 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Grasping using Deep Reinforcement Learning
Paper and Code
Jul 09, 2020
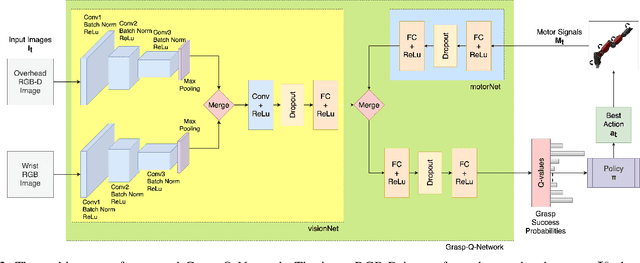


In this work, we present a deep reinforcement learning based method to solve the problem of robotic grasping using visio-motor feedback. The use of a deep learning based approach reduces the complexity caused by the use of hand-designed features. Our method uses an off-policy reinforcement learning framework to learn the grasping policy. We use the double deep Q-learning framework along with a novel Grasp-Q-Network to output grasp probabilities used to learn grasps that maximize the pick success. We propose a visual servoing mechanism that uses a multi-view camera setup that observes the scene which contains the objects of interest. We performed experiments using a Baxter Gazebo simulated environment as well as on the actual robot. The results show that our proposed method outperforms the baseline Q-learning framework and increases grasping accuracy by adapting a multi-view model in comparison to a single-view model.