 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Feature Selection: Spurious Features in Continual Learning
Paper and Code


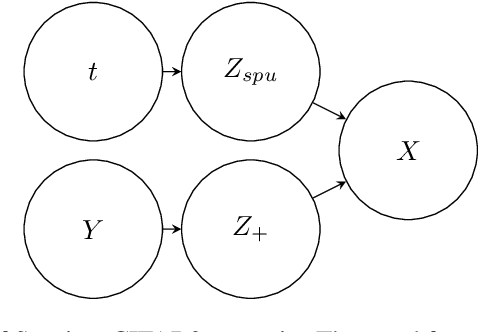

Continual Learning (CL) is the research field addressing learning settings where the data distribution is not static. This paper studies spurious features' influence on continual learning algorithms. Indeed, we show that learning algorithms solve tasks by overfitting features that are not generalizable. To better understand these phenomena and their impact, we propose a domain incremental scenario that we study through various out-of-distribution generalizations and continual learning algorithms. The experiments of this paper show that continual learning algorithms face two related challenges: (1) the spurious features challenge: some features are well correlated with labels in train data but not in test data due to a covariate shift between train and test. (2) the local spurious features challenge: some features correlate well with labels within a task but not within the whole task sequence. The challenge is to learn general features that are neither spurious (in general) nor locally spurious. We prove that the latter is a major cause of performance decrease in continual learning along with catastrophic forgetting. Our results indicate that the best solution to overcome the feature selection problems varies depending on the correlation between spurious features (SFs) and labels. The vanilla replay approach seems to be a powerful approach to deal with SFs, which could explain its good performance in the continual learning literature. This paper presents a different way of understanding performance decrease in continual learning by describing the influence of spurious/local spurious features.