 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Long Grammatical Sequences Using Recurrent Networks Augmented With An External Differentiable Stack
Paper and Code
Apr 22, 2020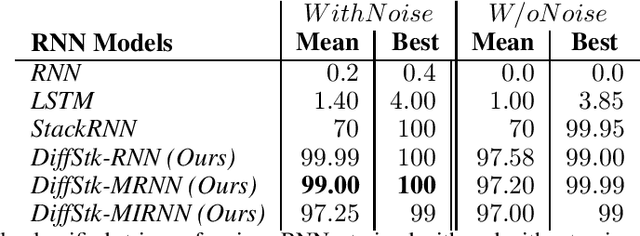
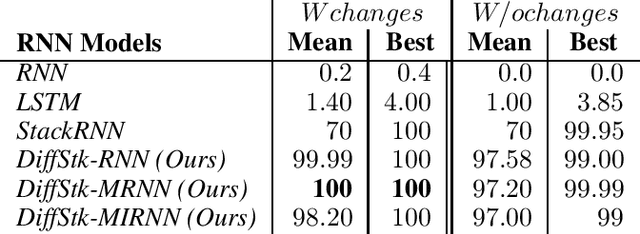
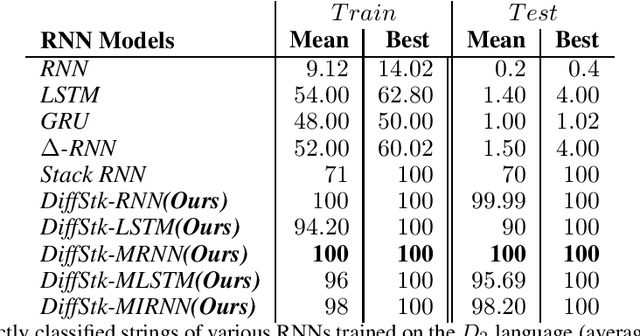

Recurrent neural networks (RNNs) are a widely used deep architecture for sequence modeling, generation, and prediction. Despite success in applications such as machine translation and voice recognition, these stateful models have several critical shortcomings. Specifically, RNNs generalize poorly over very long sequences, which limits their applicability to many important temporal processing and time series forecasting problems. For example, RNNs struggle in recognizing complex context free languages (CFLs), never reaching 100% accuracy on training. One way to address these shortcomings is to couple an RNN with an external, differentiable memory structure, such as a stack. However, differentiable memories in prior work have neither been extensively studied on CFLs nor tested on sequences longer than those seen in training. The few efforts that have studied them have shown that continuous differentiable memory structures yield poor generalization for complex CFLs, making the RNN less interpretable. In this paper, we improve the memory-augmented RNN with important architectural and state updating mechanisms that ensure that the model learns to properly balance the use of its latent states with external memory. Our improved RNN models exhibit better generalization performance and are able to classify long strings generated by complex hierarchical context free grammars (CFGs). We evaluate our models on CGGs, including the Dyck languages, as well as on the Penn Treebank language modelling task, and achieve stable, robust performance across these benchmarks. Furthermore, we show that only our memory-augmented networks are capable of retaining memory for a longer duration up to strings of length 160.