 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Visual Pre-training for Motor Control
Paper and Code
Mar 11, 2022
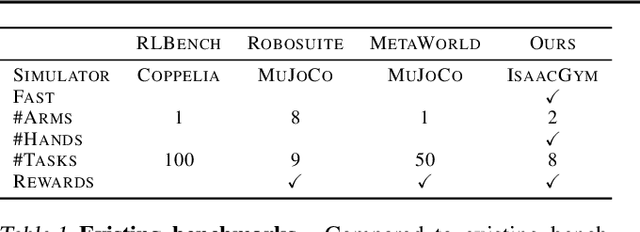
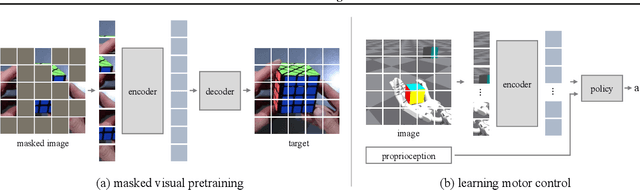

This paper shows that self-supervised visual pre-training from real-world images is effective for learning motor control tasks from pixels. We first train the visual representations by masked modeling of natural images. We then freeze the visual encoder and train neural network controllers on top with reinforcement learning. We do not perform any task-specific fine-tuning of the encoder; the same visual representations are used for all motor control tasks. To the best of our knowledge, this is the first self-supervised model to exploit real-world images at scale for motor control. To accelerate progress in learning from pixels, we contribute a benchmark suite of hand-designed tasks varying in movements, scenes, and robots. Without relying on labels, state-estimation, or expert demonstrations, we consistently outperform supervised encoders by up to 80% absolute success rate, sometimes even matching the oracle state performance. We also find that in-the-wild images, e.g., from YouTube or Egocentric videos, lead to better visual representations for various manipulation tasks than ImageNet images.