 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of the Geometric Properties of the Constraint Set in Safe Optimization with Bandit Feedback
Paper and Code
May 01, 2023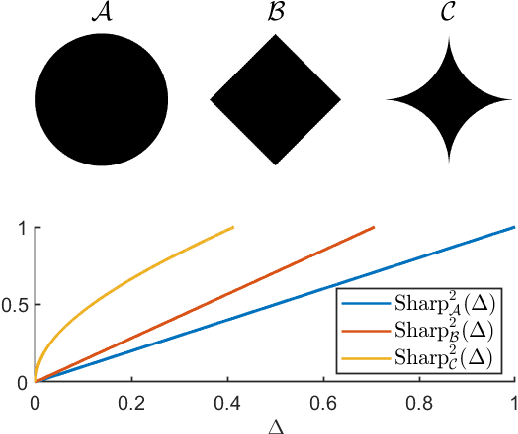
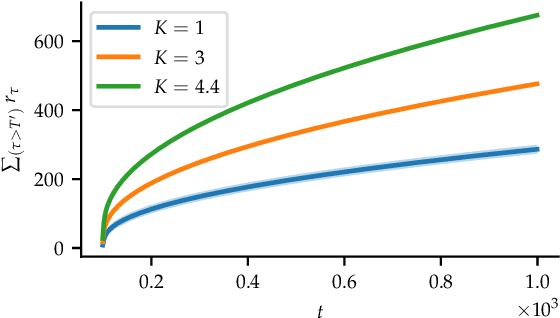
We consider a safe optimization problem with bandit feedback in which an agent sequentially chooses actions and observes responses from the environment, with the goal of maximizing an arbitrary function of the response while respecting stage-wise constraints. We propose an algorithm for this problem, and study how the geometric properties of the constraint set impact the regret of the algorithm. In order to do so, we introduce the notion of the sharpness of a particular constraint set, which characterizes the difficulty of performing learning within the constraint set in an uncertain setting. This concept of sharpness allows us to identify the class of constraint sets for which the proposed algorithm is guaranteed to enjoy sublinear regret. Simulation results for this algorithm support the sublinear regret bound and provide empirical evidence that the sharpness of the constraint set impacts the performance of the algorithm.