 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMLoP: Multi-Modal Low-Rank Prompting for Efficient Vision-Language Adaptation
Feb 24, 2026Prompt learning has become a dominant paradigm for adapting vision-language models (VLMs) such as CLIP to downstream tasks without modifying pretrained weights. While extending prompts to both vision and text encoders across multiple transformer layers significantly boosts performance, it dramatically increases the number of trainable parameters, with state-of-the-art methods requiring millions of parameters and abandoning the parameter efficiency that makes prompt tuning attractive. In this work, we propose \textbf{MMLoP} (\textbf{M}ulti-\textbf{M}odal \textbf{Lo}w-Rank \textbf{P}rompting), a framework that achieves deep multi-modal prompting with only \textbf{11.5K trainable parameters}, comparable to early text-only methods like CoOp. MMLoP parameterizes vision and text prompts at each transformer layer through a low-rank factorization, which serves as an implicit regularizer against overfitting on few-shot training data. To further close the accuracy gap with state-of-the-art methods, we introduce three complementary components: a self-regulating consistency loss that anchors prompted representations to frozen zero-shot CLIP features at both the feature and logit levels, a uniform drift correction that removes the global embedding shift induced by prompt tuning to preserve class-discriminative structure, and a shared up-projection that couples vision and text prompts through a common low-rank factor to enforce cross-modal alignment. Extensive experiments across three benchmarks and 11 diverse datasets demonstrate that MMLoP achieves a highly favorable accuracy-efficiency tradeoff, outperforming the majority of existing methods including those with orders of magnitude more parameters, while achieving a harmonic mean of 79.70\% on base-to-novel generalization.
Stochastic Gradient Descent with Strategic Querying
Aug 23, 2025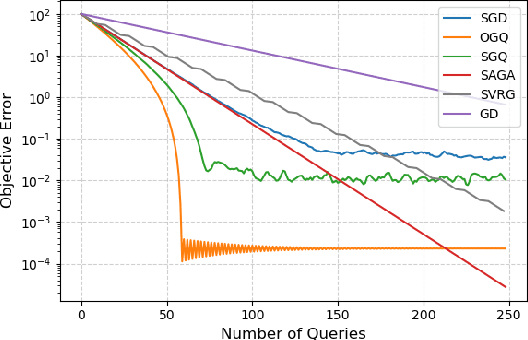
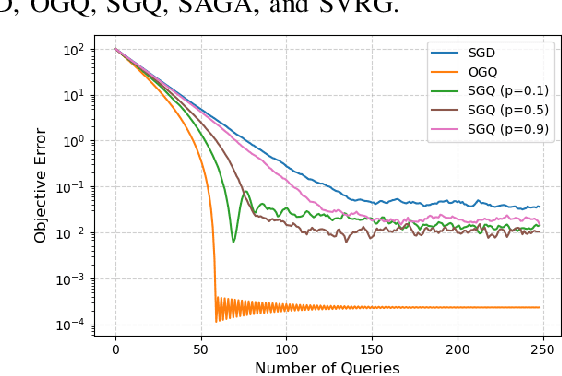
This paper considers a finite-sum optimization problem under first-order queries and investigates the benefits of strategic querying on stochastic gradient-based methods compared to uniform querying strategy. We first introduce Oracle Gradient Querying (OGQ), an idealized algorithm that selects one user's gradient yielding the largest possible expected improvement (EI) at each step. However, OGQ assumes oracle access to the gradients of all users to make such a selection, which is impractical in real-world scenarios. To address this limitation, we propose Strategic Gradient Querying (SGQ), a practical algorithm that has better transient-state performance than SGD while making only one query per iteration. For smooth objective functions satisfying the Polyak-Lojasiewicz condition, we show that under the assumption of EI heterogeneity, OGQ enhances transient-state performance and reduces steady-state variance, while SGQ improves transient-state performance over SGD. Our numerical experiments validate our theoretical findings.
Few-Shot Adversarial Low-Rank Fine-Tuning of Vision-Language Models
May 21, 2025Vision-Language Models (VLMs) such as CLIP have shown remarkable performance in cross-modal tasks through large-scale contrastive pre-training. To adapt these large transformer-based models efficiently for downstream tasks, Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA have emerged as scalable alternatives to full fine-tuning, especially in few-shot scenarios. However, like traditional deep neural networks, VLMs are highly vulnerable to adversarial attacks, where imperceptible perturbations can significantly degrade model performance. Adversarial training remains the most effective strategy for improving model robustness in PEFT. In this work, we propose AdvCLIP-LoRA, the first algorithm designed to enhance the adversarial robustness of CLIP models fine-tuned with LoRA in few-shot settings. Our method formulates adversarial fine-tuning as a minimax optimization problem and provides theoretical guarantees for convergence under smoothness and nonconvex-strong-concavity assumptions. Empirical results across eight datasets using ViT-B/16 and ViT-B/32 models show that AdvCLIP-LoRA significantly improves robustness against common adversarial attacks (e.g., FGSM, PGD), without sacrificing much clean accuracy. These findings highlight AdvCLIP-LoRA as a practical and theoretically grounded approach for robust adaptation of VLMs in resource-constrained settings.
The Safety-Privacy Tradeoff in Linear Bandits
Apr 23, 2025We consider a collection of linear stochastic bandit problems, each modeling the random response of different agents to proposed interventions, coupled together by a global safety constraint. We assume a central coordinator must choose actions to play on each bandit with the objective of regret minimization, while also ensuring that the expected response of all agents satisfies the global safety constraints at each round, in spite of uncertainty about the bandits' parameters. The agents consider their observed responses to be private and in order to protect their sensitive information, the data sharing with the central coordinator is performed under local differential privacy (LDP). However, providing higher level of privacy to different agents would have consequences in terms of safety and regret. We formalize these tradeoffs by building on the notion of the sharpness of the safety set - a measure of how the geometric properties of the safe set affects the growth of regret - and propose a unilaterally unimprovable vector of privacy levels for different agents given a maximum regret budget.
Constrained Online Convex Optimization with Polyak Feasibility Steps
Feb 18, 2025In this work, we study online convex optimization with a fixed constraint function $g : \mathbb{R}^d \rightarrow \mathbb{R}$. Prior work on this problem has shown $O(\sqrt{T})$ regret and cumulative constraint satisfaction $\sum_{t=1}^{T} g(x_t) \leq 0$, while only accessing the constraint value and subgradient at the played actions $g(x_t), \partial g(x_t)$. Using the same constraint information, we show a stronger guarantee of anytime constraint satisfaction $g(x_t) \leq 0 \ \forall t \in [T]$, and matching $O(\sqrt{T})$ regret guarantees. These contributions are thanks to our approach of using Polyak feasibility steps to ensure constraint satisfaction, without sacrificing regret. Specifically, after each step of online gradient descent, our algorithm applies a subgradient descent step on the constraint function where the step-size is chosen according to the celebrated Polyak step-size. We further validate this approach with numerical experiments.
Decentralized Low-Rank Fine-Tuning of Large Language Models
Jan 26, 2025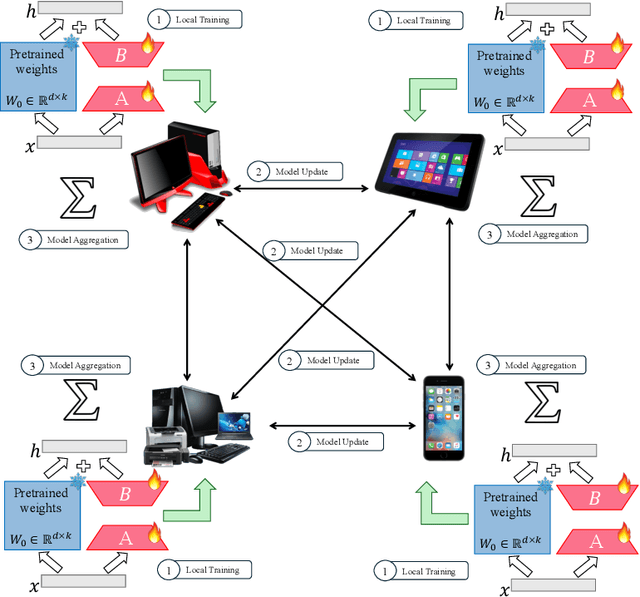

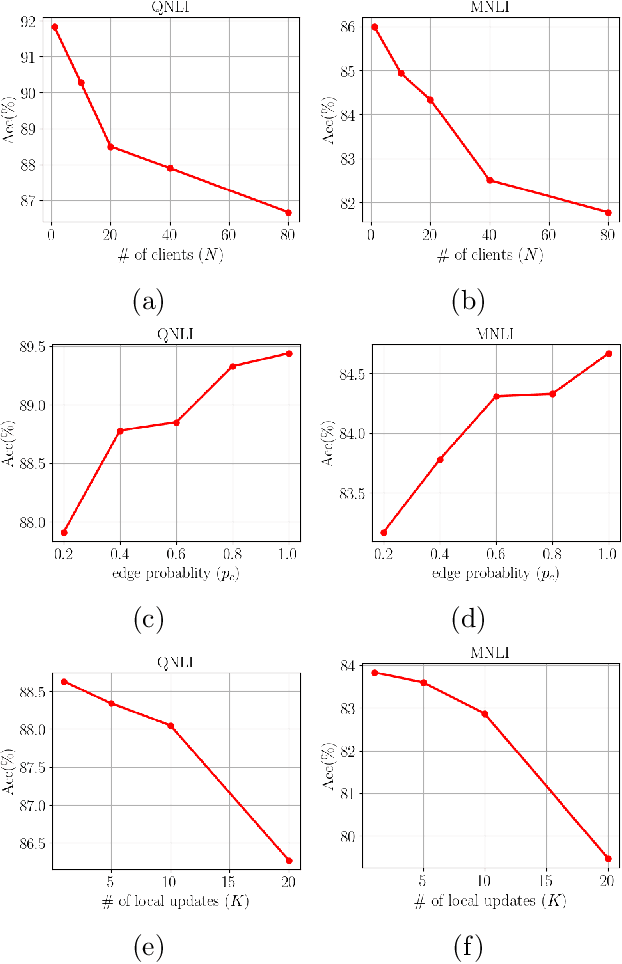

The emergence of Large Language Models (LLMs) such as GPT-4, LLaMA, and BERT has transformed artificial intelligence, enabling advanced capabilities across diverse applications. While parameter-efficient fine-tuning (PEFT) techniques like LoRA offer computationally efficient adaptations of these models, their practical deployment often assumes centralized data and training environments. However, real-world scenarios frequently involve distributed, privacy-sensitive datasets that require decentralized solutions. Federated learning (FL) addresses data privacy by coordinating model updates across clients, but it is typically based on centralized aggregation through a parameter server, which can introduce bottlenecks and communication constraints. Decentralized learning, in contrast, eliminates this dependency by enabling direct collaboration between clients, improving scalability and efficiency in distributed environments. Despite its advantages, decentralized LLM fine-tuning remains underexplored. In this work, we propose \texttt{Dec-LoRA}, an algorithm for decentralized fine-tuning of LLMs based on low-rank adaptation (LoRA). Through extensive experiments on BERT and LLaMA-2 models, we evaluate \texttt{Dec-LoRA}'s performance in handling data heterogeneity and quantization constraints, enabling scalable, privacy-preserving LLM fine-tuning in decentralized settings.
Communication-Efficient and Tensorized Federated Fine-Tuning of Large Language Models
Oct 16, 2024Parameter-efficient fine-tuning (PEFT) methods typically assume that Large Language Models (LLMs) are trained on data from a single device or client. However, real-world scenarios often require fine-tuning these models on private data distributed across multiple devices. Federated Learning (FL) offers an appealing solution by preserving user privacy, as sensitive data remains on local devices during training. Nonetheless, integrating PEFT methods into FL introduces two main challenges: communication overhead and data heterogeneity. In this paper, we introduce FedTT and FedTT+, methods for adapting LLMs by integrating tensorized adapters into client-side models' encoder/decoder blocks. FedTT is versatile and can be applied to both cross-silo FL and large-scale cross-device FL. FedTT+, an extension of FedTT tailored for cross-silo FL, enhances robustness against data heterogeneity by adaptively freezing portions of tensor factors, further reducing the number of trainable parameters. Experiments on BERT and LLaMA models demonstrate that our proposed methods successfully address data heterogeneity challenges and perform on par or even better than existing federated PEFT approaches while achieving up to 10$\times$ reduction in communication cost.
Safe Online Convex Optimization with Multi-Point Feedback
Jul 16, 2024
Motivated by the stringent safety requirements that are often present in real-world applications, we study a safe online convex optimization setting where the player needs to simultaneously achieve sublinear regret and zero constraint violation while only using zero-order information. In particular, we consider a multi-point feedback setting, where the player chooses $d + 1$ points in each round (where $d$ is the problem dimension) and then receives the value of the constraint function and cost function at each of these points. To address this problem, we propose an algorithm that leverages forward-difference gradient estimation as well as optimistic and pessimistic action sets to achieve $\mathcal{O}(d \sqrt{T})$ regret and zero constraint violation under the assumption that the constraint function is smooth and strongly convex. We then perform a numerical study to investigate the impacts of the unknown constraint and zero-order feedback on empirical performance.
Robust Decentralized Learning with Local Updates and Gradient Tracking
May 02, 2024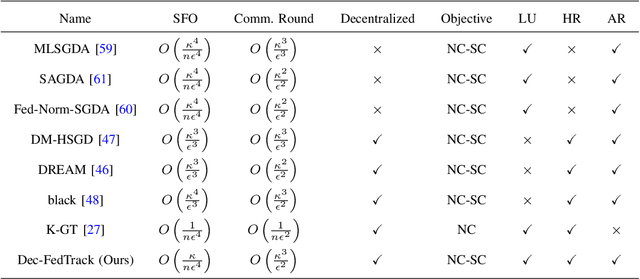
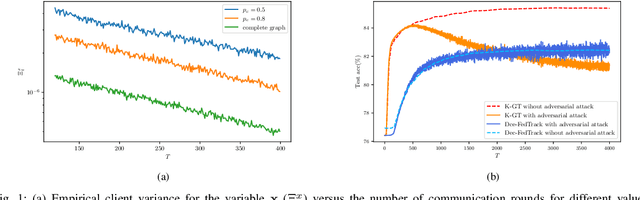
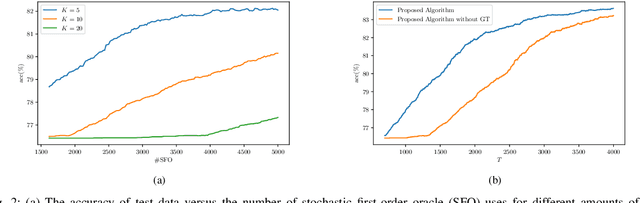
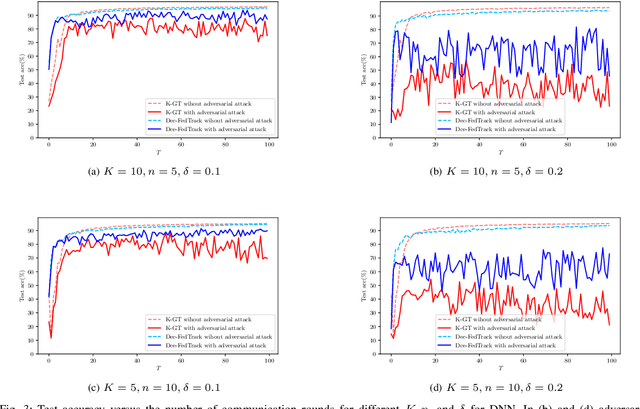
As distributed learning applications such as Federated Learning, the Internet of Things (IoT), and Edge Computing grow, it is critical to address the shortcomings of such technologies from a theoretical perspective. As an abstraction, we consider decentralized learning over a network of communicating clients or nodes and tackle two major challenges: data heterogeneity and adversarial robustness. We propose a decentralized minimax optimization method that employs two important modules: local updates and gradient tracking. Minimax optimization is the key tool to enable adversarial training for ensuring robustness. Having local updates is essential in Federated Learning (FL) applications to mitigate the communication bottleneck, and utilizing gradient tracking is essential to proving convergence in the case of data heterogeneity. We analyze the performance of the proposed algorithm, Dec-FedTrack, in the case of nonconvex-strongly concave minimax optimization, and prove that it converges a stationary point. We also conduct numerical experiments to support our theoretical findings.
Optimistic Safety for Linearly-Constrained Online Convex Optimization
Mar 09, 2024The setting of online convex optimization (OCO) under unknown constraints has garnered significant attention in recent years. In this work, we consider a version of this problem with static linear constraints that the player receives noisy feedback of and must always satisfy. By leveraging our novel design paradigm of optimistic safety, we give an algorithm for this problem that enjoys $\tilde{\mathcal{O}}(\sqrt{T})$ regret. This improves on the previous best regret bound of $\tilde{\mathcal{O}}(T^{2/3})$ while using only slightly stronger assumptions of independent noise and an oblivious adversary. Then, by recasting this problem as OCO under time-varying stochastic linear constraints, we show that our algorithm enjoys the same regret guarantees in such a setting and never violates the constraints in expectation. This contributes to the literature on OCO under time-varying stochastic constraints, where the state-of-the-art algorithms enjoy $\tilde{\mathcal{O}}(\sqrt{T})$ regret and $\tilde{\mathcal{O}}(\sqrt{T})$ violation when the constraints are convex and the player receives full feedback. Additionally, we provide a version of our algorithm that is more computationally efficient and give numerical experiments comparing it with benchmark algorithms.