 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLATR: Enhance Multi-stage Text Retrieval with Hybrid List Aware Transformer Reranking
Paper and Code
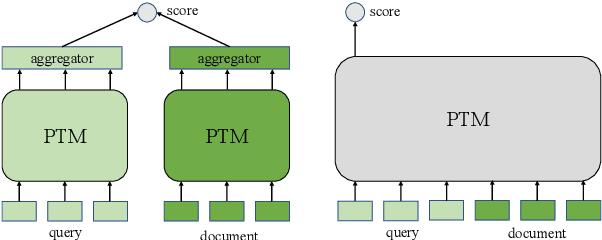
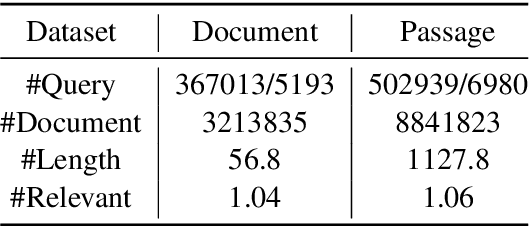
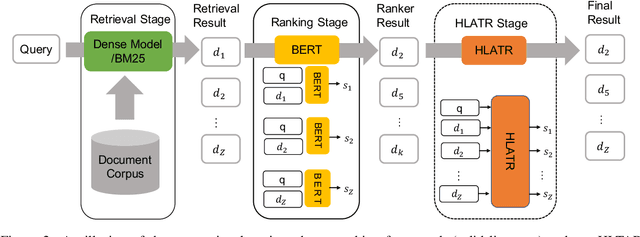
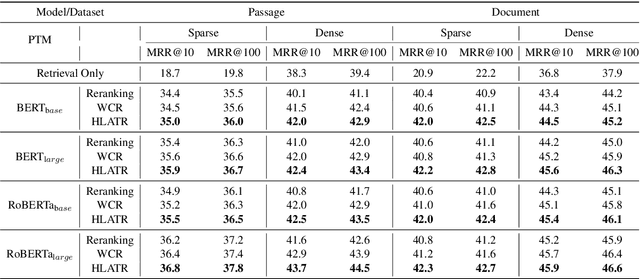
Deep pre-trained language models (e,g. BERT) are effective at large-scale text retrieval task. Existing text retrieval systems with state-of-the-art performance usually adopt a retrieve-then-reranking architecture due to the high computational cost of pre-trained language models and the large corpus size. Under such a multi-stage architecture, previous studies mainly focused on optimizing single stage of the framework thus improving the overall retrieval performance. However, how to directly couple multi-stage features for optimization has not been well studied. In this paper, we design Hybrid List Aware Transformer Reranking (HLATR) as a subsequent reranking module to incorporate both retrieval and reranking stage features. HLATR is lightweight and can be easily parallelized with existing text retrieval systems so that the reranking process can be performed in a single yet efficient processing. Empirical experiments on two large-scale text retrieval datasets show that HLATR can efficiently improve the ranking performance of existing multi-stage text retrieval methods.