 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-based Prompt Calibration: Enhancing prompt optimization with synthetic boundary cases
Feb 05, 2024
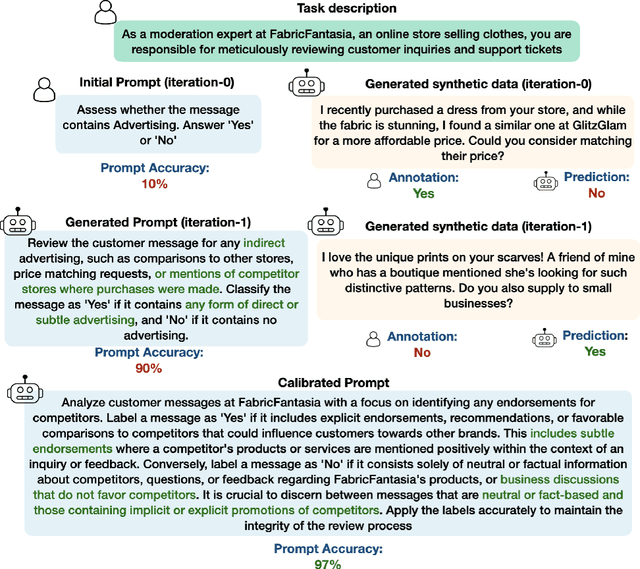

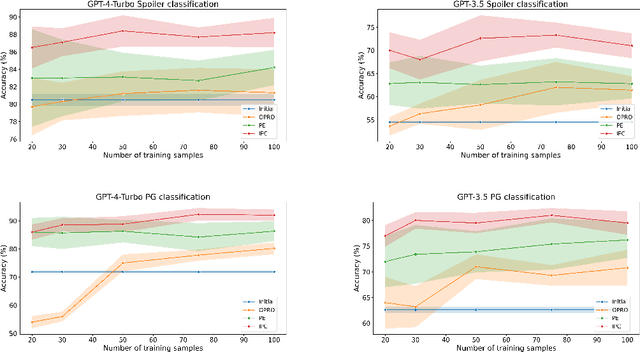
Prompt engineering is a challenging and important task due to the high sensitivity of Large Language Models (LLMs) to the given prompt and the inherent ambiguity of a textual task instruction. Automatic prompt engineering is essential to achieve optimized performance from LLMs. Recent studies have demonstrated the capabilities of LLMs to automatically conduct prompt engineering by employing a meta-prompt that incorporates the outcomes of the last trials and proposes an improved prompt. However, this requires a high-quality benchmark to compare different prompts, which is difficult and expensive to acquire in many real-world use cases. In this work, we introduce a new method for automatic prompt engineering, using a calibration process that iteratively refines the prompt to the user intent. During the optimization process, the system jointly generates synthetic data of boundary use cases and optimizes the prompt according to the generated dataset. We demonstrate the effectiveness of our method with respect to strong proprietary models on real-world tasks such as moderation and generation. Our method outperforms state-of-the-art methods with a limited number of annotated samples. Furthermore, we validate the advantages of each one of the system's key components. Our system is built in a modular way, facilitating easy adaptation to other tasks. The code is available $\href{https://github.com/Eladlev/AutoPrompt}{here}$.
DLT: Conditioned layout generation with Joint Discrete-Continuous Diffusion Layout Transformer
Mar 07, 2023Generating visual layouts is an essential ingredient of graphic design. The ability to condition layout generation on a partial subset of component attributes is critical to real-world applications that involve user interaction. Recently, diffusion models have demonstrated high-quality generative performances in various domains. However, it is unclear how to apply diffusion models to the natural representation of layouts which consists of a mix of discrete (class) and continuous (location, size) attributes. To address the conditioning layout generation problem, we introduce DLT, a joint discrete-continuous diffusion model. DLT is a transformer-based model which has a flexible conditioning mechanism that allows for conditioning on any given subset of all the layout component classes, locations, and sizes. Our method outperforms state-of-the-art generative models on various layout generation datasets with respect to different metrics and conditioning settings. Additionally, we validate the effectiveness of our proposed conditioning mechanism and the joint continuous-diffusion process. This joint process can be incorporated into a wide range of mixed discrete-continuous generative tasks.
Dynamic-Deep: ECG Task-Aware Compression
May 30, 2021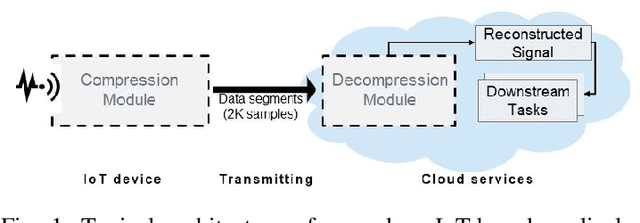
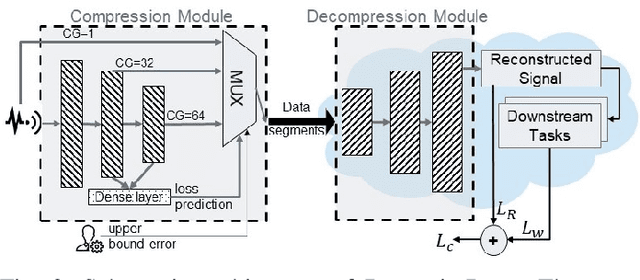
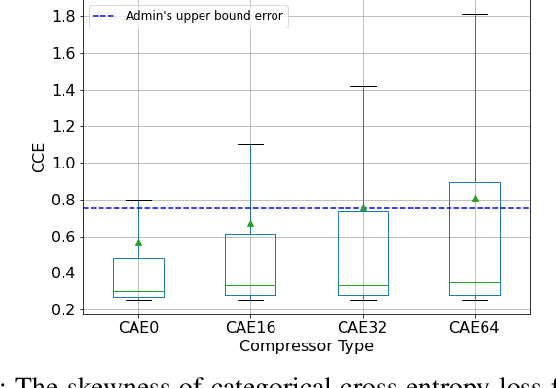
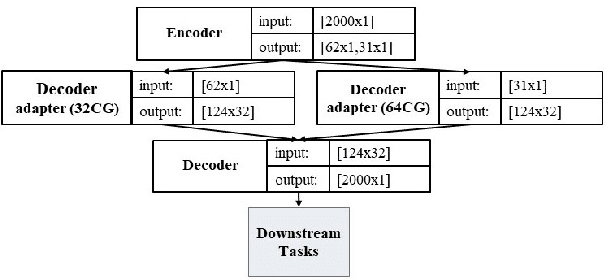
Monitoring medical data, e.g., Electrocardiogram (ECG) signals, is a common application of Internet of Things (IoT) devices. Compression methods are often applied on the massive amounts of sensor data generated before sending it to the Cloud to reduce storage and delivery costs. A lossy compression provides high compression gain (CG) but may reduce the performance of an ECG application (downstream task) due to information loss. Previous works on ECG monitoring focus either on optimizing the signal reconstruction or the task's performance. Instead, we advocate a lossy compression solution that allows configuring a desired performance level on the downstream tasks while maintaining an optimized CG. We propose Dynamic-Deep, a task-aware compression that uses convolutional autoencoders. The compression level is dynamically selected to yield an optimized compression without violating tasks' performance requirements. We conduct an extensive evaluation of our approach on common ECG datasets using two popular ECG applications, which includes heart rate (HR) arrhythmia classification. We demonstrate that Dynamic-Deep improves HR classification F1-score by a factor of 3 and increases CG by up to 83% compared to the previous state-of-the-art (autoencoder-based) compressor. Additionally, Dynamic-Deep has a 67% lower memory footprint. Analyzing Dynamic-Deep on the Google Cloud Platform, we observe a 97% reduction in cloud costs compared to a no compression solution. To the best of our knowledge, Dynamic-Deep is the first proposal to focus on balancing the need for high performance of cloud-based downstream tasks and the desire to achieve optimized compression in IoT ECG monitoring settings.
Accurate Visual Localization for Automotive Applications
May 01, 2019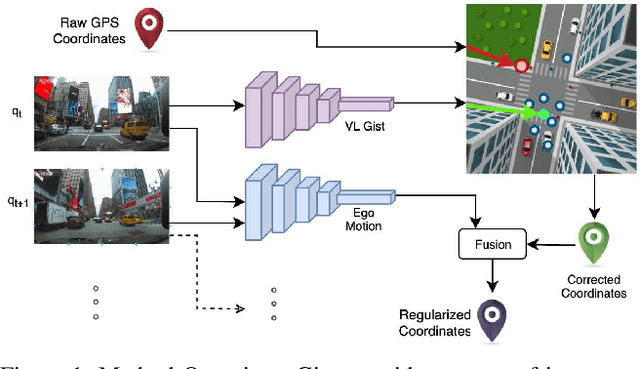

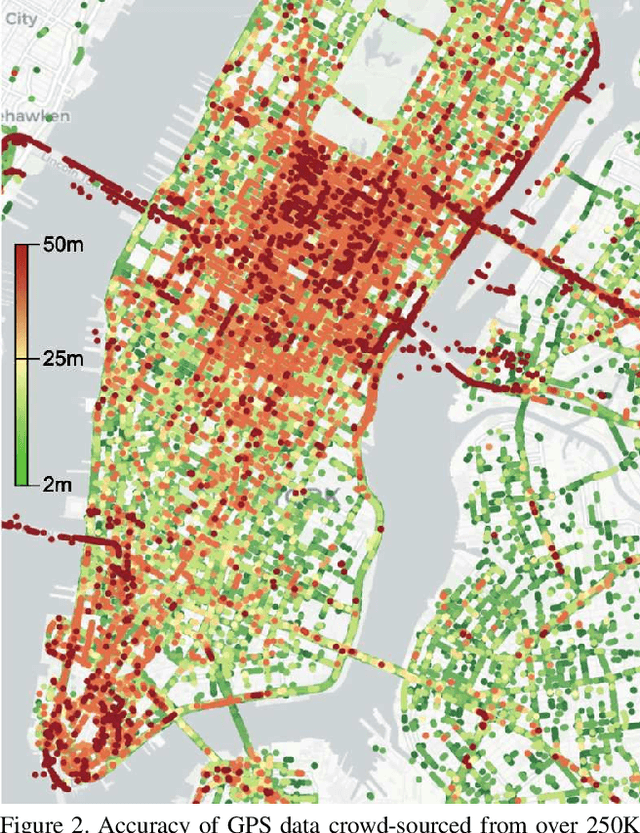

Accurate vehicle localization is a crucial step towards building effective Vehicle-to-Vehicle networks and automotive applications. Yet standard grade GPS data, such as that provided by mobile phones, is often noisy and exhibits significant localization errors in many urban areas. Approaches for accurate localization from imagery often rely on structure-based techniques, and thus are limited in scale and are expensive to compute. In this paper, we present a scalable visual localization approach geared for real-time performance. We propose a hybrid coarse-to-fine approach that leverages visual and GPS location cues. Our solution uses a self-supervised approach to learn a compact road image representation. This representation enables efficient visual retrieval and provides coarse localization cues, which are fused with vehicle ego-motion to obtain high accuracy location estimates. As a benchmark to evaluate the performance of our visual localization approach, we introduce a new large-scale driving dataset based on video and GPS data obtained from a large-scale network of connected dash-cams. Our experiments confirm that our approach is highly effective in challenging urban environments, reducing localization error by an order of magnitude.
Classifying Collisions with Spatio-Temporal Action Graph Networks
Dec 04, 2018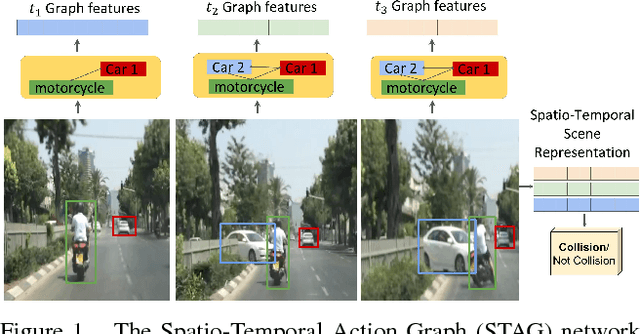
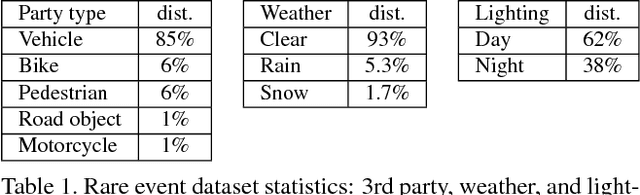
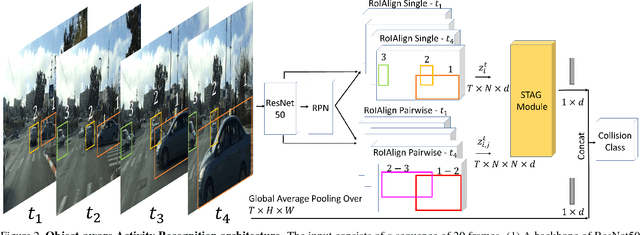
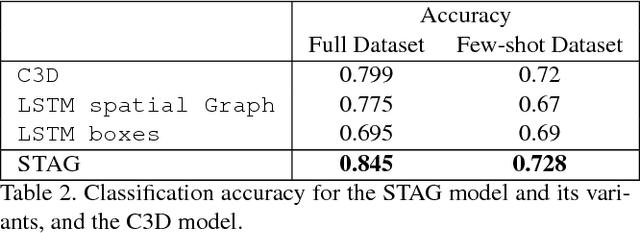
Events defined by the interaction of objects in a scene often are of critical importance, yet such events are typically rare and available labeled examples insufficient to train a conventional deep model that performs well across expected object appearances. Most deep learning activity recognition models focus on global context aggregation and do not explicitly consider object interactions inside the video, potentially overlooking important cues relevant to interpreting activity in the scene. In this paper, we show that a new model for explicit representation of object interactions significantly improves deep video activity classification for driving collision detection. We propose a Spatio-Temporal Action Graph (STAG) network, which incorporates spatial and temporal relations of objects. The network is automatically learned from data, with a latent graph structure inferred for the task. As a benchmark to evaluate performance on collision detection tasks, we introduce a novel data set based on data obtained from real life driving collisions and near-collisions. This data set reflects the challenging task of detecting and classifying accidents in a richly varying but yet highly constrained setting, that is very relevant to the evaluation of autonomous driving and alerting systems. Our experiments confirm that our STAG model offers significantly improved results for collision activity classification.