 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntellAgent: A Multi-Agent Framework for Evaluating Conversational AI Systems
Jan 19, 2025Large Language Models (LLMs) are transforming artificial intelligence, evolving into task-oriented systems capable of autonomous planning and execution. One of the primary applications of LLMs is conversational AI systems, which must navigate multi-turn dialogues, integrate domain-specific APIs, and adhere to strict policy constraints. However, evaluating these agents remains a significant challenge, as traditional methods fail to capture the complexity and variability of real-world interactions. We introduce IntellAgent, a scalable, open-source multi-agent framework designed to evaluate conversational AI systems comprehensively. IntellAgent automates the creation of diverse, synthetic benchmarks by combining policy-driven graph modeling, realistic event generation, and interactive user-agent simulations. This innovative approach provides fine-grained diagnostics, addressing the limitations of static and manually curated benchmarks with coarse-grained metrics. IntellAgent represents a paradigm shift in evaluating conversational AI. By simulating realistic, multi-policy scenarios across varying levels of complexity, IntellAgent captures the nuanced interplay of agent capabilities and policy constraints. Unlike traditional methods, it employs a graph-based policy model to represent relationships, likelihoods, and complexities of policy interactions, enabling highly detailed diagnostics. IntellAgent also identifies critical performance gaps, offering actionable insights for targeted optimization. Its modular, open-source design supports seamless integration of new domains, policies, and APIs, fostering reproducibility and community collaboration. Our findings demonstrate that IntellAgent serves as an effective framework for advancing conversational AI by addressing challenges in bridging research and deployment. The framework is available at https://github.com/plurai-ai/intellagent
Intent-based Prompt Calibration: Enhancing prompt optimization with synthetic boundary cases
Feb 05, 2024
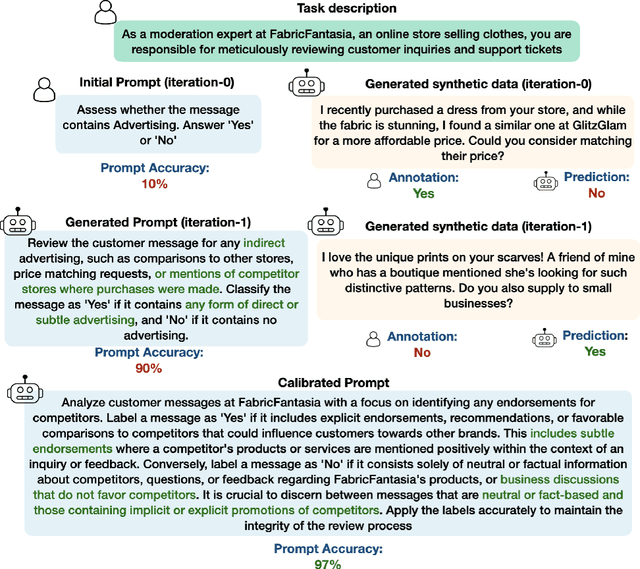

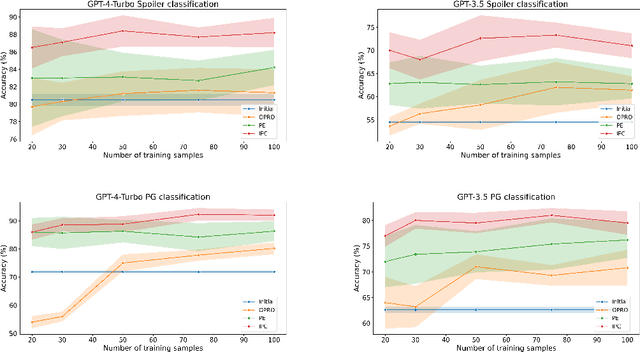
Prompt engineering is a challenging and important task due to the high sensitivity of Large Language Models (LLMs) to the given prompt and the inherent ambiguity of a textual task instruction. Automatic prompt engineering is essential to achieve optimized performance from LLMs. Recent studies have demonstrated the capabilities of LLMs to automatically conduct prompt engineering by employing a meta-prompt that incorporates the outcomes of the last trials and proposes an improved prompt. However, this requires a high-quality benchmark to compare different prompts, which is difficult and expensive to acquire in many real-world use cases. In this work, we introduce a new method for automatic prompt engineering, using a calibration process that iteratively refines the prompt to the user intent. During the optimization process, the system jointly generates synthetic data of boundary use cases and optimizes the prompt according to the generated dataset. We demonstrate the effectiveness of our method with respect to strong proprietary models on real-world tasks such as moderation and generation. Our method outperforms state-of-the-art methods with a limited number of annotated samples. Furthermore, we validate the advantages of each one of the system's key components. Our system is built in a modular way, facilitating easy adaptation to other tasks. The code is available $\href{https://github.com/Eladlev/AutoPrompt}{here}$.
Stay on topic with Classifier-Free Guidance
Jun 30, 2023



Classifier-Free Guidance (CFG) has recently emerged in text-to-image generation as a lightweight technique to encourage prompt-adherence in generations. In this work, we demonstrate that CFG can be used broadly as an inference-time technique in pure language modeling. We show that CFG (1) improves the performance of Pythia, GPT-2 and LLaMA-family models across an array of tasks: Q\&A, reasoning, code generation, and machine translation, achieving SOTA on LAMBADA with LLaMA-7B over PaLM-540B; (2) brings improvements equivalent to a model with twice the parameter-count; (3) can stack alongside other inference-time methods like Chain-of-Thought and Self-Consistency, yielding further improvements in difficult tasks; (4) can be used to increase the faithfulness and coherence of assistants in challenging form-driven and content-driven prompts: in a human evaluation we show a 75\% preference for GPT4All using CFG over baseline.
DLT: Conditioned layout generation with Joint Discrete-Continuous Diffusion Layout Transformer
Mar 07, 2023Generating visual layouts is an essential ingredient of graphic design. The ability to condition layout generation on a partial subset of component attributes is critical to real-world applications that involve user interaction. Recently, diffusion models have demonstrated high-quality generative performances in various domains. However, it is unclear how to apply diffusion models to the natural representation of layouts which consists of a mix of discrete (class) and continuous (location, size) attributes. To address the conditioning layout generation problem, we introduce DLT, a joint discrete-continuous diffusion model. DLT is a transformer-based model which has a flexible conditioning mechanism that allows for conditioning on any given subset of all the layout component classes, locations, and sizes. Our method outperforms state-of-the-art generative models on various layout generation datasets with respect to different metrics and conditioning settings. Additionally, we validate the effectiveness of our proposed conditioning mechanism and the joint continuous-diffusion process. This joint process can be incorporated into a wide range of mixed discrete-continuous generative tasks.
Reducing Class Collapse in Metric Learning with Easy Positive Sampling
Jun 09, 2020

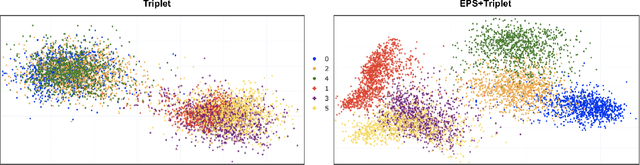
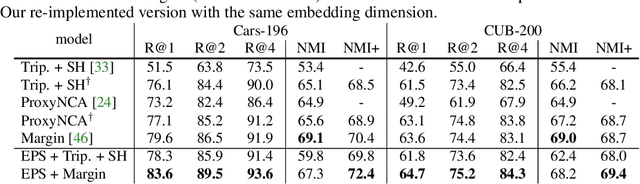
Metric learning seeks perceptual embeddings where visually similar instances are close and dissimilar instances are apart, but learn representation can be sub-optimal when the distribution of intra-class samples is diverse and distinct sub-clusters are present. We theoretically prove and empirically show that under reasonable noise assumptions, prevalent embedding losses in metric learning, e.g., triplet loss, tend to project all samples of a class with various modes onto a single point in the embedding space, resulting in class collapse that usually renders the space ill-sorted for classification or retrieval. To address this problem, we propose a simple modification to the embedding losses such that each sample selects its nearest same-class counterpart in a batch as the positive element in the tuple. This allows for the presence of multiple sub-clusters within each class. The adaptation can be integrated into a wide range of metric learning losses. Our method demonstrates clear benefits on various fine-grained image retrieval datasets over a variety of existing losses; qualitative retrieval results show that samples with similar visual patterns are indeed closer in the embedding space.
Accurate Visual Localization for Automotive Applications
May 01, 2019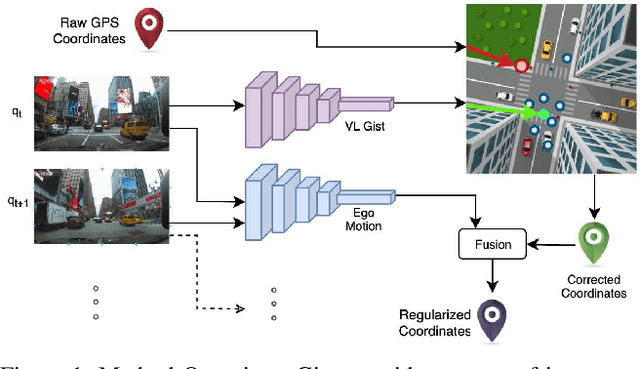

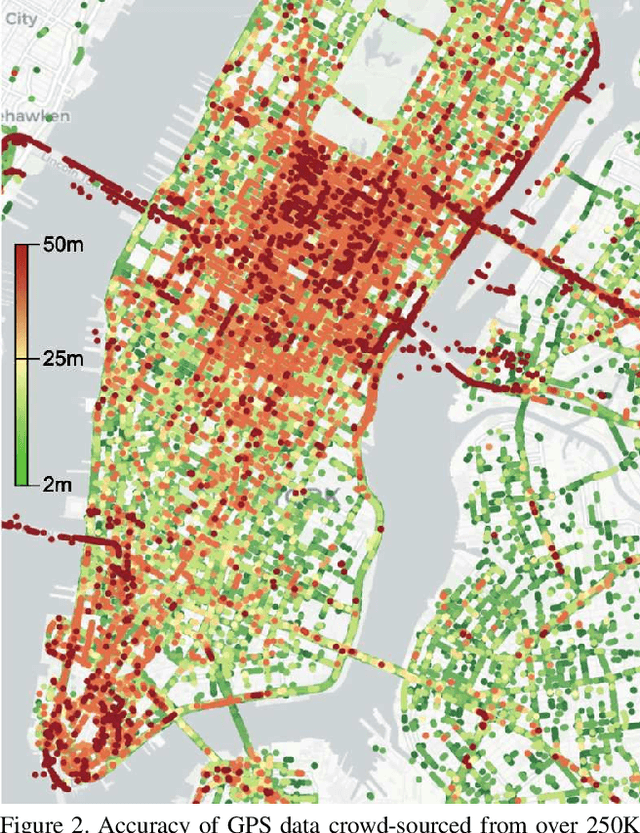

Accurate vehicle localization is a crucial step towards building effective Vehicle-to-Vehicle networks and automotive applications. Yet standard grade GPS data, such as that provided by mobile phones, is often noisy and exhibits significant localization errors in many urban areas. Approaches for accurate localization from imagery often rely on structure-based techniques, and thus are limited in scale and are expensive to compute. In this paper, we present a scalable visual localization approach geared for real-time performance. We propose a hybrid coarse-to-fine approach that leverages visual and GPS location cues. Our solution uses a self-supervised approach to learn a compact road image representation. This representation enables efficient visual retrieval and provides coarse localization cues, which are fused with vehicle ego-motion to obtain high accuracy location estimates. As a benchmark to evaluate the performance of our visual localization approach, we introduce a new large-scale driving dataset based on video and GPS data obtained from a large-scale network of connected dash-cams. Our experiments confirm that our approach is highly effective in challenging urban environments, reducing localization error by an order of magnitude.
Classifying Collisions with Spatio-Temporal Action Graph Networks
Dec 04, 2018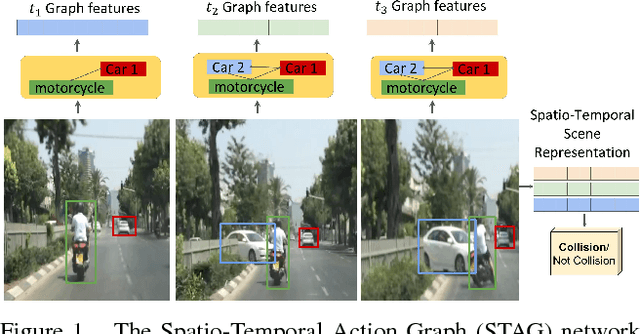
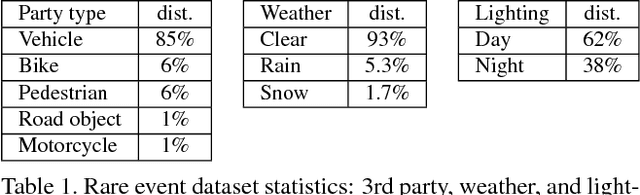
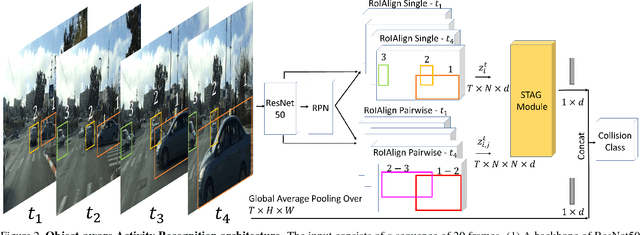
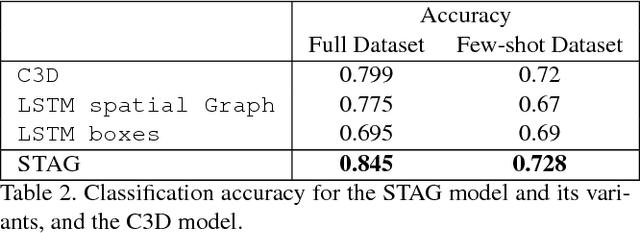
Events defined by the interaction of objects in a scene often are of critical importance, yet such events are typically rare and available labeled examples insufficient to train a conventional deep model that performs well across expected object appearances. Most deep learning activity recognition models focus on global context aggregation and do not explicitly consider object interactions inside the video, potentially overlooking important cues relevant to interpreting activity in the scene. In this paper, we show that a new model for explicit representation of object interactions significantly improves deep video activity classification for driving collision detection. We propose a Spatio-Temporal Action Graph (STAG) network, which incorporates spatial and temporal relations of objects. The network is automatically learned from data, with a latent graph structure inferred for the task. As a benchmark to evaluate performance on collision detection tasks, we introduce a novel data set based on data obtained from real life driving collisions and near-collisions. This data set reflects the challenging task of detecting and classifying accidents in a richly varying but yet highly constrained setting, that is very relevant to the evaluation of autonomous driving and alerting systems. Our experiments confirm that our STAG model offers significantly improved results for collision activity classification.