 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs nasty noise actually harder than malicious noise?
Nov 12, 2025We consider the relative abilities and limitations of computationally efficient algorithms for learning in the presence of noise, under two well-studied and challenging adversarial noise models for learning Boolean functions: malicious noise, in which an adversary can arbitrarily corrupt a random subset of examples given to the learner; and nasty noise, in which an adversary can arbitrarily corrupt an adversarially chosen subset of examples given to the learner. We consider both the distribution-independent and fixed-distribution settings. Our main results highlight a dramatic difference between these two settings: For distribution-independent learning, we prove a strong equivalence between the two noise models: If a class ${\cal C}$ of functions is efficiently learnable in the presence of $η$-rate malicious noise, then it is also efficiently learnable in the presence of $η$-rate nasty noise. In sharp contrast, for the fixed-distribution setting we show an arbitrarily large separation: Under a standard cryptographic assumption, for any arbitrarily large value $r$ there exists a concept class for which there is a ratio of $r$ between the rate $η_{malicious}$ of malicious noise that polynomial-time learning algorithms can tolerate, versus the rate $η_{nasty}$ of nasty noise that such learning algorithms can tolerate. To offset the negative result for the fixed-distribution setting, we define a broad and natural class of algorithms, namely those that ignore contradictory examples (ICE). We show that for these algorithms, malicious noise and nasty noise are equivalent up to a factor of two in the noise rate: Any efficient ICE learner that succeeds with $η$-rate malicious noise can be converted to an efficient learner that succeeds with $η/2$-rate nasty noise. We further show that the above factor of two is necessary, again under a standard cryptographic assumption.
Provably Robust Watermarks for Open-Source Language Models
Oct 24, 2024

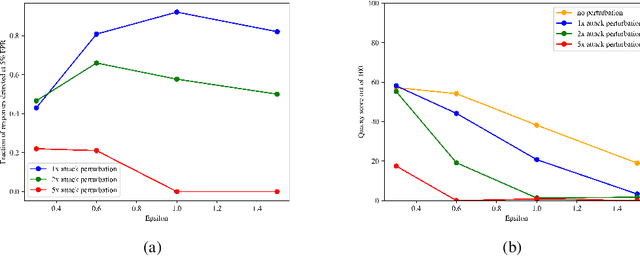

The recent explosion of high-quality language models has necessitated new methods for identifying AI-generated text. Watermarking is a leading solution and could prove to be an essential tool in the age of generative AI. Existing approaches embed watermarks at inference and crucially rely on the large language model (LLM) specification and parameters being secret, which makes them inapplicable to the open-source setting. In this work, we introduce the first watermarking scheme for open-source LLMs. Our scheme works by modifying the parameters of the model, but the watermark can be detected from just the outputs of the model. Perhaps surprisingly, we prove that our watermarks are unremovable under certain assumptions about the adversary's knowledge. To demonstrate the behavior of our construction under concrete parameter instantiations, we present experimental results with OPT-6.7B and OPT-1.3B. We demonstrate robustness to both token substitution and perturbation of the model parameters. We find that the stronger of these attacks, the model-perturbation attack, requires deteriorating the quality score to 0 out of 100 in order to bring the detection rate down to 50%.