 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Language Model in LSTM for OCR
Paper and Code
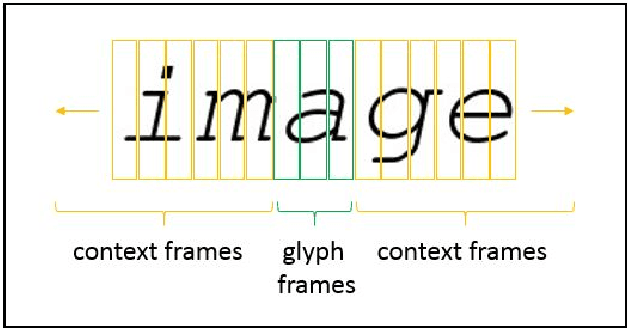
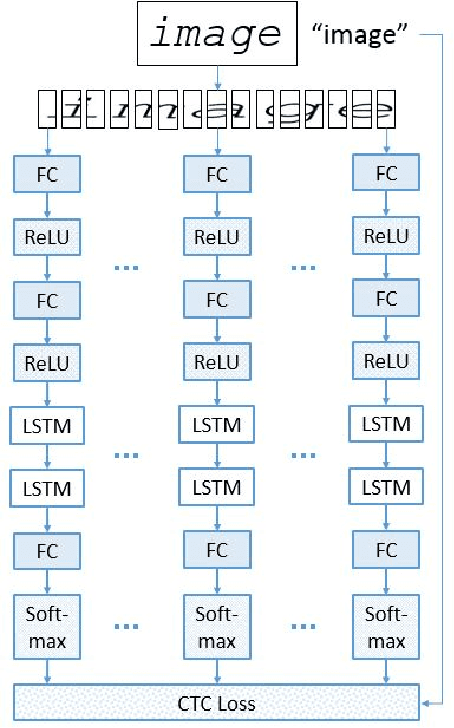
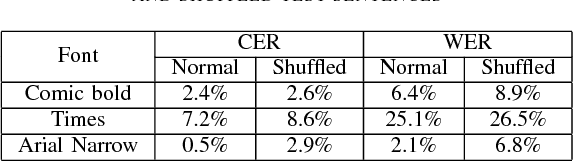
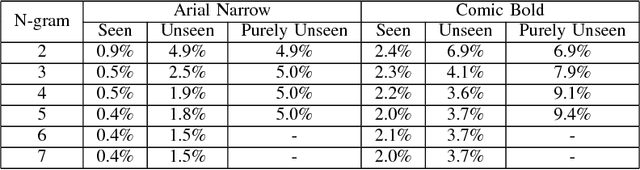
Neural networks have become the technique of choice for OCR, but many aspects of how and why they deliver superior performance are still unknown. One key difference between current neural network techniques using LSTMs and the previous state-of-the-art HMM systems is that HMM systems have a strong independence assumption. In comparison LSTMs have no explicit constraints on the amount of context that can be considered during decoding. In this paper we show that they learn an implicit LM and attempt to characterize the strength of the LM in terms of equivalent n-gram context. We show that this implicitly learned language model provides a 2.4\% CER improvement on our synthetic test set when compared against a test set of random characters (i.e. not naturally occurring sequences), and that the LSTM learns to use up to 5 characters of context (which is roughly 88 frames in our configuration). We believe that this is the first ever attempt at characterizing the strength of the implicit LM in LSTM based OCR systems.