 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Deep Learning Methods in an Application-Oriented Context
Jul 12, 2022



Abstract knowledge is deeply grounded in many computer-based applications. An important research area of Artificial Intelligence (AI) deals with the automatic derivation of knowledge from data. Machine learning offers the according algorithms. One area of research focuses on the development of biologically inspired learning algorithms. The respective machine learning methods are based on neurological concepts so that they can systematically derive knowledge from data and store it. One type of machine learning algorithms that can be categorized as "deep learning" model is referred to as Deep Neural Networks (DNNs). DNNs consist of multiple artificial neurons arranged in layers that are trained by using the backpropagation algorithm. These deep learning methods exhibit amazing capabilities for inferring and storing complex knowledge from high-dimensional data. However, DNNs are affected by a problem that prevents new knowledge from being added to an existing base. The ability to continuously accumulate knowledge is an important factor that contributed to evolution and is therefore a prerequisite for the development of strong AIs. The so-called "catastrophic forgetting" (CF) effect causes DNNs to immediately loose already derived knowledge after a few training iterations on a new data distribution. Only an energetically expensive retraining with the joint data distribution of past and new data enables the abstraction of the entire new set of knowledge. In order to counteract the effect, various techniques have been and are still being developed with the goal to mitigate or even solve the CF problem. These published CF avoidance studies usually imply the effectiveness of their approaches for various continual learning tasks. This dissertation is set in the context of continual machine learning with deep learning methods. The first part deals with the development of an ...
Continual Learning with Fully Probabilistic Models
Apr 19, 2021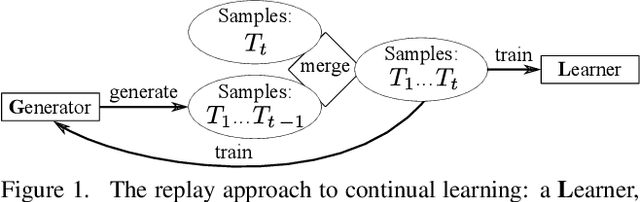

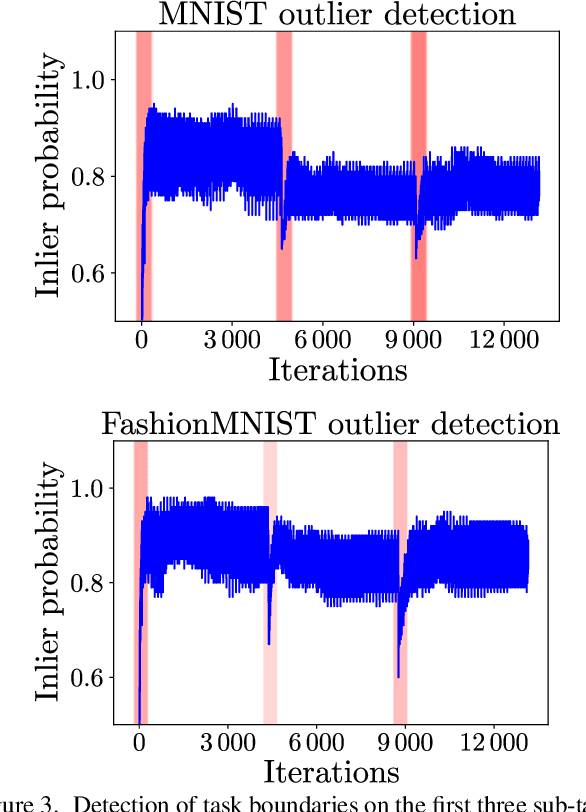
We present an approach for continual learning (CL) that is based on fully probabilistic (or generative) models of machine learning. In contrast to, e.g., GANs that are "generative" in the sense that they can generate samples, fully probabilistic models aim at modeling the data distribution directly. Consequently, they provide functionalities that are highly relevant for continual learning, such as density estimation (outlier detection) and sample generation. As a concrete realization of generative continual learning, we propose Gaussian Mixture Replay (GMR). GMR is a pseudo-rehearsal approach using a Gaussian Mixture Model (GMM) instance for both generator and classifier functionalities. Relying on the MNIST, FashionMNIST and Devanagari benchmarks, we first demonstrate unsupervised task boundary detection by GMM density estimation, which we also use to reject untypical generated samples. In addition, we show that GMR is capable of class-conditional sampling in the way of a cGAN. Lastly, we verify that GMR, despite its simple structure, achieves state-of-the-art performance on common class-incremental learning problems at very competitive time and memory complexity.
Image Modeling with Deep Convolutional Gaussian Mixture Models
Apr 19, 2021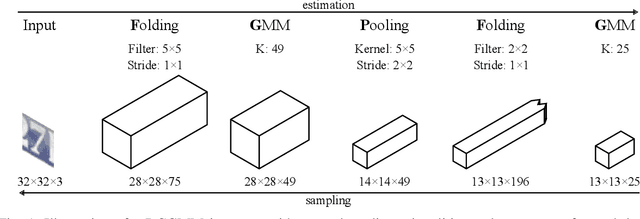

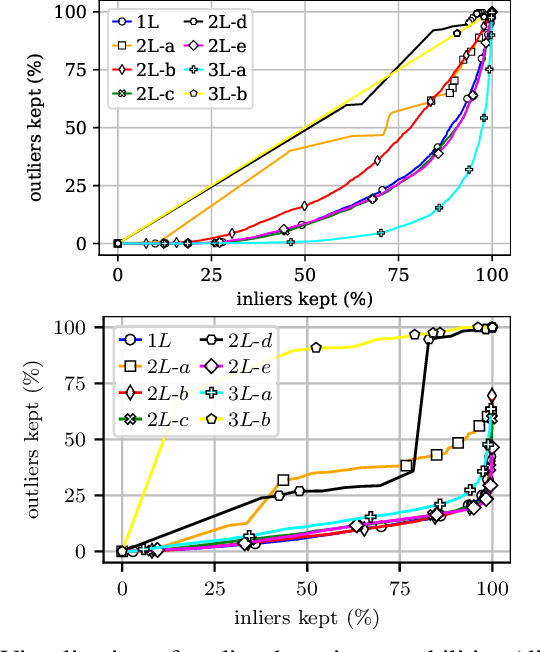

In this conceptual work, we present Deep Convolutional Gaussian Mixture Models (DCGMMs): a new formulation of deep hierarchical Gaussian Mixture Models (GMMs) that is particularly suitable for describing and generating images. Vanilla (i.e., flat) GMMs require a very large number of components to describe images well, leading to long training times and memory issues. DCGMMs avoid this by a stacked architecture of multiple GMM layers, linked by convolution and pooling operations. This allows to exploit the compositionality of images in a similar way as deep CNNs do. DCGMMs can be trained end-to-end by Stochastic Gradient Descent. This sets them apart from vanilla GMMs which are trained by Expectation-Maximization, requiring a prior k-means initialization which is infeasible in a layered structure. For generating sharp images with DCGMMs, we introduce a new gradient-based technique for sampling through non-invertible operations like convolution and pooling. Based on the MNIST and FashionMNIST datasets, we validate the DCGMMs model by demonstrating its superiority over flat GMMs for clustering, sampling and outlier detection.
Overcoming Catastrophic Forgetting with Gaussian Mixture Replay
Apr 19, 2021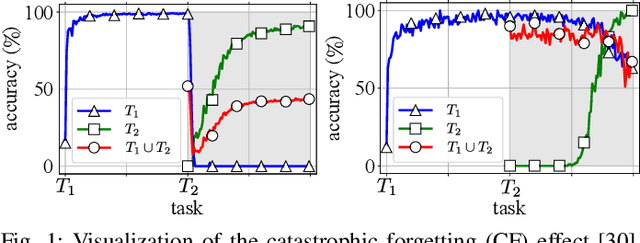

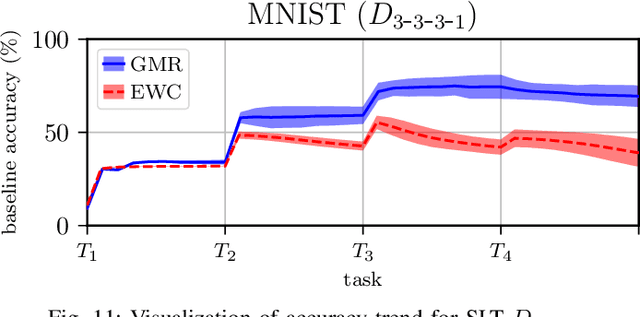
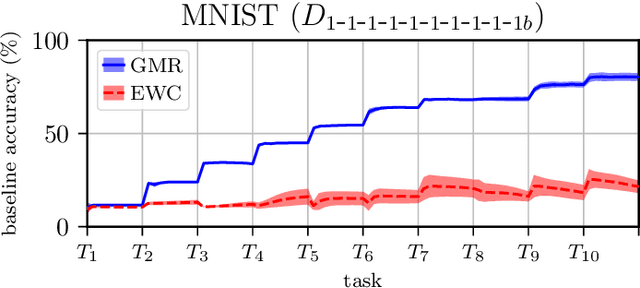
We present Gaussian Mixture Replay (GMR), a rehearsal-based approach for continual learning (CL) based on Gaussian Mixture Models (GMM). CL approaches are intended to tackle the problem of catastrophic forgetting (CF), which occurs for Deep Neural Networks (DNNs) when sequentially training them on successive sub-tasks. GMR mitigates CF by generating samples from previous tasks and merging them with current training data. GMMs serve several purposes here: sample generation, density estimation (e.g., for detecting outliers or recognizing task boundaries) and providing a high-level feature representation for classification. GMR has several conceptual advantages over existing replay-based CL approaches. First of all, GMR achieves sample generation, classification and density estimation in a single network structure with strongly reduced memory requirements. Secondly, it can be trained at constant time complexity w.r.t. the number of sub-tasks, making it particularly suitable for life-long learning. Furthermore, GMR minimizes a differentiable loss function and seems to avoid mode collapse. In addition, task boundaries can be detected by applying GMM density estimation. Lastly, GMR does not require access to sub-tasks lying in the future for hyper-parameter tuning, allowing CL under real-world constraints. We evaluate GMR on multiple image datasets, which are divided into class-disjoint sub-tasks.
A Rigorous Link Between Self-Organizing Maps and Gaussian Mixture Models
Sep 24, 2020
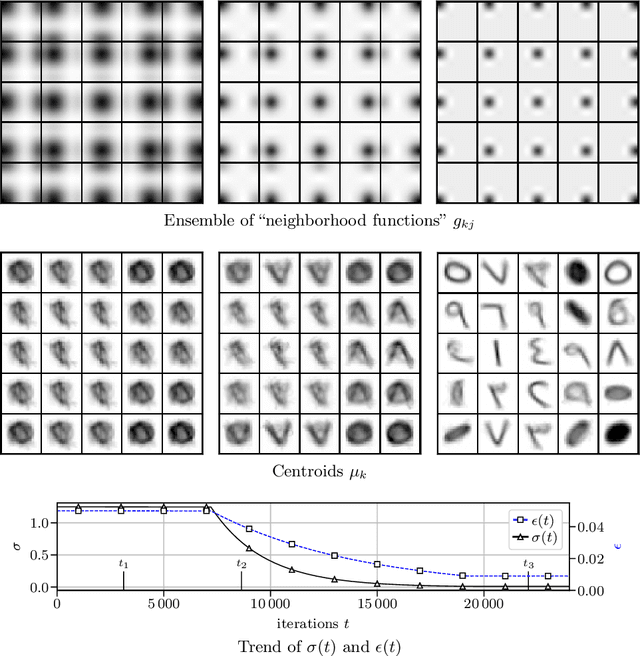
This work presents a mathematical treatment of the relation between Self-Organizing Maps (SOMs) and Gaussian Mixture Models (GMMs). We show that energy-based SOM models can be interpreted as performing gradient descent, minimizing an approximation to the GMM log-likelihood that is particularly valid for high data dimensionalities. The SOM-like decrease of the neighborhood radius can be understood as an annealing procedure ensuring that gradient descent does not get stuck in undesirable local minima. This link allows to treat SOMs as generative probabilistic models, giving a formal justification for using SOMs, e.g., to detect outliers, or for sampling.
Gradient-based training of Gaussian Mixture Models in High-Dimensional Spaces
Dec 18, 2019
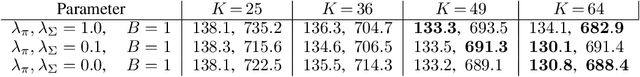


We present an approach for efficiently training Gaussian Mixture Models (GMMs) with Stochastic Gradient Descent (SGD) on large amounts of high-dimensional data (e.g., images). In such a scenario, SGD is strongly superior in terms of execution time and memory usage, although it is conceptually more complex than the traditional Expectation-Maximization (EM) algorithm. For enabling SGD training, we propose three novel ideas: First, we show that minimizing an upper bound to the GMM log likelihood instead of the full one is feasible and numerically much more stable way in high-dimensional spaces. Secondly, we propose a new annealing procedure that prevents SGD from converging to pathological local minima. We also propose an SGD-compatible simplification to the full GMM model based on local principal directions, which avoids excessive memory use in high-dimensional spaces due to quadratic growth of covariance matrices. Experiments on several standard image datasets show the validity of our approach, and we provide a publicly available TensorFlow implementation.
A Study of Deep Learning for Network Traffic Data Forecasting
Sep 12, 2019


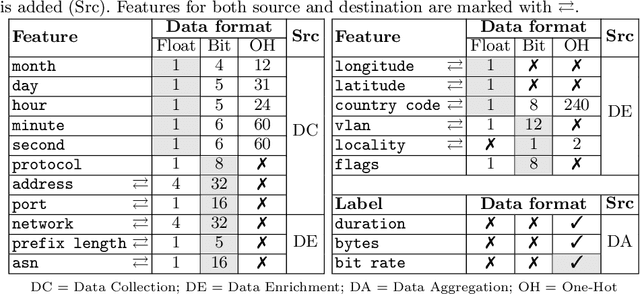
We present a study of deep learning applied to the domain of network traffic data forecasting. This is a very important ingredient for network traffic engineering, e.g., intelligent routing, which can optimize network performance, especially in large networks. In a nutshell, we wish to predict, in advance, the bit rate for a transmission, based on low-dimensional connection metadata ("flows") that is available whenever a communication is initiated. Our study has several genuinely new points: First, it is performed on a large dataset (~50 million flows), which requires a new training scheme that operates on successive blocks of data since the whole dataset is too large for in-memory processing. Additionally, we are the first to propose and perform a more fine-grained prediction that distinguishes between low, medium and high bit rates instead of just "mice" and "elephant" flows. Lastly, we apply state-of-the-art visualization and clustering techniques to flow data and show that visualizations are insightful despite the heterogeneous and non-metric nature of the data. We developed a processing pipeline to handle the highly non-trivial acquisition process and allow for proper data preprocessing to be able to apply DNNs to network traffic data. We conduct DNN hyper-parameter optimization as well as feature selection experiments, which clearly show that fine-grained network traffic forecasting is feasible, and that domain-dependent data enrichment and augmentation strategies can improve results. An outlook about the fundamental challenges presented by network traffic analysis (high data throughput, unbalanced and dynamic classes, changing statistics, outlier detection) concludes the article.