 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential three-way decisions with a single hidden layer feedforward neural network
Mar 14, 2023



The three-way decisions strategy has been employed to construct network topology in a single hidden layer feedforward neural network (SFNN). However, this model has a general performance, and does not consider the process costs, since it has fixed threshold parameters. Inspired by the sequential three-way decisions (STWD), this paper proposes STWD with an SFNN (STWD-SFNN) to enhance the performance of networks on structured datasets. STWD-SFNN adopts multi-granularity levels to dynamically learn the number of hidden layer nodes from coarse to fine, and set the sequential threshold parameters. Specifically, at the coarse granular level, STWD-SFNN handles easy-to-classify instances by applying strict threshold conditions, and with the increasing number of hidden layer nodes at the fine granular level, STWD-SFNN focuses more on disposing of the difficult-to-classify instances by applying loose threshold conditions, thereby realizing the classification of instances. Moreover, STWD-SFNN considers and reports the process cost produced from each granular level. The experimental results verify that STWD-SFNN has a more compact network on structured datasets than other SFNN models, and has better generalization performance than the competitive models. All models and datasets can be downloaded from https://github.com/wuc567/Machine-learning/tree/main/STWD-SFNN.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022
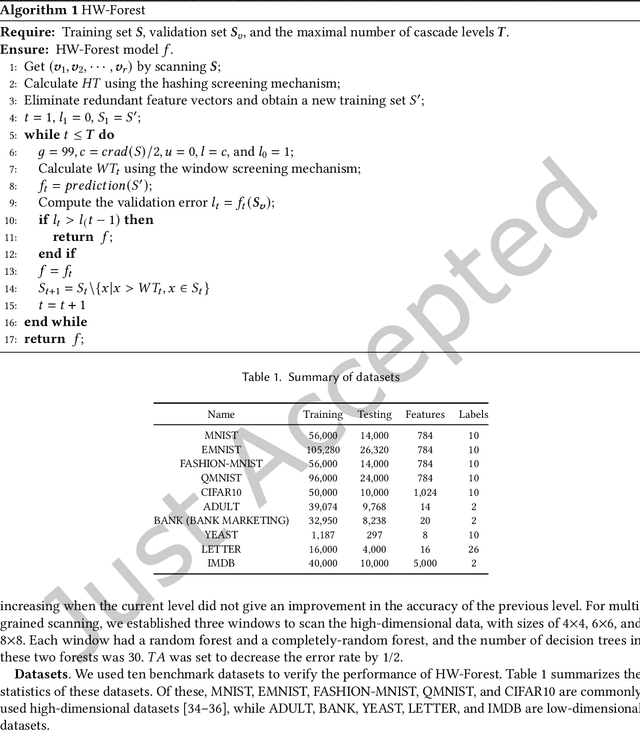
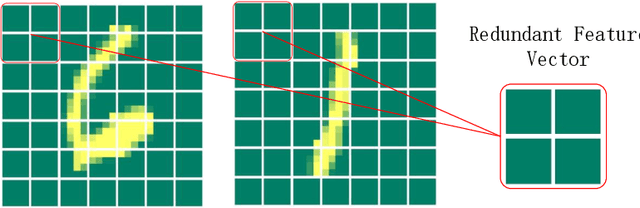
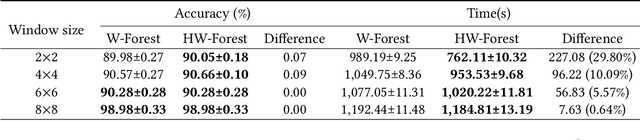
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.
OPP-Miner: Order-preserving sequential pattern mining
Feb 09, 2022
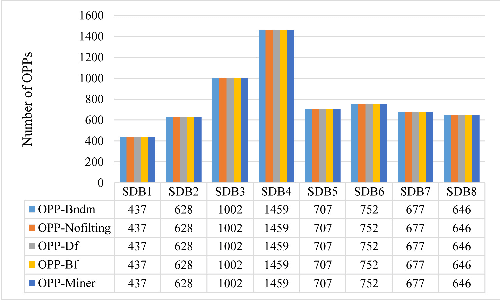
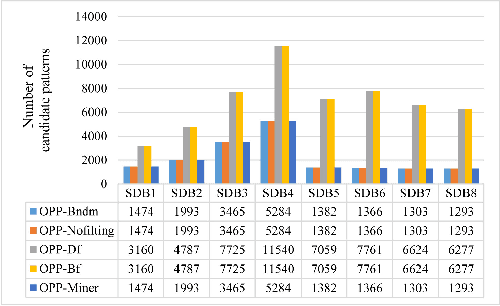
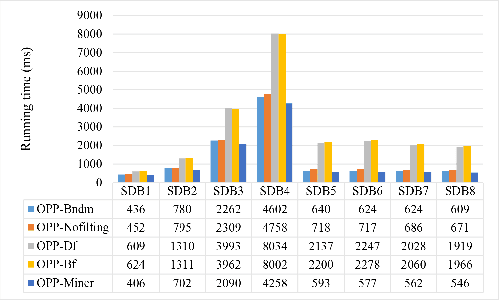
A time series is a collection of measurements in chronological order. Discovering patterns from time series is useful in many domains, such as stock analysis, disease detection, and weather forecast. To discover patterns, existing methods often convert time series data into another form, such as nominal/symbolic format, to reduce dimensionality, which inevitably deviates the data values. Moreover, existing methods mainly neglect the order relationships between time series values. To tackle these issues, inspired by order-preserving matching, this paper proposes an Order-Preserving sequential Pattern (OPP) mining method, which represents patterns based on the order relationships of the time series data. An inherent advantage of such representation is that the trend of a time series can be represented by the relative order of the values underneath the time series data. To obtain frequent trends in time series, we propose the OPP-Miner algorithm to mine patterns with the same trend (sub-sequences with the same relative order). OPP-Miner employs the filtration and verification strategies to calculate the support and uses pattern fusion strategy to generate candidate patterns. To compress the result set, we also study finding the maximal OPPs. Experiments validate that OPP-Miner is not only efficient and scalable but can also discover similar sub-sequences in time series. In addition, case studies show that our algorithms have high utility in analyzing the COVID-19 epidemic by identifying critical trends and improve the clustering performance.
DBC-Forest: Deep forest with binning confidence screening
Dec 25, 2021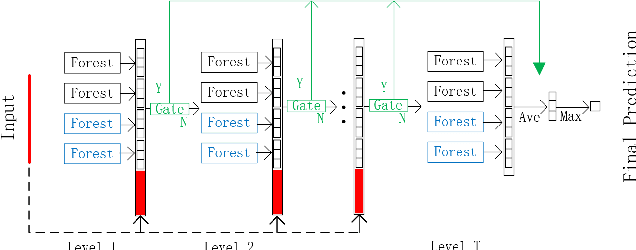
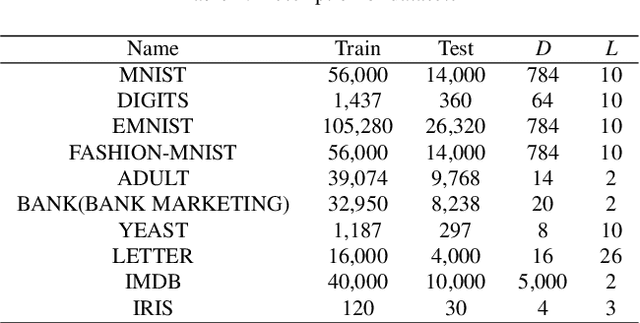
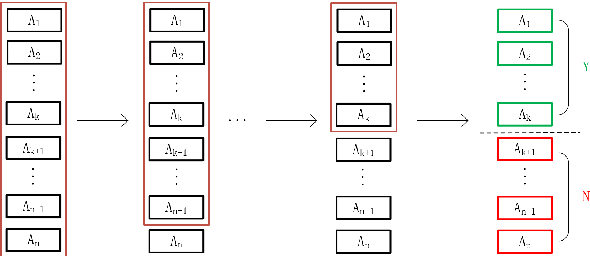
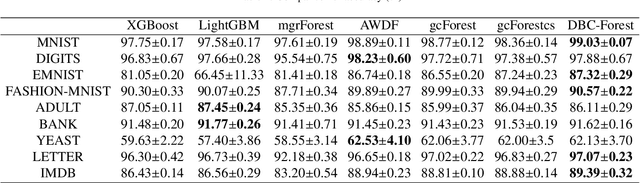
As a deep learning model, deep confidence screening forest (gcForestcs) has achieved great success in various applications. Compared with the traditional deep forest approach, gcForestcs effectively reduces the high time cost by passing some instances in the high-confidence region directly to the final stage. However, there is a group of instances with low accuracy in the high-confidence region, which are called mis-partitioned instances. To find these mis-partitioned instances, this paper proposes a deep binning confidence screening forest (DBC-Forest) model, which packs all instances into bins based on their confidences. In this way, more accurate instances can be passed to the final stage, and the performance is improved. Experimental results show that DBC-Forest achieves highly accurate predictions for the same hyperparameters and is faster than other similar models to achieve the same accuracy.
Distant Supervision for E-commerce Query Segmentation via Attention Network
Nov 09, 2020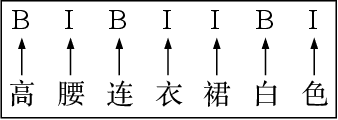
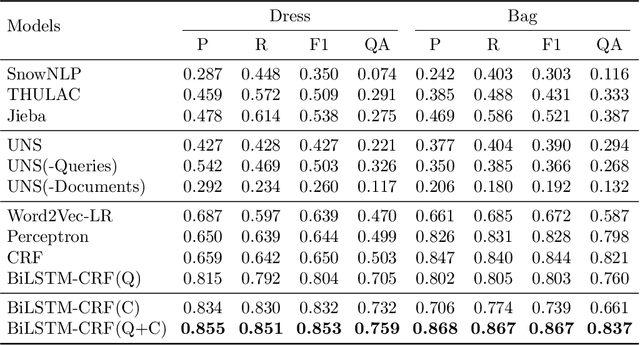
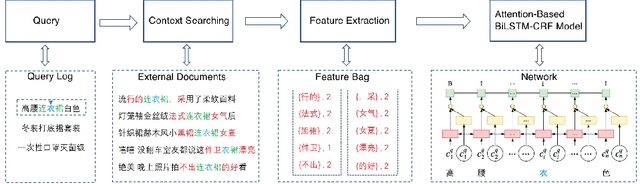
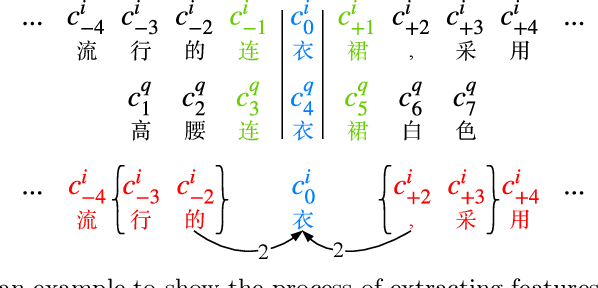
The booming online e-commerce platforms demand highly accurate approaches to segment queries that carry the product requirements of consumers. Recent works have shown that the supervised methods, especially those based on deep learning, are attractive for achieving better performance on the problem of query segmentation. However, the lack of labeled data is still a big challenge for training a deep segmentation network, and the problem of Out-of-Vocabulary (OOV) also adversely impacts the performance of query segmentation. Different from query segmentation task in an open domain, e-commerce scenario can provide external documents that are closely related to these queries. Thus, to deal with the two challenges, we employ the idea of distant supervision and design a novel method to find contexts in external documents and extract features from these contexts. In this work, we propose a BiLSTM-CRF based model with an attention module to encode external features, such that external contexts information, which can be utilized naturally and effectively to help query segmentation. Experiments on two datasets show the effectiveness of our approach compared with several kinds of baselines.