 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Low-Rank Fine-Tuning of Large Language Models
Paper and Code
Jan 26, 2025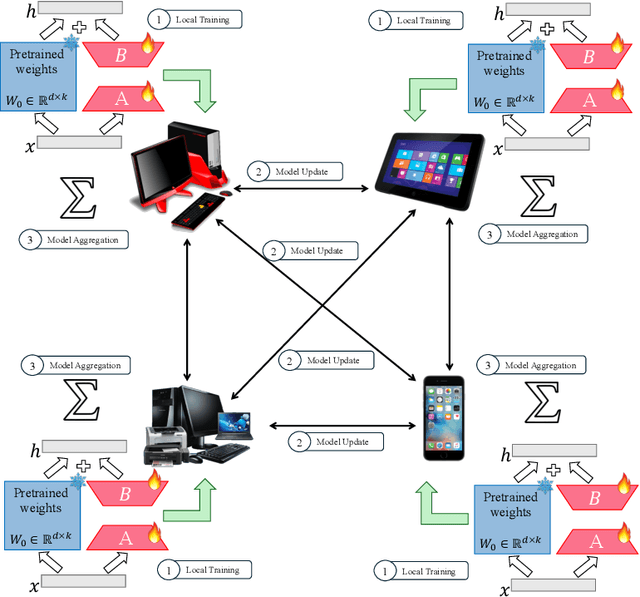

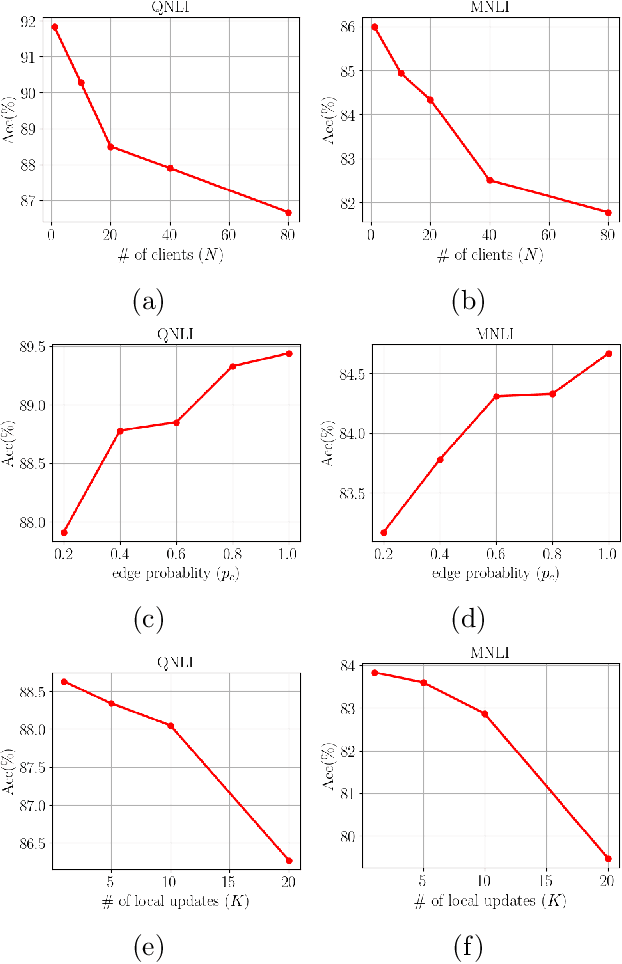

The emergence of Large Language Models (LLMs) such as GPT-4, LLaMA, and BERT has transformed artificial intelligence, enabling advanced capabilities across diverse applications. While parameter-efficient fine-tuning (PEFT) techniques like LoRA offer computationally efficient adaptations of these models, their practical deployment often assumes centralized data and training environments. However, real-world scenarios frequently involve distributed, privacy-sensitive datasets that require decentralized solutions. Federated learning (FL) addresses data privacy by coordinating model updates across clients, but it is typically based on centralized aggregation through a parameter server, which can introduce bottlenecks and communication constraints. Decentralized learning, in contrast, eliminates this dependency by enabling direct collaboration between clients, improving scalability and efficiency in distributed environments. Despite its advantages, decentralized LLM fine-tuning remains underexplored. In this work, we propose \texttt{Dec-LoRA}, an algorithm for decentralized fine-tuning of LLMs based on low-rank adaptation (LoRA). Through extensive experiments on BERT and LLaMA-2 models, we evaluate \texttt{Dec-LoRA}'s performance in handling data heterogeneity and quantization constraints, enabling scalable, privacy-preserving LLM fine-tuning in decentralized settings.