 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Death through Fear Intrinsic Conditioning
Jun 05, 2025



Biological and psychological concepts have inspired reinforcement learning algorithms to create new complex behaviors that expand agents' capacity. These behaviors can be seen in the rise of techniques like goal decomposition, curriculum, and intrinsic rewards, which have paved the way for these complex behaviors. One limitation in evaluating these methods is the requirement for engineered extrinsic for realistic environments. A central challenge in engineering the necessary reward function(s) comes from these environments containing states that carry high negative rewards, but provide no feedback to the agent. Death is one such stimuli that fails to provide direct feedback to the agent. In this work, we introduce an intrinsic reward function inspired by early amygdala development and produce this intrinsic reward through a novel memory-augmented neural network (MANN) architecture. We show how this intrinsic motivation serves to deter exploration of terminal states and results in avoidance behavior similar to fear conditioning observed in animals. Furthermore, we demonstrate how modifying a threshold where the fear response is active produces a range of behaviors that are described under the paradigm of general anxiety disorders (GADs). We demonstrate this behavior in the Miniworld Sidewalk environment, which provides a partially observable Markov decision process (POMDP) and a sparse reward with a non-descriptive terminal condition, i.e., death. In effect, this study results in a biologically-inspired neural architecture and framework for fear conditioning paradigms; we empirically demonstrate avoidance behavior in a constructed agent that is able to solve environments with non-descriptive terminal conditions.
Using 3-D LiDAR Data for Safe Physical Human-Robot Interaction
Jun 02, 2024This paper explores the use of 3D lidar in a physical Human-Robot Interaction (pHRI) scenario. To achieve the aforementioned, experiments were conducted to mimic a modern shop-floor environment. Data was collected from a pool of seventeen participants while performing pre-determined tasks in a shared workspace with the robot. To demonstrate an end-to-end case; a perception pipeline was developed that leverages reflectivity, signal, near-infrared, and point-cloud data from a 3-D lidar. This data is then used to perform safety based control whilst satisfying the speed and separation monitoring (SSM) criteria. In order to support the perception pipeline, a state-of-the-art object detection network was leveraged and fine-tuned by transfer learning. An analysis is provided along with results of the perception and the safety based controller. Additionally, this system is compared with the previous work.
Human Comfortability Index Estimation in Industrial Human-Robot Collaboration Task
Aug 28, 2023



Fluent human-robot collaboration requires a robot teammate to understand, learn, and adapt to the human's psycho-physiological state. Such collaborations require a computing system that monitors human physiological signals during human-robot collaboration (HRC) to quantitatively estimate a human's level of comfort, which we have termed in this research as comfortability index (CI) and uncomfortability index (unCI). Subjective metrics (surprise, anxiety, boredom, calmness, and comfortability) and physiological signals were collected during a human-robot collaboration experiment that varied robot behavior. The emotion circumplex model is adapted to calculate the CI from the participant's quantitative data as well as physiological data. To estimate CI/unCI from physiological signals, time features were extracted from electrocardiogram (ECG), galvanic skin response (GSR), and pupillometry signals. In this research, we successfully adapt the circumplex model to find the location (axis) of 'comfortability' and 'uncomfortability' on the circumplex model, and its location match with the closest emotions on the circumplex model. Finally, the study showed that the proposed approach can estimate human comfortability/uncomfortability from physiological signals.
Learning Multi-step Robotic Manipulation Policies from Visual Observation of Scene and Q-value Predictions of Previous Action
Feb 23, 2022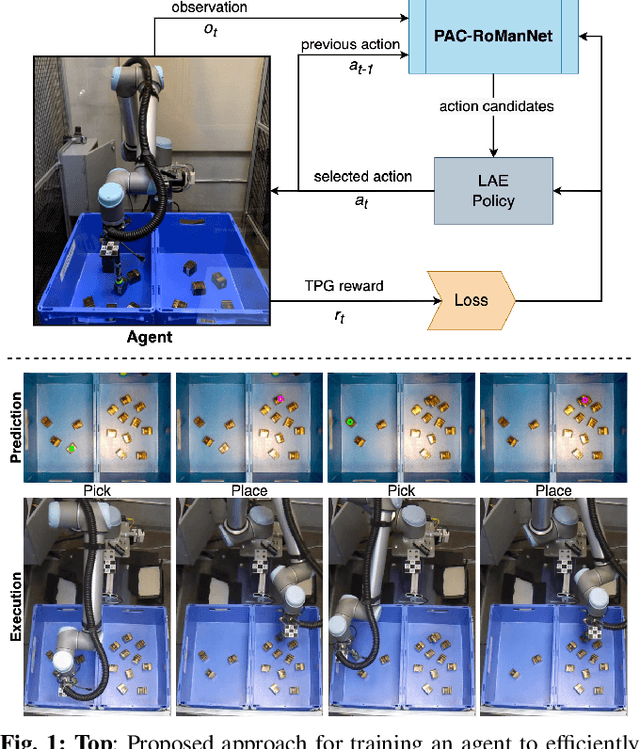
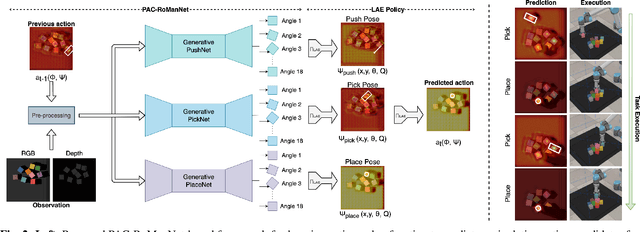
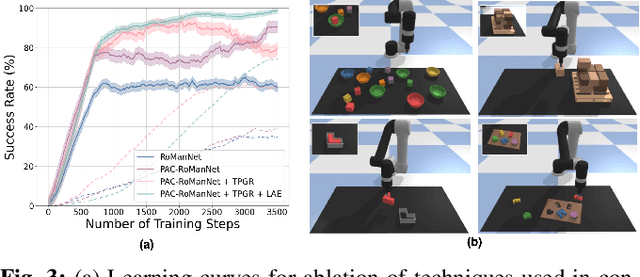
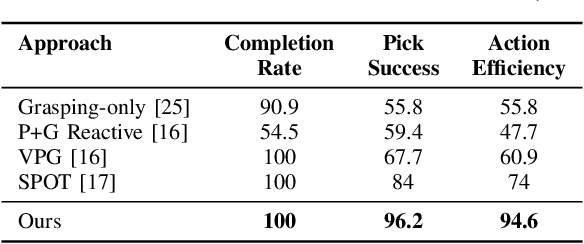
In this work, we focus on multi-step manipulation tasks that involve long-horizon planning and considers progress reversal. Such tasks interlace high-level reasoning that consists of the expected states that can be attained to achieve an overall task and low-level reasoning that decides what actions will yield these states. We propose a sample efficient Previous Action Conditioned Robotic Manipulation Network (PAC-RoManNet) to learn the action-value functions and predict manipulation action candidates from visual observation of the scene and action-value predictions of the previous action. We define a Task Progress based Gaussian (TPG) reward function that computes the reward based on actions that lead to successful motion primitives and progress towards the overall task goal. To balance the ratio of exploration/exploitation, we introduce a Loss Adjusted Exploration (LAE) policy that determines actions from the action candidates according to the Boltzmann distribution of loss estimates. We demonstrate the effectiveness of our approach by training PAC-RoManNet to learn several challenging multi-step robotic manipulation tasks in both simulation and real-world. Experimental results show that our method outperforms the existing methods and achieves state-of-the-art performance in terms of success rate and action efficiency. The ablation studies show that TPG and LAE are especially beneficial for tasks like multiple block stacking. Additional experiments on Ravens-10 benchmark tasks suggest good generalizability of the proposed PAC-RoManNet.
Learning Robotic Manipulation Tasks through Visual Planning
Mar 02, 2021



Multi-step manipulation tasks in unstructured environments are extremely challenging for a robot to learn. Such tasks interlace high-level reasoning that consists of the expected states that can be attained to achieve an overall task and low-level reasoning that decides what actions will yield these states. We propose a model-free deep reinforcement learning method to learn these multi-step manipulation tasks. We introduce a Robotic Manipulation Network (RoManNet) which is a vision-based deep reinforcement learning algorithm to learn the action-value functions and project manipulation action candidates. We define a Task Progress based Gaussian (TPG) reward function that computes the reward based on actions that lead to successful motion primitives and progress towards the overall task goal. We further introduce a Loss Adjusted Exploration (LAE) policy that determines actions from the action candidates according to the Boltzmann distribution of loss estimates. We demonstrate the effectiveness of our approaches by training RoManNet to learn several challenging multi-step robotic manipulation tasks. Empirical results show that our method outperforms the existing methods and achieves state-of-the-art results. The ablation studies show that TPG and LAE are especially beneficial for tasks like multiple block stacking. Code is available at: https://github.com/skumra/romannet
Robotic Grasping using Deep Reinforcement Learning
Jul 09, 2020
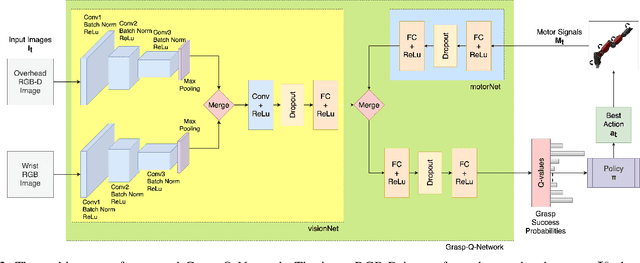


In this work, we present a deep reinforcement learning based method to solve the problem of robotic grasping using visio-motor feedback. The use of a deep learning based approach reduces the complexity caused by the use of hand-designed features. Our method uses an off-policy reinforcement learning framework to learn the grasping policy. We use the double deep Q-learning framework along with a novel Grasp-Q-Network to output grasp probabilities used to learn grasps that maximize the pick success. We propose a visual servoing mechanism that uses a multi-view camera setup that observes the scene which contains the objects of interest. We performed experiments using a Baxter Gazebo simulated environment as well as on the actual robot. The results show that our proposed method outperforms the baseline Q-learning framework and increases grasping accuracy by adapting a multi-view model in comparison to a single-view model.
Human Position Detection & Tracking with On-robot Time-of-Flight Laser Ranging Sensors
Sep 21, 2019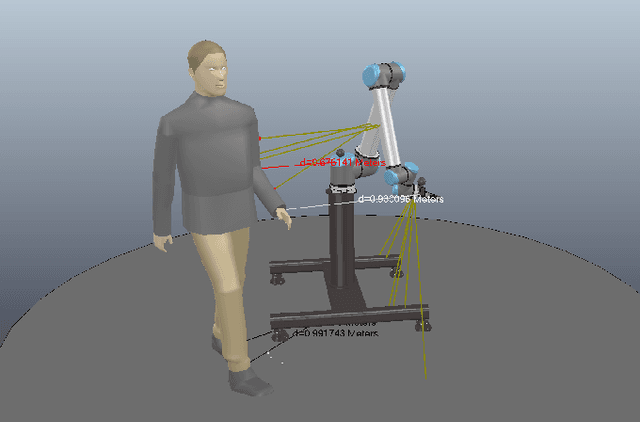
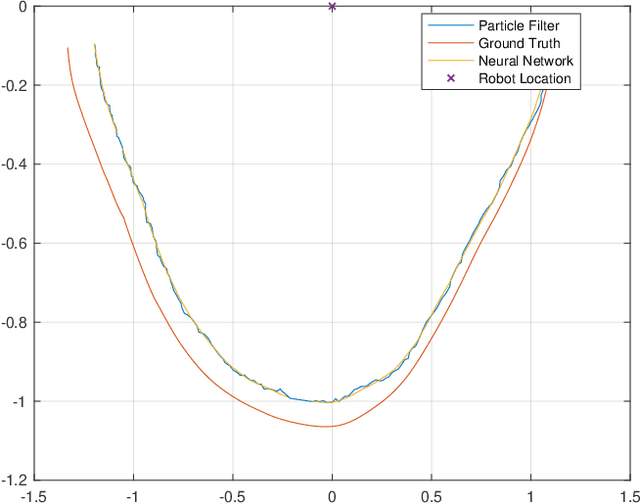
In this paper, we propose a simple methodology to detect the partial pose of a human occupying the manipulator work-space using only on-robot time--of--flight laser ranging sensors. The sensors are affixed on each link of the robot in a circular array fashion where each array possesses sixteen single unit laser ranging lidar(s). The detection is performed by leveraging an artificial neural network which takes a highly sparse 3-D point cloud input to produce an estimate of the partial pose which is the ground projection frame of the human footprint. We also present a particle filter based approach to the tracking problem when the input data is unreliable. Ultimately, the simulation results are presented and analyzed.
Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network
Sep 11, 2019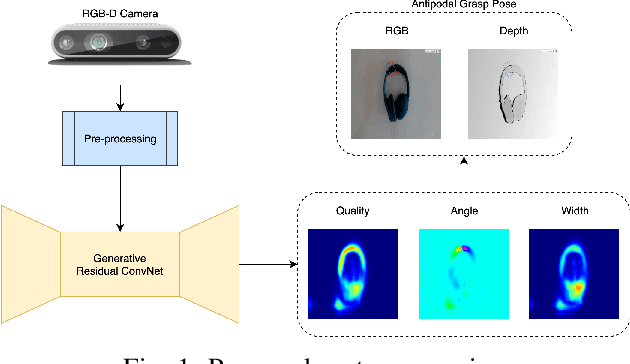
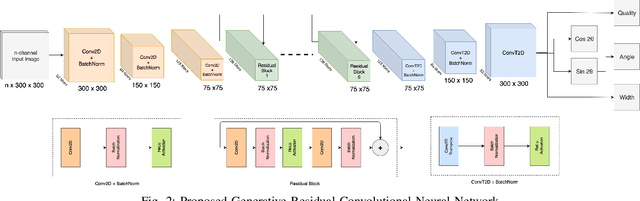

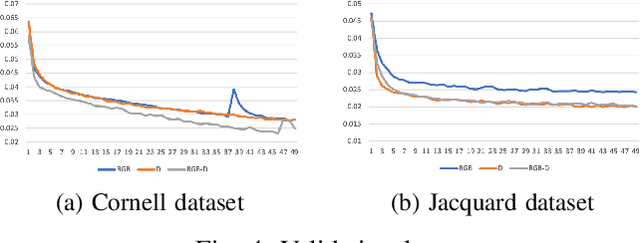
In this paper, we tackle the problem of generating antipodal robotic grasps for unknown objects from n-channel image of the scene. We propose a novel Generative Residual Convolutional Neural Network (GR-ConvNet) model that can generate robust antipodal grasps from n-channel input at realtime speeds (~20ms). We evaluate the proposed model architecture on standard datasets and previously unseen household objects. We achieved state-of-the-art accuracy of 97.7% and 94.6% on Cornell and Jacquard grasping datasets respectively. We also demonstrate a 93.5% grasp success rate on previously unseen real-world objects. Our open-source implementation of GR-ConvNet can be found at github.com/skumra/robotic-grasping.
A Framework for Monitoring Human Physiological Response during Human Robot Collaborative Task
Jul 26, 2019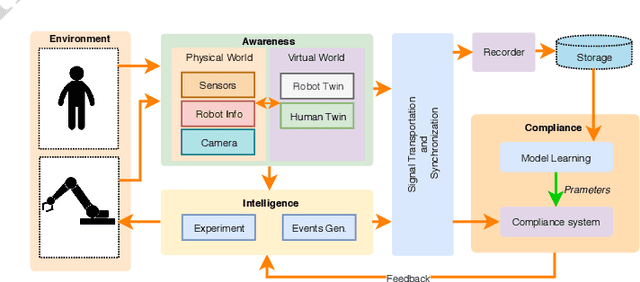
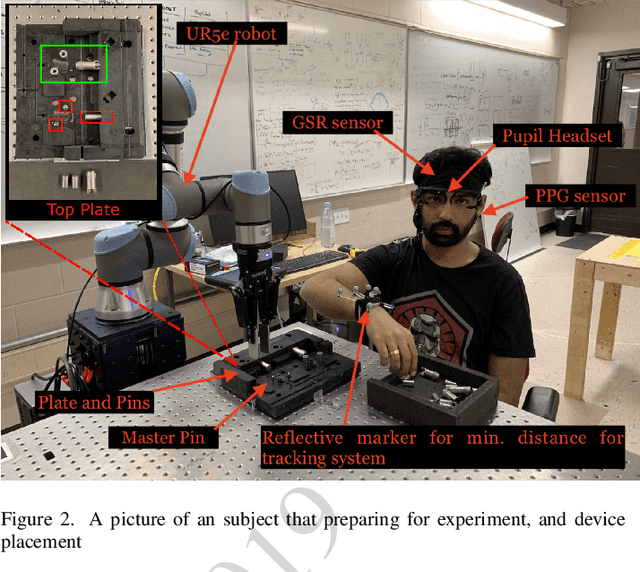
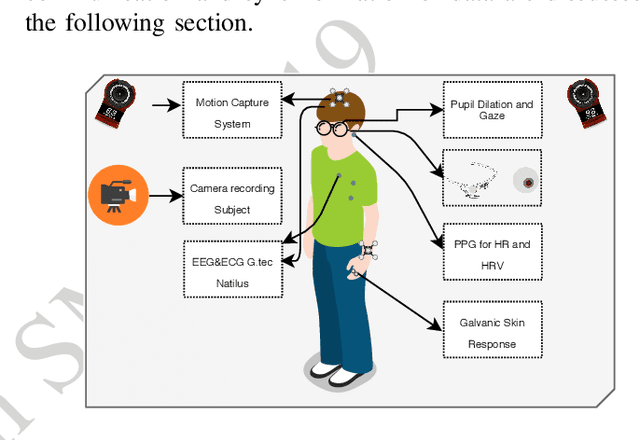
In this paper, a framework for monitoring human physiological response during Human-Robot Collaborative (HRC) task is presented. The framework highlights the importance of generation of event markers related to both human and robot, and also synchronization of data collected. This framework enables continuous data collection during an HRC task when changing robot movements as a form of stimuli to invoke a human physiological response. It also presents two case studies based on this framework and a data visualization tool for representation and easy analysis of the collected data during an HRC experiment.
Sensing Volume Coverage of Robot Workspace using On-Robot Time-of-Flight Sensor Arrays for Safe Human Robot Interaction
Jul 03, 2019
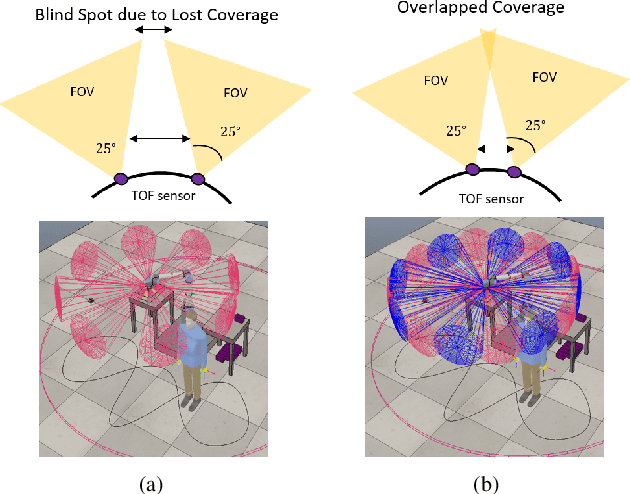
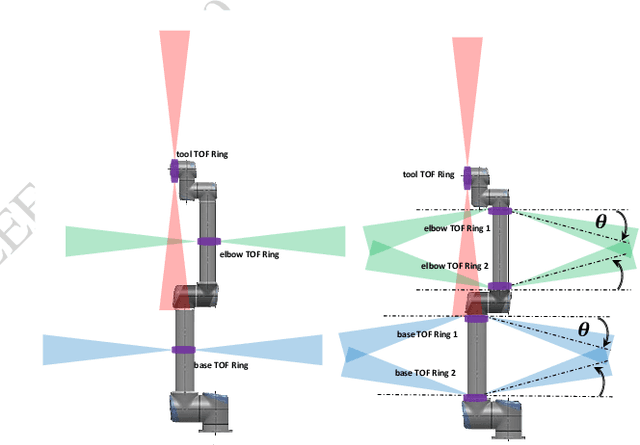

In this paper, an analysis of the sensing volume coverage of robot workspace as well as the shared human-robot collaborative workspace for various configurations of on-robot Time-of-Flight (ToF) sensor array rings is presented. A methodology for volumetry using octrees to quantify the detection/sensing volume of the sensors is proposed. The change in sensing volume coverage by increasing the number of sensors per ToF sensor array ring and also increasing the number of rings mounted on robot link is also studied. Considerations of maximum ideal volume around the robot workspace that a given ToF sensor array ring placement and orientation setup should cover for safe human robot interaction are presented. The sensing volume coverage measurements in this maximum ideal volume are tabulated and observations on various ToF configurations and their coverage for close and far zones of the robot are determined.