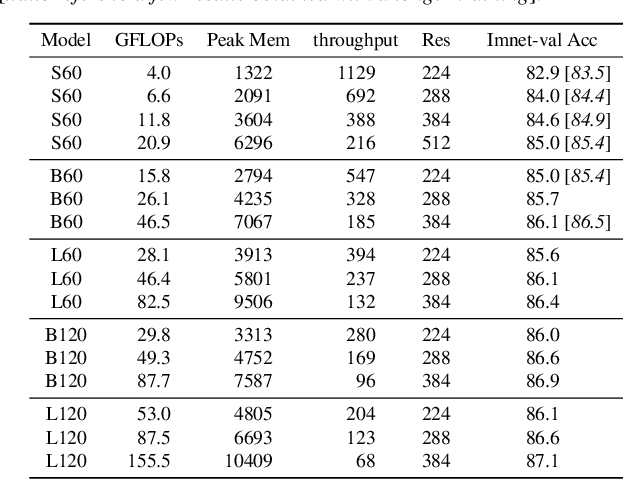
We show how to augment any convolutional network with an attention-based global map to achieve non-local reasoning. We replace the final average pooling by an attention-based aggregation layer akin to a single transformer block, that weights how the patches are involved in the classification decision. We plug this learned aggregation layer with a simplistic patch-based convolutional network parametrized by 2 parameters (width and depth). In contrast with a pyramidal design, this architecture family maintains the input patch resolution across all the layers. It yields surprisingly competitive trade-offs between accuracy and complexity, in particular in terms of memory consumption, as shown by our experiments on various computer vision tasks: object classification, image segmentation and detection.