 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning in Deep Networks: an Analysis of the Last Layer
Paper and Code
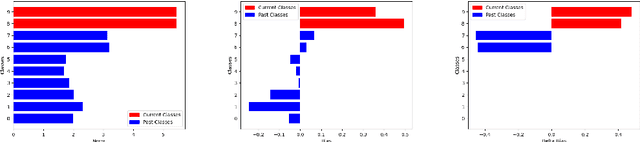
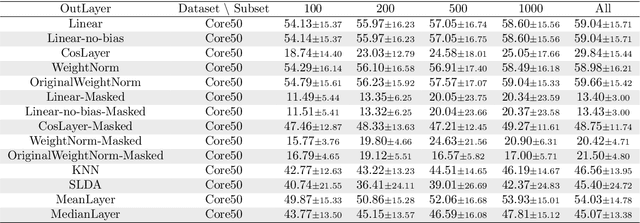


We study how different output layer types of a deep neural network learn and forget in continual learning settings. We describe the three factors affecting catastrophic forgetting in the output layer: (1) weights modifications, (2) interferences, and (3) projection drift. Our goal is to provide more insights into how different types of output layers can address (1) and (2). We also propose potential solutions and evaluate them on several benchmarks. We show that the best-performing output layer type depends on the data distribution drifts or the amount of data available. In particular, in some cases where a standard linear layer would fail, it is sufficient to change the parametrization and get significantly better performance while still training with SGD. Our results and analysis shed light on the dynamics of the output layer in continual learning scenarios and help select the best-suited output layer for a given scenario.