 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMUFormer: Low Complexity Yet Powerful Spiking Model With Legendre Memory Units
Paper and Code

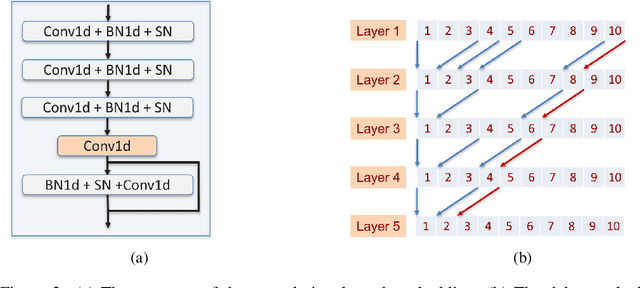
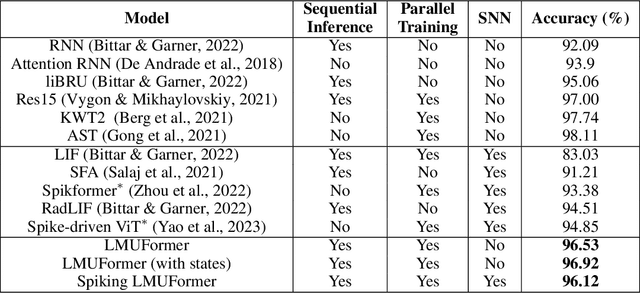
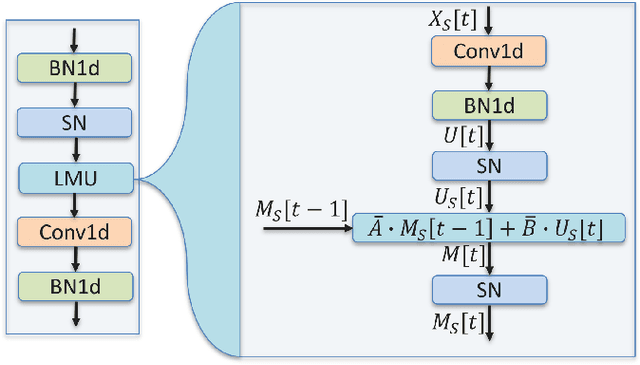
Transformer models have demonstrated high accuracy in numerous applications but have high complexity and lack sequential processing capability making them ill-suited for many streaming applications at the edge where devices are heavily resource-constrained. Thus motivated, many researchers have proposed reformulating the transformer models as RNN modules which modify the self-attention computation with explicit states. However, these approaches often incur significant performance degradation. The ultimate goal is to develop a model that has the following properties: parallel training, streaming and low-cost inference, and SOTA performance. In this paper, we propose a new direction to achieve this goal. We show how architectural modifications to a recurrent model can help push its performance toward Transformer models while retaining its sequential processing capability. Specifically, inspired by the recent success of Legendre Memory Units (LMU) in sequence learning tasks, we propose LMUFormer, which augments the LMU with convolutional patch embedding and convolutional channel mixer. Moreover, we present a spiking version of this architecture, which introduces the benefit of states within the patch embedding and channel mixer modules while simultaneously reducing the computing complexity. We evaluated our architectures on multiple sequence datasets. In comparison to SOTA transformer-based models within the ANN domain on the SCv2 dataset, our LMUFormer demonstrates comparable performance while necessitating a remarkable 53 times reduction in parameters and a substantial 65 times decrement in FLOPs. Additionally, owing to our model's proficiency in real-time data processing, we can achieve a 32.03% reduction in sequence length, all while incurring an inconsequential decline in performance. Our code is publicly available at https://github.com/zeyuliu1037/LMUFormer.git.