 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Neural Networks with Dynamic Time Steps for Vision Transformers
Paper and Code
Nov 28, 2023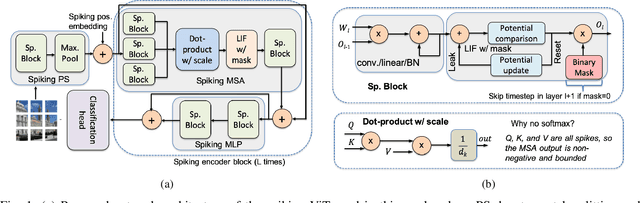
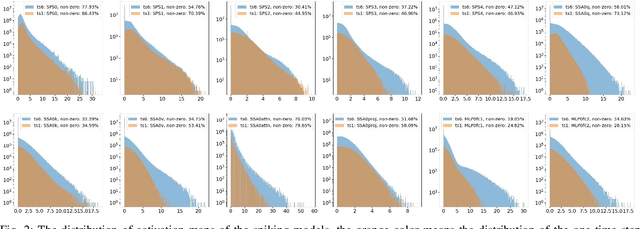
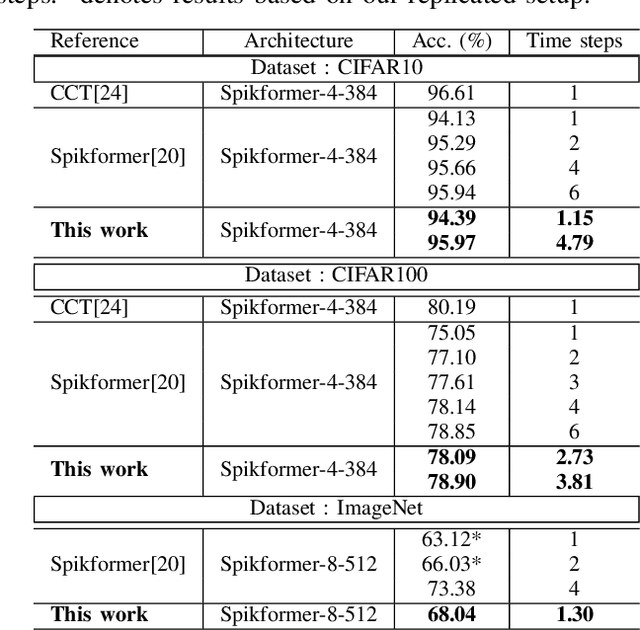
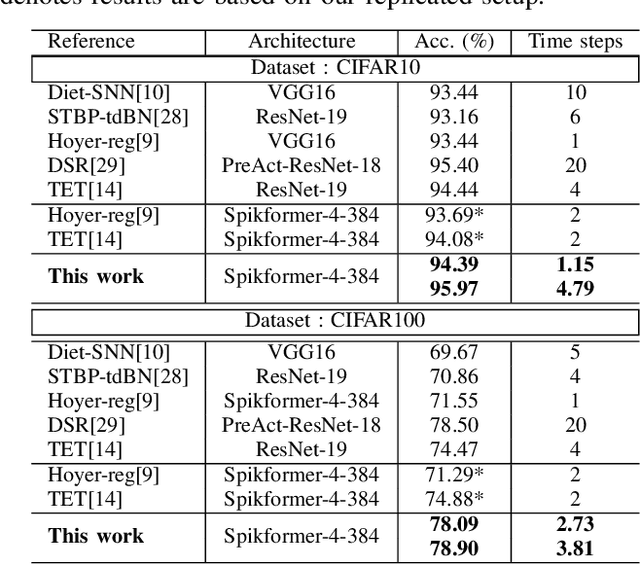
Spiking Neural Networks (SNNs) have emerged as a popular spatio-temporal computing paradigm for complex vision tasks. Recently proposed SNN training algorithms have significantly reduced the number of time steps (down to 1) for improved latency and energy efficiency, however, they target only convolutional neural networks (CNN). These algorithms, when applied on the recently spotlighted vision transformers (ViT), either require a large number of time steps or fail to converge. Based on analysis of the histograms of the ANN and SNN activation maps, we hypothesize that each ViT block has a different sensitivity to the number of time steps. We propose a novel training framework that dynamically allocates the number of time steps to each ViT module depending on a trainable score assigned to each timestep. In particular, we generate a scalar binary time step mask that filters spikes emitted by each neuron in a leaky-integrate-and-fire (LIF) layer. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), except for the input embedding layer, in contrast to expensive multiply-and-accumulates (MAC) needed in traditional ViTs. This yields significant improvements in energy efficiency. We evaluate our training framework and resulting SNNs on image recognition tasks including CIFAR10, CIFAR100, and ImageNet with different ViT architectures. We obtain a test accuracy of 95.97% with 4.97 time steps with direct encoding on CIFAR10.