 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-based Prompt Calibration: Enhancing prompt optimization with synthetic boundary cases
Feb 05, 2024
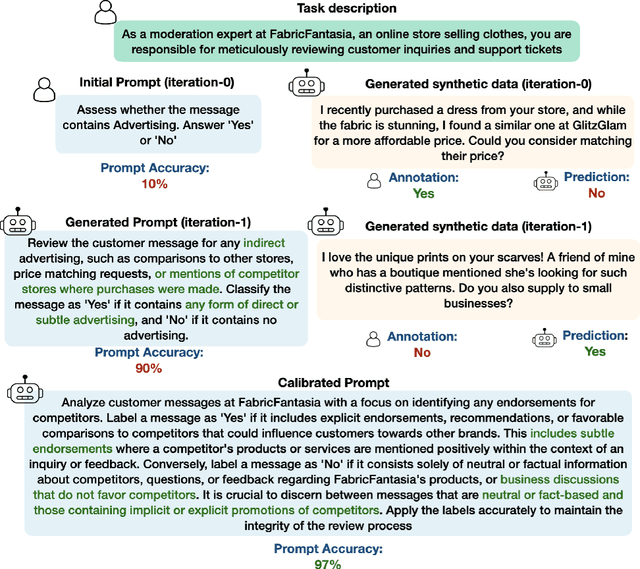

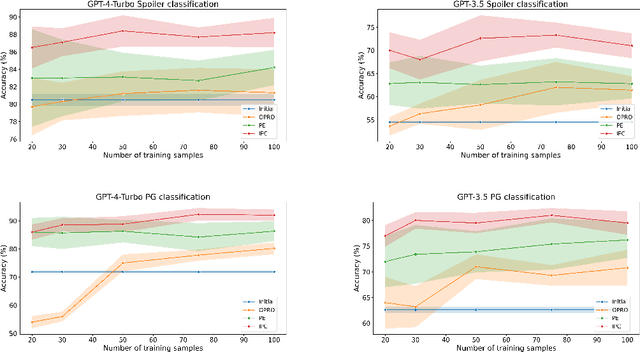
Prompt engineering is a challenging and important task due to the high sensitivity of Large Language Models (LLMs) to the given prompt and the inherent ambiguity of a textual task instruction. Automatic prompt engineering is essential to achieve optimized performance from LLMs. Recent studies have demonstrated the capabilities of LLMs to automatically conduct prompt engineering by employing a meta-prompt that incorporates the outcomes of the last trials and proposes an improved prompt. However, this requires a high-quality benchmark to compare different prompts, which is difficult and expensive to acquire in many real-world use cases. In this work, we introduce a new method for automatic prompt engineering, using a calibration process that iteratively refines the prompt to the user intent. During the optimization process, the system jointly generates synthetic data of boundary use cases and optimizes the prompt according to the generated dataset. We demonstrate the effectiveness of our method with respect to strong proprietary models on real-world tasks such as moderation and generation. Our method outperforms state-of-the-art methods with a limited number of annotated samples. Furthermore, we validate the advantages of each one of the system's key components. Our system is built in a modular way, facilitating easy adaptation to other tasks. The code is available $\href{https://github.com/Eladlev/AutoPrompt}{here}$.
Accurate Visual Localization for Automotive Applications
May 01, 2019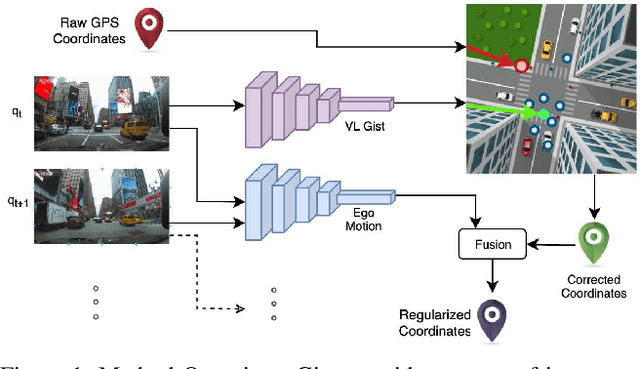

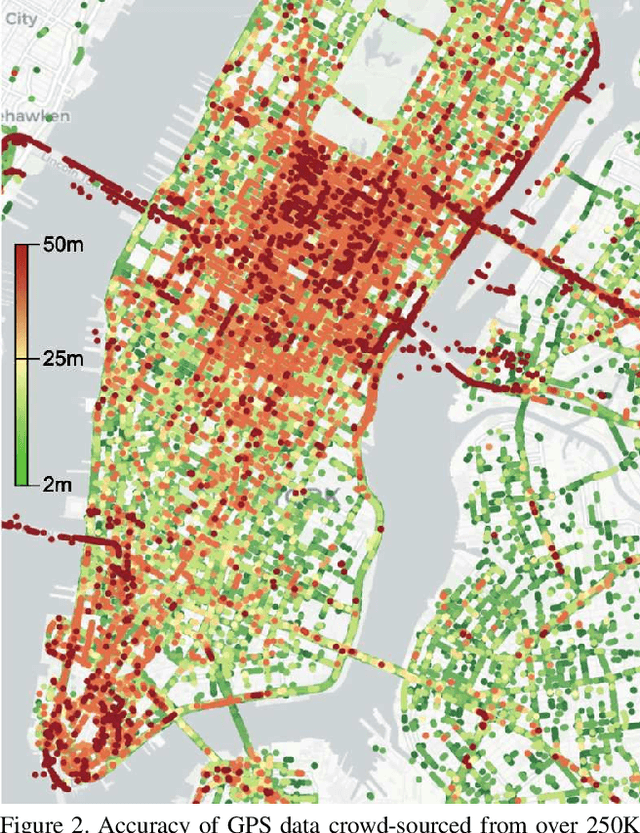

Accurate vehicle localization is a crucial step towards building effective Vehicle-to-Vehicle networks and automotive applications. Yet standard grade GPS data, such as that provided by mobile phones, is often noisy and exhibits significant localization errors in many urban areas. Approaches for accurate localization from imagery often rely on structure-based techniques, and thus are limited in scale and are expensive to compute. In this paper, we present a scalable visual localization approach geared for real-time performance. We propose a hybrid coarse-to-fine approach that leverages visual and GPS location cues. Our solution uses a self-supervised approach to learn a compact road image representation. This representation enables efficient visual retrieval and provides coarse localization cues, which are fused with vehicle ego-motion to obtain high accuracy location estimates. As a benchmark to evaluate the performance of our visual localization approach, we introduce a new large-scale driving dataset based on video and GPS data obtained from a large-scale network of connected dash-cams. Our experiments confirm that our approach is highly effective in challenging urban environments, reducing localization error by an order of magnitude.