 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSDWC: Federated Synergistic Dual-Representation Weak Causal Learning for OOD
Nov 12, 2025
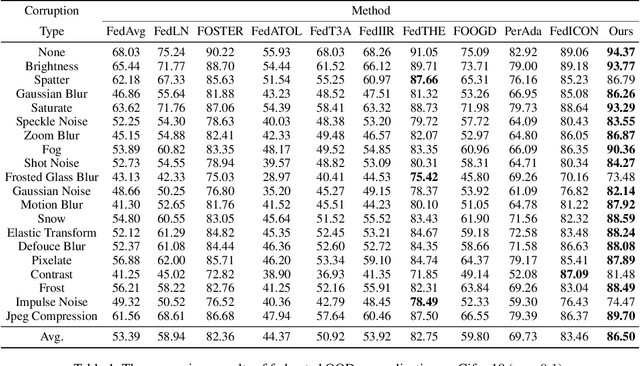
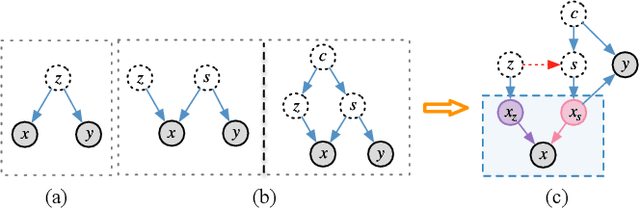
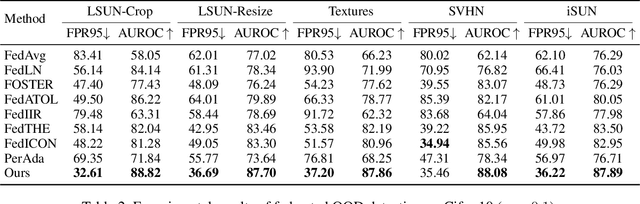
Amid growing demands for data privacy and advances in computational infrastructure, federated learning (FL) has emerged as a prominent distributed learning paradigm. Nevertheless, differences in data distribution (such as covariate and semantic shifts) severely affect its reliability in real-world deployments. To address this issue, we propose FedSDWC, a causal inference method that integrates both invariant and variant features. FedSDWC infers causal semantic representations by modeling the weak causal influence between invariant and variant features, effectively overcoming the limitations of existing invariant learning methods in accurately capturing invariant features and directly constructing causal representations. This approach significantly enhances FL's ability to generalize and detect OOD data. Theoretically, we derive FedSDWC's generalization error bound under specific conditions and, for the first time, establish its relationship with client prior distributions. Moreover, extensive experiments conducted on multiple benchmark datasets validate the superior performance of FedSDWC in handling covariate and semantic shifts. For example, FedSDWC outperforms FedICON, the next best baseline, by an average of 3.04% on CIFAR-10 and 8.11% on CIFAR-100.
Multiple Contexts and Frequencies Aggregation Network forDeepfake Detection
Aug 03, 2024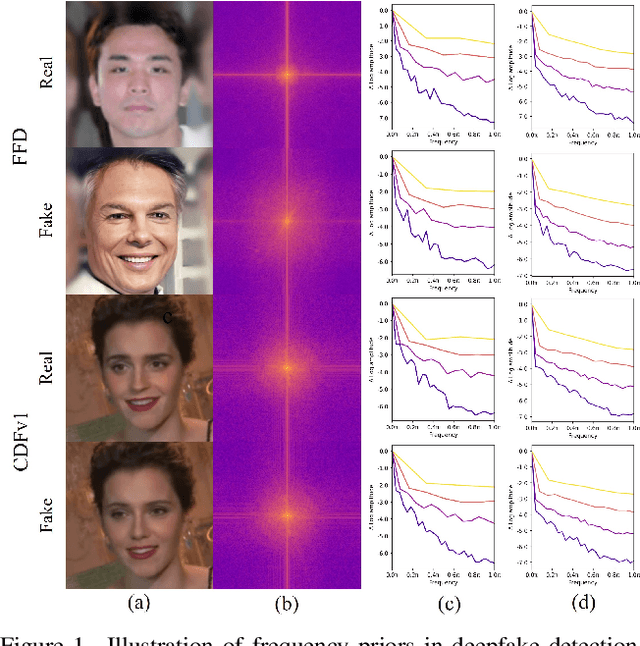
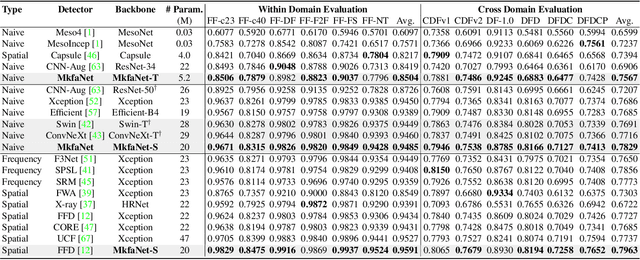


Deepfake detection faces increasing challenges since the fast growth of generative models in developing massive and diverse Deepfake technologies. Recent advances rely on introducing heuristic features from spatial or frequency domains rather than modeling general forgery features within backbones. To address this issue, we turn to the backbone design with two intuitive priors from spatial and frequency detectors, \textit{i.e.,} learning robust spatial attributes and frequency distributions that are discriminative for real and fake samples. To this end, we propose an efficient network for face forgery detection named MkfaNet, which consists of two core modules. For spatial contexts, we design a Multi-Kernel Aggregator that adaptively selects organ features extracted by multiple convolutions for modeling subtle facial differences between real and fake faces. For the frequency components, we propose a Multi-Frequency Aggregator to process different bands of frequency components by adaptively reweighing high-frequency and low-frequency features. Comprehensive experiments on seven popular deepfake detection benchmarks demonstrate that our proposed MkfaNet variants achieve superior performances in both within-domain and across-domain evaluations with impressive efficiency of parameter usage.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Mar 05, 2024



Face Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable sorely using the dominant modality. To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients. Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source code and protocols will be released on https://github.com/OMGGGGG/mmdg.
Biomedical Image Splicing Detection using Uncertainty-Guided Refinement
Sep 28, 2023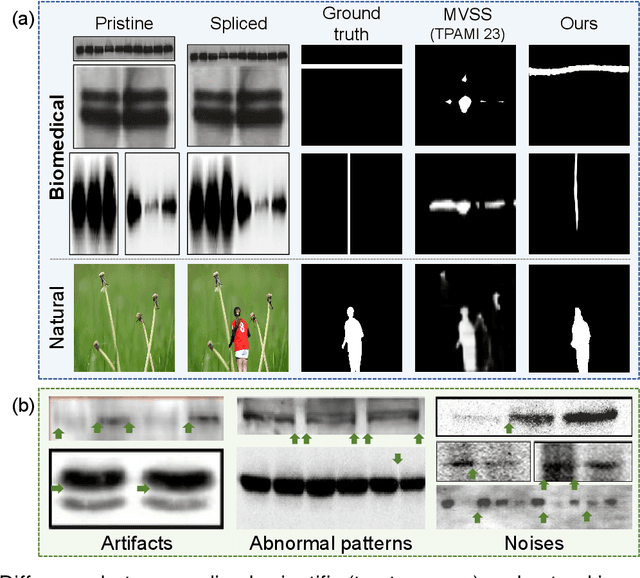

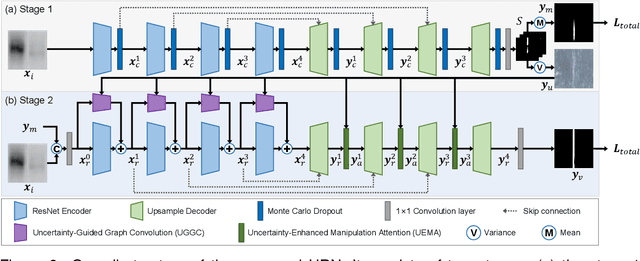
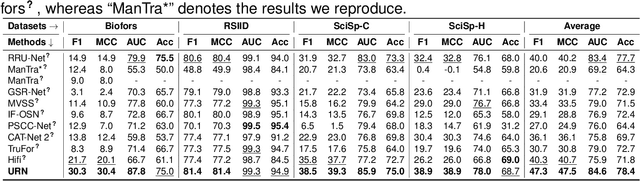
Recently, a surge in biomedical academic publications suspected of image manipulation has led to numerous retractions, turning biomedical image forensics into a research hotspot. While manipulation detectors are concerning, the specific detection of splicing traces in biomedical images remains underexplored. The disruptive factors within biomedical images, such as artifacts, abnormal patterns, and noises, show misleading features like the splicing traces, greatly increasing the challenge for this task. Moreover, the scarcity of high-quality spliced biomedical images also limits potential advancements in this field. In this work, we propose an Uncertainty-guided Refinement Network (URN) to mitigate the effects of these disruptive factors. Our URN can explicitly suppress the propagation of unreliable information flow caused by disruptive factors among regions, thereby obtaining robust features. Moreover, URN enables a concentration on the refinement of uncertainly predicted regions during the decoding phase. Besides, we construct a dataset for Biomedical image Splicing (BioSp) detection, which consists of 1,290 spliced images. Compared with existing datasets, BioSp comprises the largest number of spliced images and the most diverse sources. Comprehensive experiments on three benchmark datasets demonstrate the superiority of the proposed method. Meanwhile, we verify the generalizability of URN when against cross-dataset domain shifts and its robustness to resist post-processing approaches. Our BioSp dataset will be released upon acceptance.