 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-based Prompt Calibration: Enhancing prompt optimization with synthetic boundary cases
Paper and Code

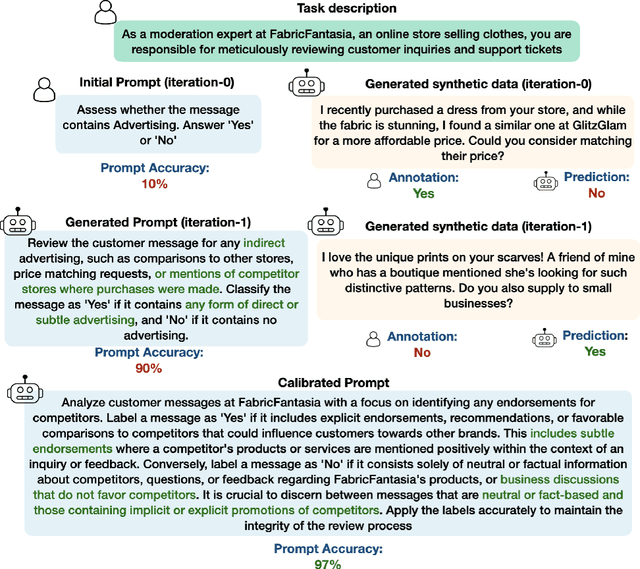

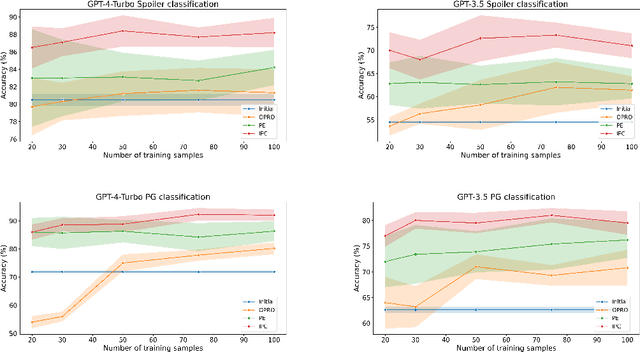
Prompt engineering is a challenging and important task due to the high sensitivity of Large Language Models (LLMs) to the given prompt and the inherent ambiguity of a textual task instruction. Automatic prompt engineering is essential to achieve optimized performance from LLMs. Recent studies have demonstrated the capabilities of LLMs to automatically conduct prompt engineering by employing a meta-prompt that incorporates the outcomes of the last trials and proposes an improved prompt. However, this requires a high-quality benchmark to compare different prompts, which is difficult and expensive to acquire in many real-world use cases. In this work, we introduce a new method for automatic prompt engineering, using a calibration process that iteratively refines the prompt to the user intent. During the optimization process, the system jointly generates synthetic data of boundary use cases and optimizes the prompt according to the generated dataset. We demonstrate the effectiveness of our method with respect to strong proprietary models on real-world tasks such as moderation and generation. Our method outperforms state-of-the-art methods with a limited number of annotated samples. Furthermore, we validate the advantages of each one of the system's key components. Our system is built in a modular way, facilitating easy adaptation to other tasks. The code is available $\href{https://github.com/Eladlev/AutoPrompt}{here}$.