 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntellAgent: A Multi-Agent Framework for Evaluating Conversational AI Systems
Jan 19, 2025Large Language Models (LLMs) are transforming artificial intelligence, evolving into task-oriented systems capable of autonomous planning and execution. One of the primary applications of LLMs is conversational AI systems, which must navigate multi-turn dialogues, integrate domain-specific APIs, and adhere to strict policy constraints. However, evaluating these agents remains a significant challenge, as traditional methods fail to capture the complexity and variability of real-world interactions. We introduce IntellAgent, a scalable, open-source multi-agent framework designed to evaluate conversational AI systems comprehensively. IntellAgent automates the creation of diverse, synthetic benchmarks by combining policy-driven graph modeling, realistic event generation, and interactive user-agent simulations. This innovative approach provides fine-grained diagnostics, addressing the limitations of static and manually curated benchmarks with coarse-grained metrics. IntellAgent represents a paradigm shift in evaluating conversational AI. By simulating realistic, multi-policy scenarios across varying levels of complexity, IntellAgent captures the nuanced interplay of agent capabilities and policy constraints. Unlike traditional methods, it employs a graph-based policy model to represent relationships, likelihoods, and complexities of policy interactions, enabling highly detailed diagnostics. IntellAgent also identifies critical performance gaps, offering actionable insights for targeted optimization. Its modular, open-source design supports seamless integration of new domains, policies, and APIs, fostering reproducibility and community collaboration. Our findings demonstrate that IntellAgent serves as an effective framework for advancing conversational AI by addressing challenges in bridging research and deployment. The framework is available at https://github.com/plurai-ai/intellagent
Accurate Visual Localization for Automotive Applications
May 01, 2019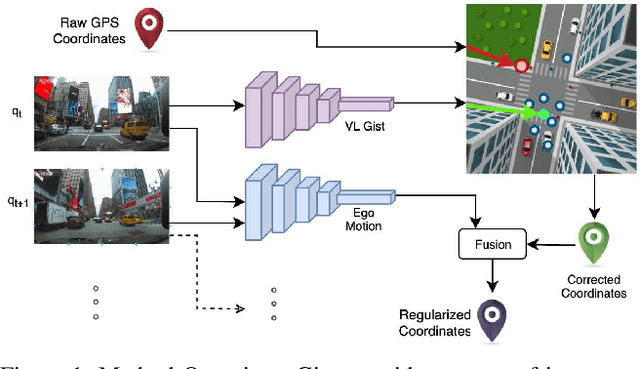

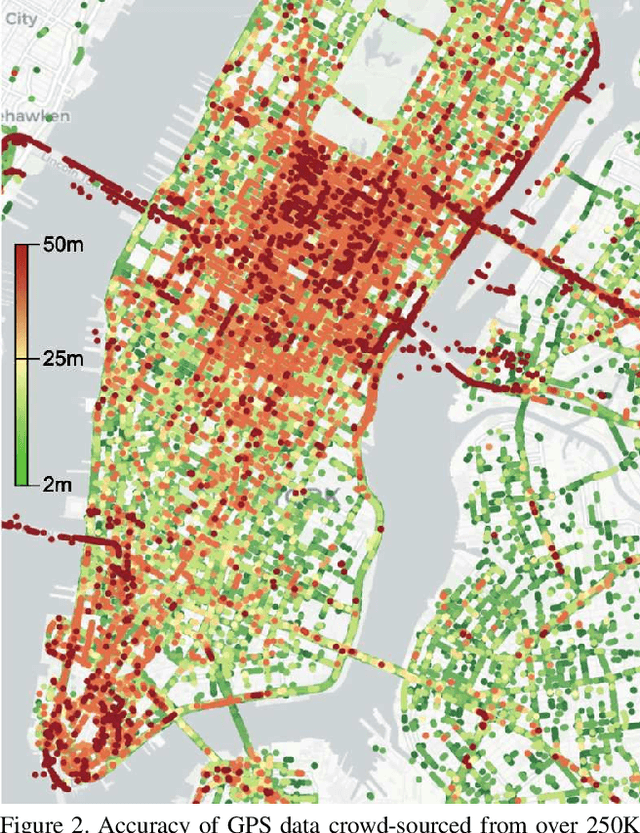

Accurate vehicle localization is a crucial step towards building effective Vehicle-to-Vehicle networks and automotive applications. Yet standard grade GPS data, such as that provided by mobile phones, is often noisy and exhibits significant localization errors in many urban areas. Approaches for accurate localization from imagery often rely on structure-based techniques, and thus are limited in scale and are expensive to compute. In this paper, we present a scalable visual localization approach geared for real-time performance. We propose a hybrid coarse-to-fine approach that leverages visual and GPS location cues. Our solution uses a self-supervised approach to learn a compact road image representation. This representation enables efficient visual retrieval and provides coarse localization cues, which are fused with vehicle ego-motion to obtain high accuracy location estimates. As a benchmark to evaluate the performance of our visual localization approach, we introduce a new large-scale driving dataset based on video and GPS data obtained from a large-scale network of connected dash-cams. Our experiments confirm that our approach is highly effective in challenging urban environments, reducing localization error by an order of magnitude.