 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-step Robotic Manipulation Policies from Visual Observation of Scene and Q-value Predictions of Previous Action
Feb 23, 2022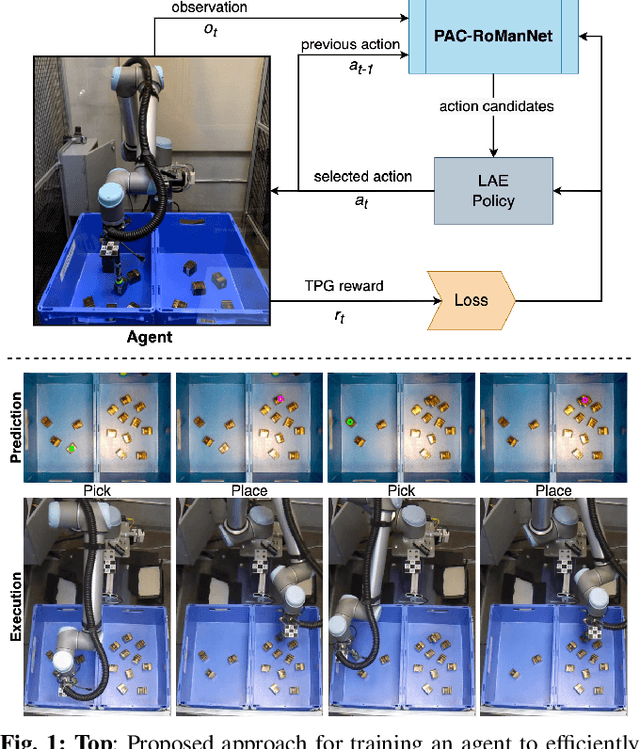
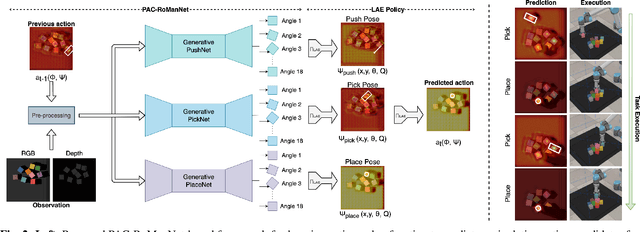
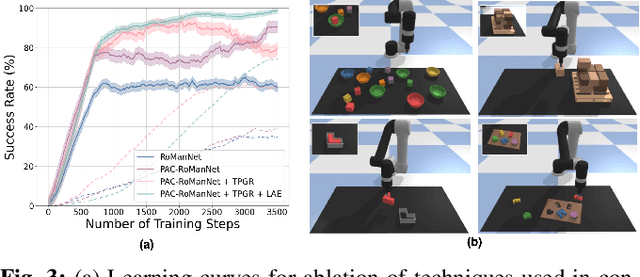
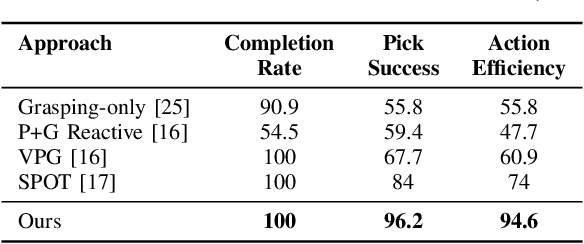
In this work, we focus on multi-step manipulation tasks that involve long-horizon planning and considers progress reversal. Such tasks interlace high-level reasoning that consists of the expected states that can be attained to achieve an overall task and low-level reasoning that decides what actions will yield these states. We propose a sample efficient Previous Action Conditioned Robotic Manipulation Network (PAC-RoManNet) to learn the action-value functions and predict manipulation action candidates from visual observation of the scene and action-value predictions of the previous action. We define a Task Progress based Gaussian (TPG) reward function that computes the reward based on actions that lead to successful motion primitives and progress towards the overall task goal. To balance the ratio of exploration/exploitation, we introduce a Loss Adjusted Exploration (LAE) policy that determines actions from the action candidates according to the Boltzmann distribution of loss estimates. We demonstrate the effectiveness of our approach by training PAC-RoManNet to learn several challenging multi-step robotic manipulation tasks in both simulation and real-world. Experimental results show that our method outperforms the existing methods and achieves state-of-the-art performance in terms of success rate and action efficiency. The ablation studies show that TPG and LAE are especially beneficial for tasks like multiple block stacking. Additional experiments on Ravens-10 benchmark tasks suggest good generalizability of the proposed PAC-RoManNet.
Kit-Net: Self-Supervised Learning to Kit Novel 3D Objects into Novel 3D Cavities
Jul 13, 2021



In industrial part kitting, 3D objects are inserted into cavities for transportation or subsequent assembly. Kitting is a critical step as it can decrease downstream processing and handling times and enable lower storage and shipping costs. We present Kit-Net, a framework for kitting previously unseen 3D objects into cavities given depth images of both the target cavity and an object held by a gripper in an unknown initial orientation. Kit-Net uses self-supervised deep learning and data augmentation to train a convolutional neural network (CNN) to robustly estimate 3D rotations between objects and matching concave or convex cavities using a large training dataset of simulated depth images pairs. Kit-Net then uses the trained CNN to implement a controller to orient and position novel objects for insertion into novel prismatic and conformal 3D cavities. Experiments in simulation suggest that Kit-Net can orient objects to have a 98.9% average intersection volume between the object mesh and that of the target cavity. Physical experiments with industrial objects succeed in 18% of trials using a baseline method and in 63% of trials with Kit-Net. Video, code, and data are available at https://github.com/BerkeleyAutomation/Kit-Net.
Robotic Grasping using Deep Reinforcement Learning
Jul 09, 2020
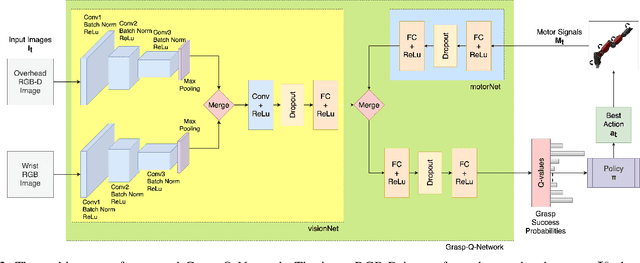


In this work, we present a deep reinforcement learning based method to solve the problem of robotic grasping using visio-motor feedback. The use of a deep learning based approach reduces the complexity caused by the use of hand-designed features. Our method uses an off-policy reinforcement learning framework to learn the grasping policy. We use the double deep Q-learning framework along with a novel Grasp-Q-Network to output grasp probabilities used to learn grasps that maximize the pick success. We propose a visual servoing mechanism that uses a multi-view camera setup that observes the scene which contains the objects of interest. We performed experiments using a Baxter Gazebo simulated environment as well as on the actual robot. The results show that our proposed method outperforms the baseline Q-learning framework and increases grasping accuracy by adapting a multi-view model in comparison to a single-view model.
Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network
Sep 11, 2019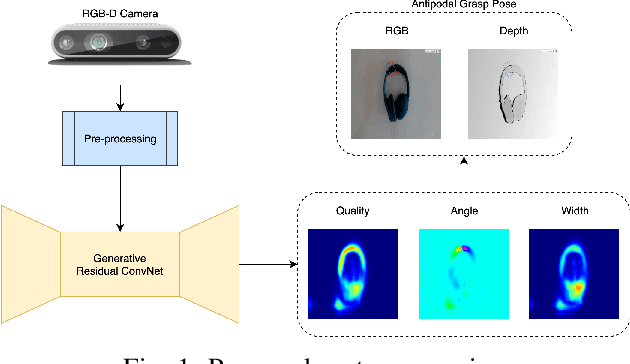
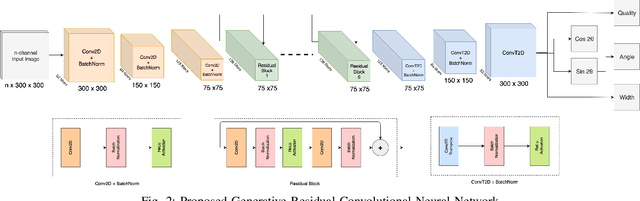

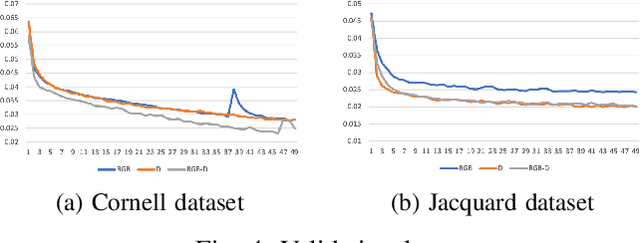
In this paper, we tackle the problem of generating antipodal robotic grasps for unknown objects from n-channel image of the scene. We propose a novel Generative Residual Convolutional Neural Network (GR-ConvNet) model that can generate robust antipodal grasps from n-channel input at realtime speeds (~20ms). We evaluate the proposed model architecture on standard datasets and previously unseen household objects. We achieved state-of-the-art accuracy of 97.7% and 94.6% on Cornell and Jacquard grasping datasets respectively. We also demonstrate a 93.5% grasp success rate on previously unseen real-world objects. Our open-source implementation of GR-ConvNet can be found at github.com/skumra/robotic-grasping.