 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 5th Recognizing Families in the Wild Data Challenge: Predicting Kinship from Faces
Nov 26, 2021

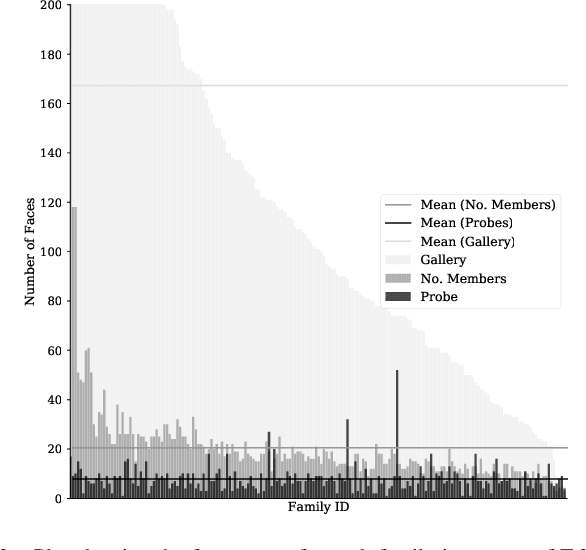

Recognizing Families In the Wild (RFIW), held as a data challenge in conjunction with the 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG), is a large-scale, multi-track visual kinship recognition evaluation. For the fifth edition of RFIW, we continue to attract scholars, bring together professionals, publish new work, and discuss prospects. In this paper, we summarize submissions for the three tasks of this year's RFIW: specifically, we review the results for kinship verification, tri-subject verification, and family member search and retrieval. We look at the RFIW problem, share current efforts, and make recommendations for promising future directions.
Multimodal In-bed Pose and Shape Estimation under the Blankets
Dec 12, 2020
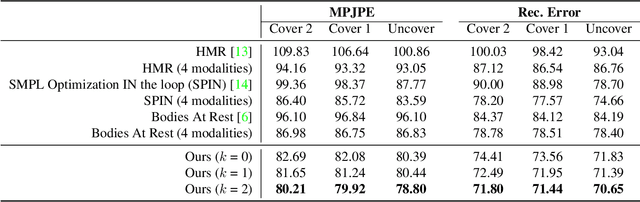


Humans spend vast hours in bed -- about one-third of the lifetime on average. Besides, a human at rest is vital in many healthcare applications. Typically, humans are covered by a blanket when resting, for which we propose a multimodal approach to uncover the subjects so their bodies at rest can be viewed without the occlusion of the blankets above. We propose a pyramid scheme to effectively fuse the different modalities in a way that best leverages the knowledge captured by the multimodal sensors. Specifically, the two most informative modalities (i.e., depth and infrared images) are first fused to generate good initial pose and shape estimation. Then pressure map and RGB images are further fused one by one to refine the result by providing occlusion-invariant information for the covered part, and accurate shape information for the uncovered part, respectively. However, even with multimodal data, the task of detecting human bodies at rest is still very challenging due to the extreme occlusion of bodies. To further reduce the negative effects of the occlusion from blankets, we employ an attention-based reconstruction module to generate uncovered modalities, which are further fused to update current estimation via a cyclic fashion. Extensive experiments validate the superiority of the proposed model over others.
SuperFront: From Low-resolution to High-resolution Frontal Face Synthesis
Dec 07, 2020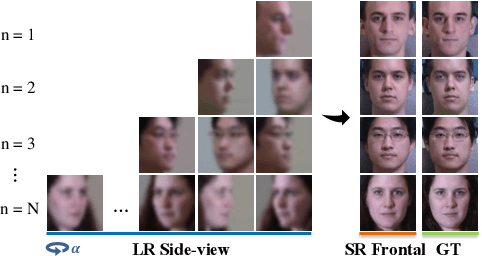
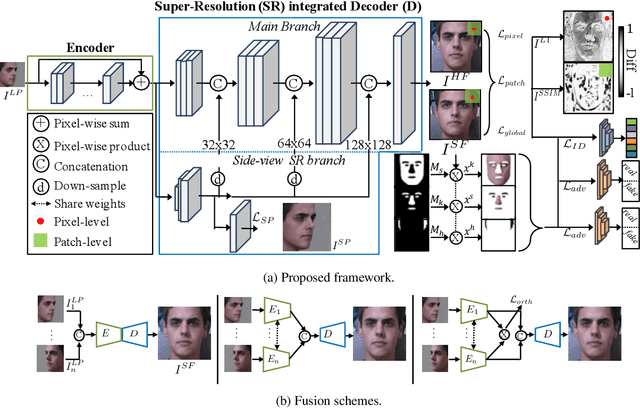
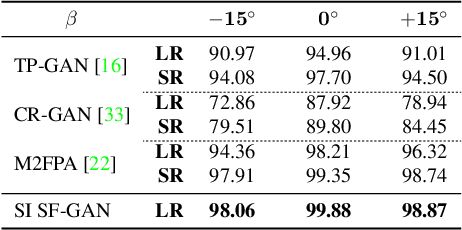
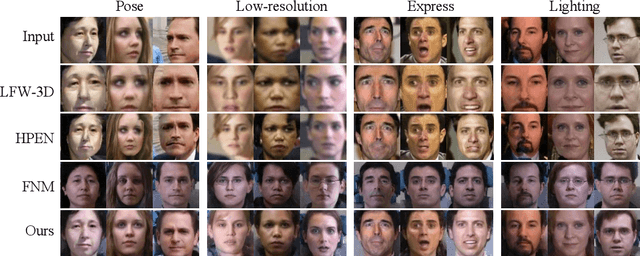
Advances in face rotation, along with other face-based generative tasks, are more frequent as we advance further in topics of deep learning. Even as impressive milestones are achieved in synthesizing faces, the importance of preserving identity is needed in practice and should not be overlooked. Also, the difficulty should not be more for data with obscured faces, heavier poses, and lower quality. Existing methods tend to focus on samples with variation in pose, but with the assumption data is high in quality. We propose a generative adversarial network (GAN) -based model to generate high-quality, identity preserving frontal faces from one or multiple low-resolution (LR) faces with extreme poses. Specifically, we propose SuperFront-GAN (SF-GAN) to synthesize a high-resolution (HR), frontal face from one-to-many LR faces with various poses and with the identity-preserved. We integrate a super-resolution (SR) side-view module into SF-GAN to preserve identity information and fine details of the side-views in HR space, which helps model reconstruct high-frequency information of faces (i.e., periocular, nose, and mouth regions). Moreover, SF-GAN accepts multiple LR faces as input, and improves each added sample. We squeeze additional gain in performance with an orthogonal constraint in the generator to penalize redundant latent representations and, hence, diversify the learned features space. Quantitative and qualitative results demonstrate the superiority of SF-GAN over others.
Families In Wild Multimedia : A Multi-Modal Database for Recognizing Kinship
Jul 28, 2020



Recognizing kinship - a soft biometric with vast applications - in photos has piqued the interest of many machine vision researchers. The large-scale Families In the Wild (FIW) database promoted the problem by supporting annual kinship-based vision challenges that saw consistent performance improvements. We have now begun to approach performance levels for image-based systems acceptable for practical use - something unforeseeable a decade ago. However, biometric systems can benefit from multi-modal perspectives, as information contained in multimedia can add to and complement that of still images. Thus, we aim to narrow the gap from research-to-reality by extending FIW with multimedia data (i.e., video, audio, and contextual transcripts). Specifically, we introduce the first large-scale dataset for recognizing kinship in multimedia, the FIW in Multimedia (FIW-MM) database. We utilize automated machinery to collect, annotate, and prepare the data with minimal human input and no financial cost. This large-scale, multimedia corpus allows problem formulations to follow more realistic template-based protocols. We show significant improvements in benchmarks for multiple kin-based tasks when additional media-types are added. Experiments provide insights by highlighting edge cases to inspire future research and areas of improvement. Emphasis is put on short and long-term research directions, with the overarching intent to increase the potential of systems built to automatically detect kinship in multimedia. Furthermore, we expect a broader range of researchers with recognition tasks, generative modeling, speech understanding, and nature-based narratives.
Recognizing Families In the Wild : The 4th Edition
Mar 09, 2020

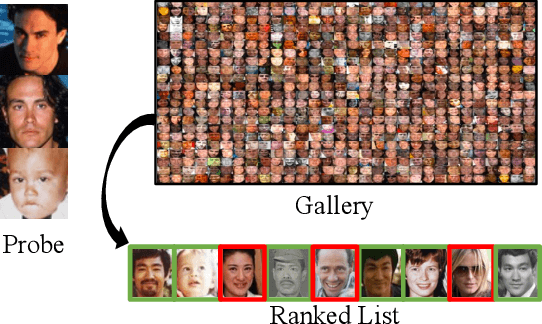
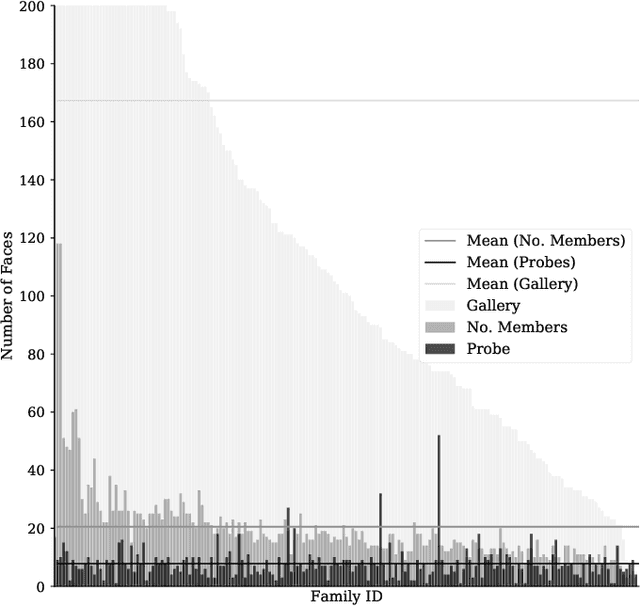
Recognizing Families In the Wild (RFIW): an annual large-scale, multi-track automatic kinship recognition evaluation that supports various visual kin-based problems on scales much higher than ever before. Organized in conjunction with the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG) as a Challenge, RFIW provides a platform for publishing original work and the gathering of experts for a discussion of the next steps. This paper summarizes the supported tasks (i.e., kinship verification, tri-subject verification, and search & retrieval of missing children) in the evaluation protocols, which include the practical motivation, technical background, data splits, metrics, and benchmark results. Furthermore, top submissions (i.e., leader-board stats) are listed and reviewed as a high-level analysis on the state of the problem. In the end, the purpose of this paper is to describe the 2020 RFIW challenge, end-to-end, along with forecasts in promising future directions.
Dual-Attention GAN for Large-Pose Face Frontalization
Feb 17, 2020
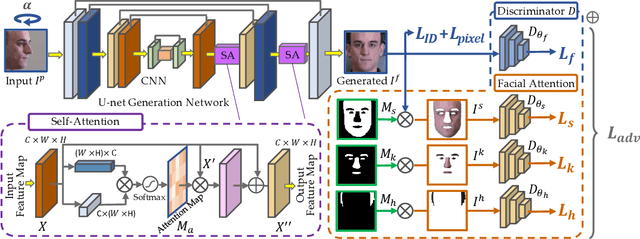


Face frontalization provides an effective and efficient way for face data augmentation and further improves the face recognition performance in extreme pose scenario. Despite recent advances in deep learning-based face synthesis approaches, this problem is still challenging due to significant pose and illumination discrepancy. In this paper, we present a novel Dual-Attention Generative Adversarial Network (DA-GAN) for photo-realistic face frontalization by capturing both contextual dependencies and local consistency during GAN training. Specifically, a self-attention-based generator is introduced to integrate local features with their long-range dependencies yielding better feature representations, and hence generate faces that preserve identities better, especially for larger pose angles. Moreover, a novel face-attention-based discriminator is applied to emphasize local features of face regions, and hence reinforce the realism of synthetic frontal faces. Guided by semantic segmentation, four independent discriminators are used to distinguish between different aspects of a face (\ie skin, keypoints, hairline, and frontalized face). By introducing these two complementary attention mechanisms in generator and discriminator separately, we can learn a richer feature representation and generate identity preserving inference of frontal views with much finer details (i.e., more accurate facial appearance and textures) comparing to the state-of-the-art. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our DA-GAN approach.
Joint Super-Resolution and Alignment of Tiny Faces
Nov 19, 2019



Super-resolution (SR) and landmark localization of tiny faces are highly correlated tasks. On the one hand, landmark localization could obtain higher accuracy with faces of high-resolution (HR). On the other hand, face SR would benefit from prior knowledge of facial attributes such as landmarks. Thus, we propose a joint alignment and SR network to simultaneously detect facial landmarks and super-resolve tiny faces. More specifically, a shared deep encoder is applied to extract features for both tasks by leveraging complementary information. To exploit the representative power of the hierarchical encoder, intermediate layers of a shared feature extraction module are fused to form efficient feature representations. The fused features are then fed to task-specific modules to detect landmarks and super-resolve face images in parallel. Extensive experiments demonstrate that the proposed model significantly outperforms the state-of-the-art in both landmark localization and SR of faces. We show a large improvement for landmark localization of tiny faces (i.e., 16*16). Furthermore, the proposed framework yields comparable results for landmark localization on low-resolution (LR) faces (i.e., 64*64) to existing methods on HR (i.e., 256*256). As for SR, the proposed method recovers sharper edges and more details from LR face images than other state-of-the-art methods, which we demonstrate qualitatively and quantitatively.
Families in the Wild : Large-Scale Kinship Image Database and Benchmarks
May 04, 2017


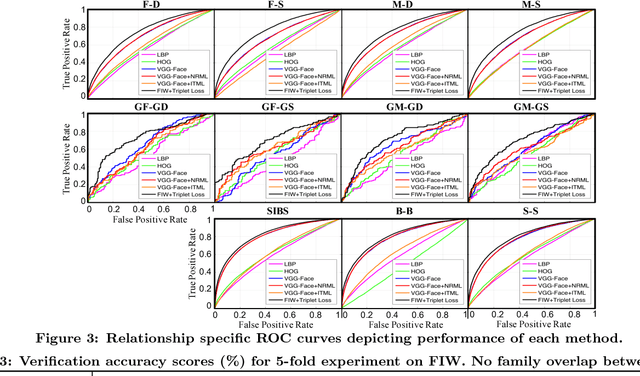
We present the largest kinship recognition dataset to date, Families in the Wild (FIW). Motivated by the lack of a single, unified dataset for kinship recognition, we aim to provide a dataset that captivates the interest of the research community. With only a small team, we were able to collect, organize, and label over 10,000 family photos of 1,000 families with our annotation tool designed to mark complex hierarchical relationships and local label information in a quick and efficient manner. We include several benchmarks for two image-based tasks, kinship verification and family recognition. For this, we incorporate several visual features and metric learning methods as baselines. Also, we demonstrate that a pre-trained Convolutional Neural Network (CNN) as an off-the-shelf feature extractor outperforms the other feature types. Then, results were further boosted by fine-tuning two deep CNNs on FIW data: (1) for kinship verification, a triplet loss function was learned on top of the network of pre-trained weights; (2) for family recognition, a family-specific softmax classifier was added to the network.