 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Masking with Privacy Guarantees
Paper and Code
Jan 08, 2019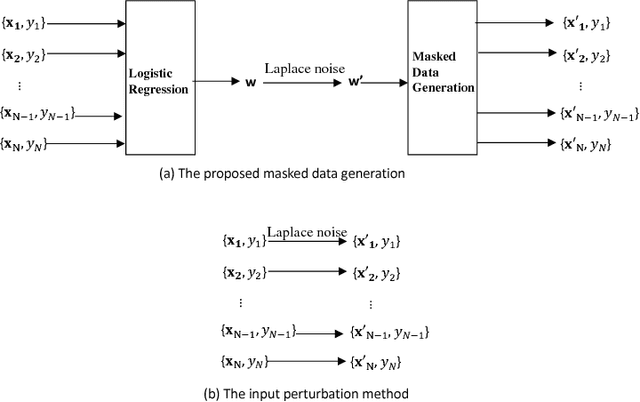
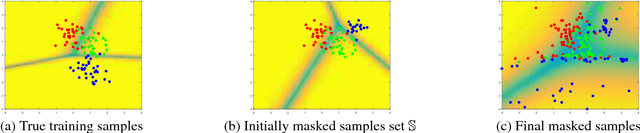


We study the problem of data release with privacy, where data is made available with privacy guarantees while keeping the usability of the data as high as possible --- this is important in health-care and other domains with sensitive data. In particular, we propose a method of masking the private data with privacy guarantee while ensuring that a classifier trained on the masked data is similar to the classifier trained on the original data, to maintain usability. We analyze the theoretical risks of the proposed method and the traditional input perturbation method. Results show that the proposed method achieves lower risk compared to the input perturbation, especially when the number of training samples gets large. We illustrate the effectiveness of the proposed method of data masking for privacy-sensitive learning on $12$ benchmark datasets.