 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroevolution Neural Architecture Search for Evolving RNNs in Stock Return Prediction and Portfolio Trading
Oct 22, 2024Stock return forecasting is a major component of numerous finance applications. Predicted stock returns can be incorporated into portfolio trading algorithms to make informed buy or sell decisions which can optimize returns. In such portfolio trading applications, the predictive performance of a time series forecasting model is crucial. In this work, we propose the use of the Evolutionary eXploration of Augmenting Memory Models (EXAMM) algorithm to progressively evolve recurrent neural networks (RNNs) for stock return predictions. RNNs are evolved independently for each stocks and portfolio trading decisions are made based on the predicted stock returns. The portfolio used for testing consists of the 30 companies in the Dow-Jones Index (DJI) with each stock have the same weight. Results show that using these evolved RNNs and a simple daily long-short strategy can generate higher returns than both the DJI index and the S&P 500 Index for both 2022 (bear market) and 2023 (bull market).
Minimally Supervised Topological Projections of Self-Organizing Maps for Phase of Flight Identification
Feb 17, 2024



Identifying phases of flight is important in the field of general aviation, as knowing which phase of flight data is collected from aircraft flight data recorders can aid in the more effective detection of safety or hazardous events. General aviation flight data for phase of flight identification is usually per-second data, comes on a large scale, and is class imbalanced. It is expensive to manually label the data and training classification models usually faces class imbalance problems. This work investigates the use of a novel method for minimally supervised self-organizing maps (MS-SOMs) which utilize nearest neighbor majority votes in the SOM U-matrix for class estimation. Results show that the proposed method can reach or exceed a naive SOM approach which utilized a full data file of labeled data, with only 30 labeled datapoints per class. Additionally, the minimally supervised SOM is significantly more robust to the class imbalance of the phase of flight data. These results highlight how little data is required for effective phase of flight identification.
Minimally Supervised Learning using Topological Projections in Self-Organizing Maps
Jan 12, 2024



Parameter prediction is essential for many applications, facilitating insightful interpretation and decision-making. However, in many real life domains, such as power systems, medicine, and engineering, it can be very expensive to acquire ground truth labels for certain datasets as they may require extensive and expensive laboratory testing. In this work, we introduce a semi-supervised learning approach based on topological projections in self-organizing maps (SOMs), which significantly reduces the required number of labeled data points to perform parameter prediction, effectively exploiting information contained in large unlabeled datasets. Our proposed method first trains SOMs on unlabeled data and then a minimal number of available labeled data points are ultimately assigned to key best matching units (BMU). The values estimated for newly-encountered data points are computed utilizing the average of the $n$ closest labeled data points in the SOM's U-matrix in tandem with a topological shortest path distance calculation scheme. Our results indicate that the proposed semi-supervised model significantly outperforms traditional regression techniques, including linear and polynomial regression, Gaussian process regression, K-nearest neighbors, as well as various deep neural network models.
Online Evolutionary Neural Architecture Search for Multivariate Non-Stationary Time Series Forecasting
Feb 20, 2023



Time series forecasting (TSF) is one of the most important tasks in data science given the fact that accurate time series (TS) predictive models play a major role across a wide variety of domains including finance, transportation, health care, and power systems. Real-world utilization of machine learning (ML) typically involves (pre-)training models on collected, historical data and then applying them to unseen data points. However, in real-world applications, time series data streams are usually non-stationary and trained ML models usually, over time, face the problem of data or concept drift. To address this issue, models must be periodically retrained or redesigned, which takes significant human and computational resources. Additionally, historical data may not even exist to re-train or re-design model with. As a result, it is highly desirable that models are designed and trained in an online fashion. This work presents the Online NeuroEvolution-based Neural Architecture Search (ONE-NAS) algorithm, which is a novel neural architecture search method capable of automatically designing and dynamically training recurrent neural networks (RNNs) for online forecasting tasks. Without any pre-training, ONE-NAS utilizes populations of RNNs that are continuously updated with new network structures and weights in response to new multivariate input data. ONE-NAS is tested on real-world, large-scale multivariate wind turbine data as well as the univariate Dow Jones Industrial Average (DJIA) dataset. Results demonstrate that ONE-NAS outperforms traditional statistical time series forecasting methods, including online linear regression, fixed long short-term memory (LSTM) and gated recurrent unit (GRU) models trained online, as well as state-of-the-art, online ARIMA strategies.
ONE-NAS: An Online NeuroEvolution based Neural Architecture Search for Time Series Forecasting
Feb 27, 2022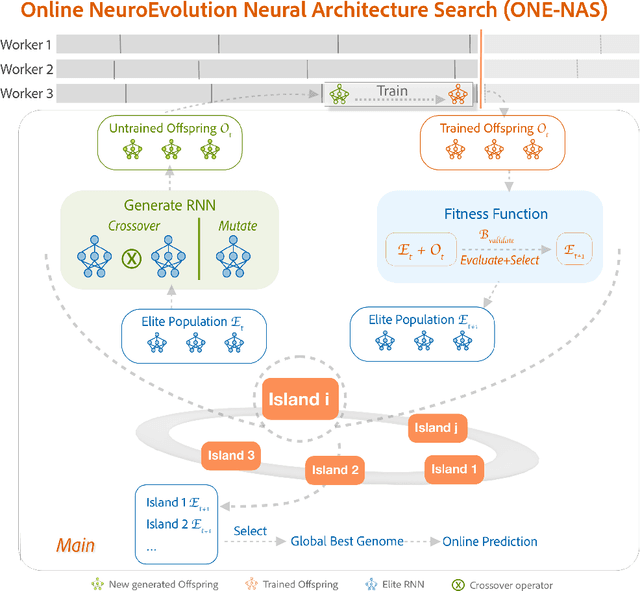
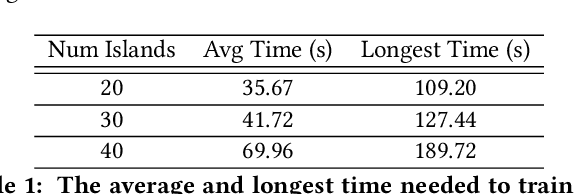

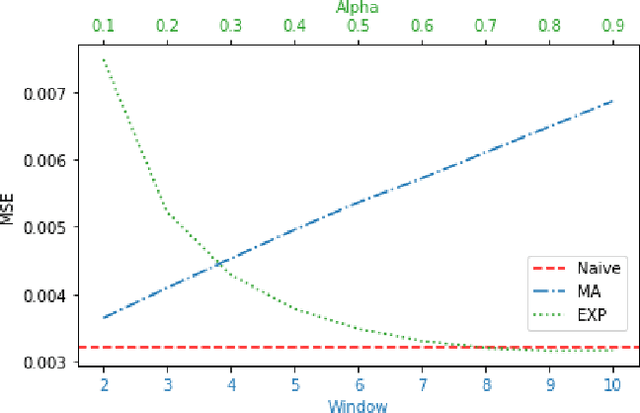
Time series forecasting (TSF) is one of the most important tasks in data science, as accurate time series (TS) predictions can drive and advance a wide variety of domains including finance, transportation, health care, and power systems. However, real-world utilization of machine learning (ML) models for TSF suffers due to pretrained models being able to learn and adapt to unpredictable patterns as previously unseen data arrives over longer time scales. To address this, models must be periodically retained or redesigned, which takes significant human and computational resources. This work presents the Online NeuroEvolution based Neural Architecture Search (ONE-NAS) algorithm, which to the authors' knowledge is the first neural architecture search algorithm capable of automatically designing and training new recurrent neural networks (RNNs) in an online setting. Without any pretraining, ONE-NAS utilizes populations of RNNs which are continuously updated with new network structures and weights in response to new multivariate input data. ONE-NAS is tested on real-world large-scale multivariate wind turbine data as well a univariate Dow Jones Industrial Average (DJIA) dataset, and is shown to outperform traditional statistical time series forecasting, including naive, moving average, and exponential smoothing methods, as well as state of the art online ARIMA strategies.
Continuous Ant-Based Neural Topology Search
Nov 21, 2020

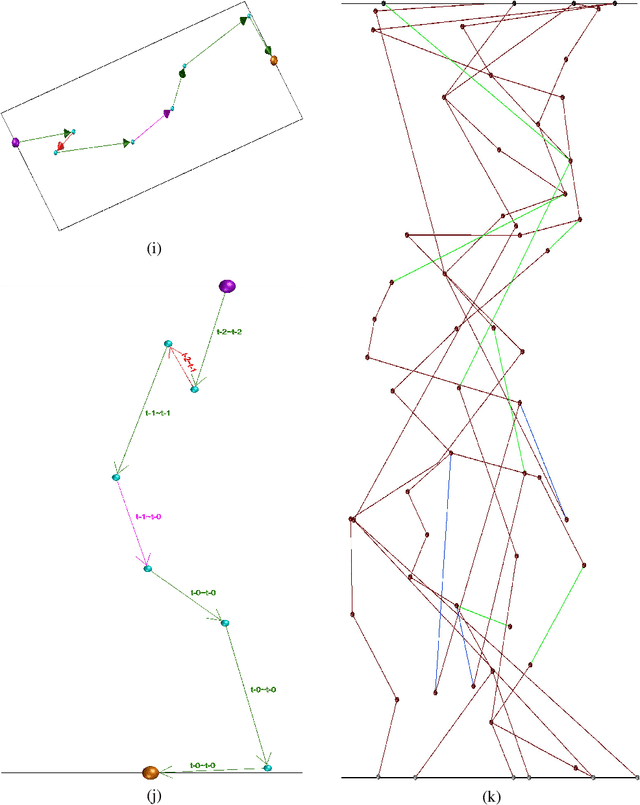
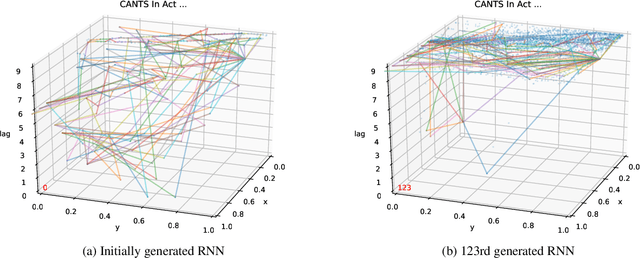
This work introduces a novel, nature-inspired neural architecture search (NAS) algorithm based on ant colony optimization, Continuous Ant-based Neural Topology Search (CANTS), which utilizes synthetic ants that move over a continuous search space based on the density and distribution of pheromones, is strongly inspired by how ants move in the real world. The paths taken by the ant agents through the search space are utilized to construct artificial neural networks (ANNs). This continuous search space allows CANTS to automate the design of ANNs of any size, removing a key limitation inherent to many current NAS algorithms that must operate within structures with a size predetermined by the user. CANTS employs a distributed asynchronous strategy which allows it to scale to large-scale high performance computing resources, works with a variety of recurrent memory cell structures, and makes use of a communal weight sharing strategy to reduce training time. The proposed procedure is evaluated on three real-world, time series prediction problems in the field of power systems and compared to two state-of-the-art algorithms. Results show that CANTS is able to provide improved or competitive results on all of these problems, while also being easier to use, requiring half the number of user-specified hyper-parameters.
An Experimental Study of Weight Initialization and Weight Inheritance Effects on Neuroevolution
Sep 26, 2020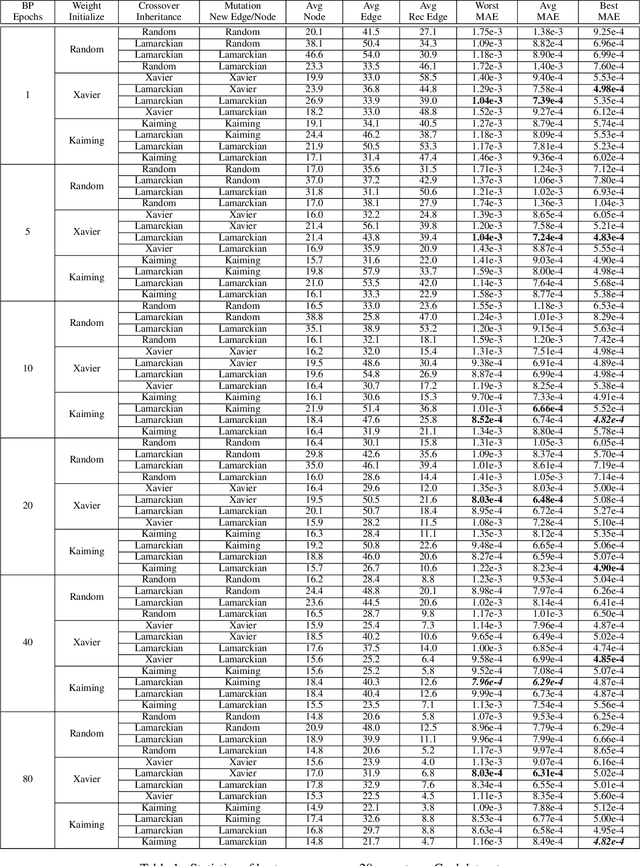
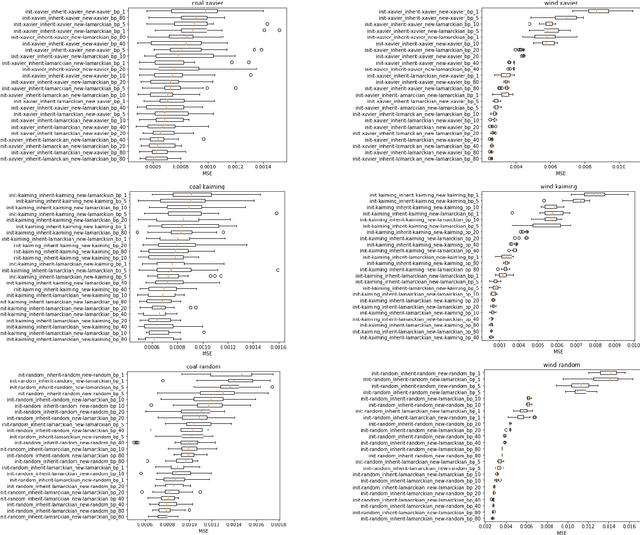
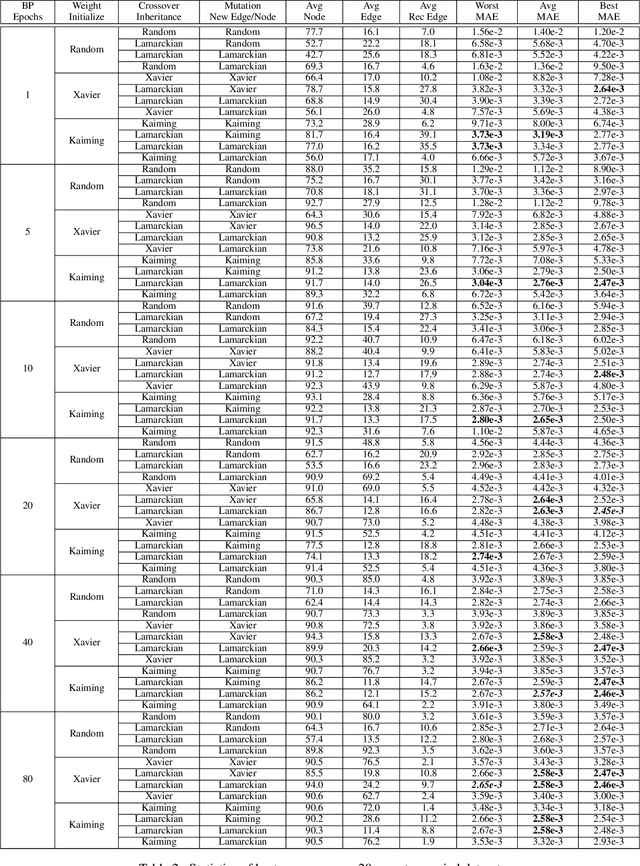
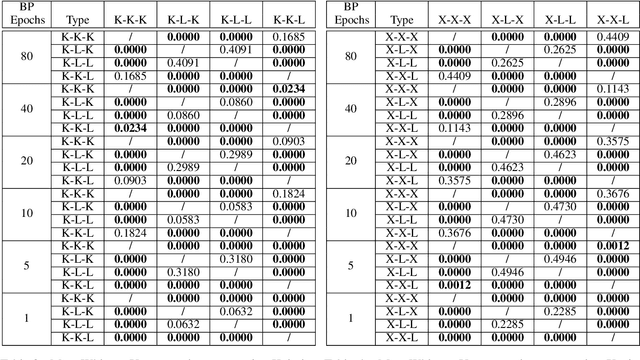
Weight initialization is critical in being able to successfully train artificial neural networks (ANNs), and even more so for recurrent neural networks (RNNs) which can easily suffer from vanishing and exploding gradients. In neuroevolution, where evolutionary algorithms are applied to neural architecture search, weights typically need to be initialized at three different times: when initial genomes (ANN architectures) are created at the beginning of the search, when offspring genomes are generated by crossover, and when new nodes or edges are created during mutation. This work explores the difference between using Xavier, Kaiming, and uniform random weight initialization methods, as well as novel Lamarckian weight inheritance methods for initializing new weights during crossover and mutation operations. These are examined using the Evolutionary eXploration of Augmenting Memory Models (EXAMM) neuroevolution algorithm, which is capable of evolving RNNs with a variety of modern memory cells (e.g., LSTM, GRU, MGU, UGRNN and Delta-RNN cells) as well recurrent connections with varying time skips through a high performance island based distributed evolutionary algorithm. Results show that with statistical significance, utilizing the Lamarckian strategies outperforms Kaiming, Xavier and uniform random weight initialization, and can speed neuroevolution by requiring less backpropagation epochs to be evaluated for each generated RNN.
Neuroevolutionary Transfer Learning of Deep Recurrent Neural Networks through Network-Aware Adaptation
Jun 04, 2020
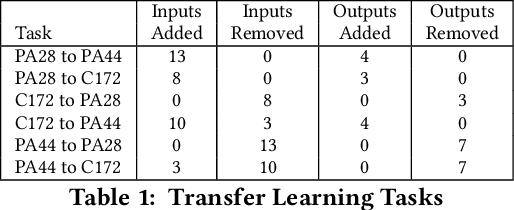

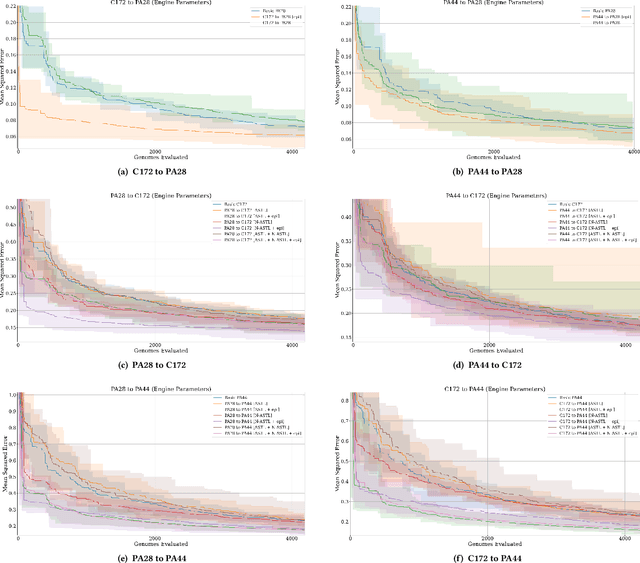
Transfer learning entails taking an artificial neural network (ANN) that is trained on a source dataset and adapting it to a new target dataset. While this has been shown to be quite powerful, its use has generally been restricted by architectural constraints. Previously, in order to reuse and adapt an ANN's internal weights and structure, the underlying topology of the ANN being transferred across tasks must remain mostly the same while a new output layer is attached, discarding the old output layer's weights. This work introduces network-aware adaptive structure transfer learning (N-ASTL), an advancement over prior efforts to remove this restriction. N-ASTL utilizes statistical information related to the source network's topology and weight distribution in order to inform how new input and output neurons are to be integrated into the existing structure. Results show improvements over prior state-of-the-art, including the ability to transfer in challenging real-world datasets not previously possible and improved generalization over RNNs trained without transfer.
Improving Neuroevolution Using Island Extinction and Repopulation
May 15, 2020

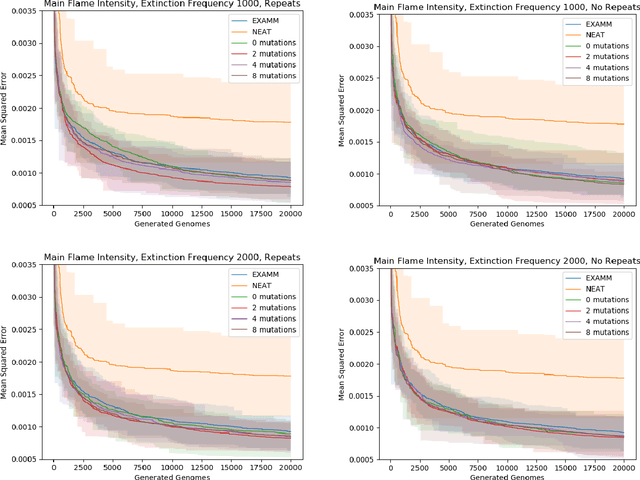

Neuroevolution commonly uses speciation strategies to better explore the search space of neural network architectures. One such speciation strategy is through the use of islands, which are also popular in improving performance and convergence of distributed evolutionary algorithms. However, in this approach some islands can become stagnant and not find new best solutions. In this paper, we propose utilizing extinction events and island repopulation to avoid premature convergence. We explore this with the Evolutionary eXploration of Augmenting Memory Models (EXAMM) neuro-evolution algorithm. In this strategy, all members of the worst performing island are killed of periodically and repopulated with mutated versions of the global best genome. This island based strategy is additionally compared to NEAT's (NeuroEvolution of Augmenting Topologies) speciation strategy. Experiments were performed using two different real world time series datasets (coal-fired power plant and aviation flight data). The results show that with statistical significance, this island extinction and repopulation strategy evolves better global best genomes than both EXAMM's original island based strategy and NEAT's speciation strategy.