 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFleet Control using Coregionalized Gaussian Process Policy Iteration
Nov 22, 2019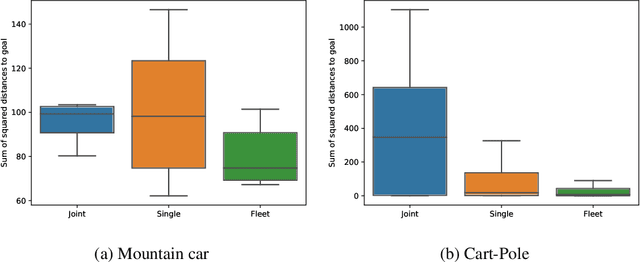
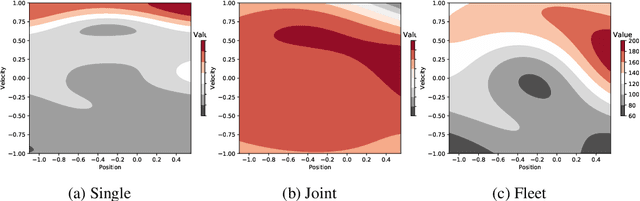
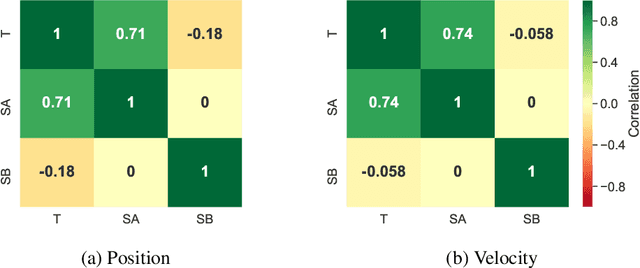
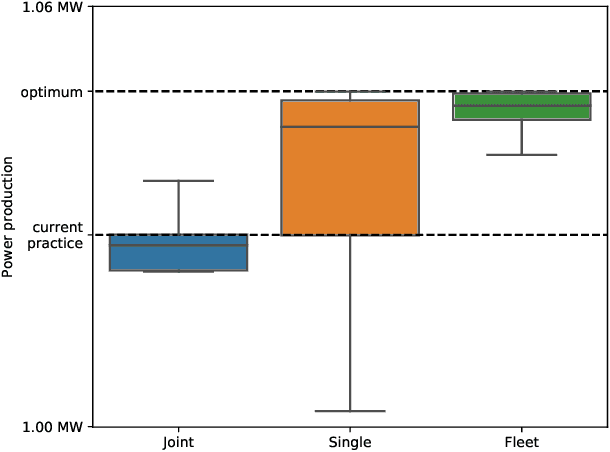
In many settings, as for example wind farms, multiple machines are instantiated to perform the same task, which is called a fleet. The recent advances with respect to the Internet of Things allow control devices and/or machines to connect through cloud-based architectures in order to share information about their status and environment. Such an infrastructure allows seamless data sharing between fleet members, which could greatly improve the sample-efficiency of reinforcement learning techniques. However in practice, these machines, while almost identical in design, have small discrepancies due to production errors or degradation, preventing control algorithms to simply aggregate and employ all fleet data. We propose a novel reinforcement learning method that learns to transfer knowledge between similar fleet members and creates member-specific dynamics models for control. Our algorithm uses Gaussian processes to establish cross-member covariances. This is significantly different from standard transfer learning methods, as the focus is not on sharing information over tasks, but rather over system specifications. We demonstrate our approach on two benchmarks and a realistic wind farm setting. Our method significantly outperforms two baseline approaches, namely individual learning and joint learning where all samples are aggregated, in terms of the median and variance of the results.
Thompson Sampling for Factored Multi-Agent Bandits
Nov 22, 2019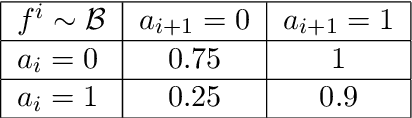
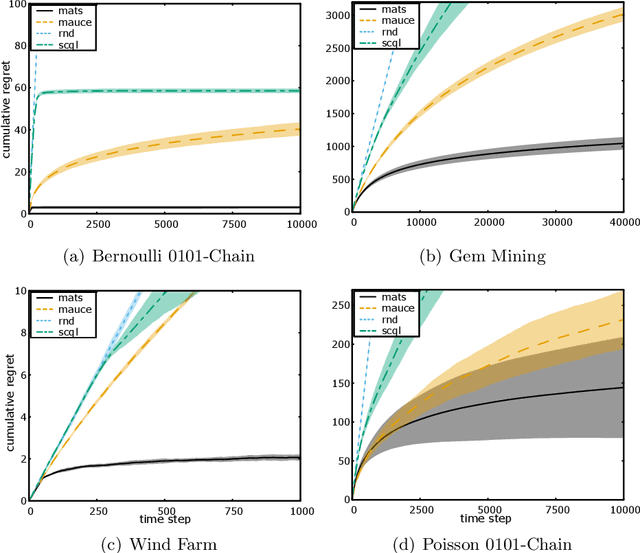
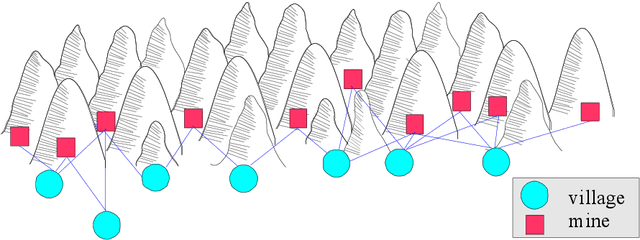
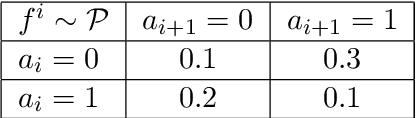
Multi-agent coordination is prevalent in many real-world applications. However, such coordination is challenging due to its combinatorial nature. An important observation in this regard is that agents in the real world often only directly affect a limited set of neighboring agents. Leveraging such loose couplings among agents is key to making coordination in multi-agent systems feasible. In this work, we focus on learning to coordinate. Specifically, we consider the multi-agent multi-armed bandit framework, in which fully cooperative loosely-coupled agents must learn to coordinate their decisions to optimize a common objective. As opposed to in the planning setting, for learning methods it is challenging to establish theoretical guarantees. We propose multi-agent Thompson sampling (MATS), a new Bayesian exploration-exploitation algorithm that leverages loose couplings. We provide a regret bound that is sublinear in time and low-order polynomial in the highest number of actions of a single agent for sparse coordination graphs. Finally, we empirically show that MATS outperforms the state-of-the-art algorithm, MAUCE, on two synthetic benchmarks, a realistic wind farm control task, and a novel benchmark with Poisson distributions.