 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based training of Gaussian Mixture Models in High-Dimensional Spaces
Paper and Code

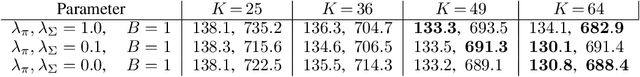


We present an approach for efficiently training Gaussian Mixture Models (GMMs) with Stochastic Gradient Descent (SGD) on large amounts of high-dimensional data (e.g., images). In such a scenario, SGD is strongly superior in terms of execution time and memory usage, although it is conceptually more complex than the traditional Expectation-Maximization (EM) algorithm. For enabling SGD training, we propose three novel ideas: First, we show that minimizing an upper bound to the GMM log likelihood instead of the full one is feasible and numerically much more stable way in high-dimensional spaces. Secondly, we propose a new annealing procedure that prevents SGD from converging to pathological local minima. We also propose an SGD-compatible simplification to the full GMM model based on local principal directions, which avoids excessive memory use in high-dimensional spaces due to quadratic growth of covariance matrices. Experiments on several standard image datasets show the validity of our approach, and we provide a publicly available TensorFlow implementation.