 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtualEnv: A Platform for Embodied AI Research
Jan 12, 2026As large language models (LLMs) continue to improve in reasoning and decision-making, there is a growing need for realistic and interactive environments where their abilities can be rigorously evaluated. We present VirtualEnv, a next-generation simulation platform built on Unreal Engine 5 that enables fine-grained benchmarking of LLMs in embodied and interactive scenarios. VirtualEnv supports rich agent-environment interactions, including object manipulation, navigation, and adaptive multi-agent collaboration, as well as game-inspired mechanics like escape rooms and procedurally generated environments. We provide a user-friendly API built on top of Unreal Engine, allowing researchers to deploy and control LLM-driven agents using natural language instructions. We integrate large-scale LLMs and vision-language models (VLMs), such as GPT-based models, to generate novel environments and structured tasks from multimodal inputs. Our experiments benchmark the performance of several popular LLMs across tasks of increasing complexity, analyzing differences in adaptability, planning, and multi-agent coordination. We also describe our methodology for procedural task generation, task validation, and real-time environment control. VirtualEnv is released as an open-source platform, we aim to advance research at the intersection of AI and gaming, enable standardized evaluation of LLMs in embodied AI settings, and pave the way for future developments in immersive simulations and interactive entertainment.
Recognizing Families In the Wild : The 4th Edition
Mar 09, 2020

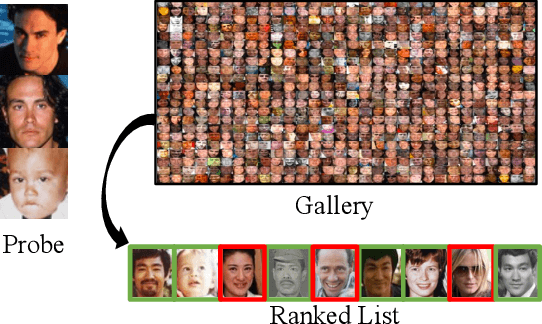
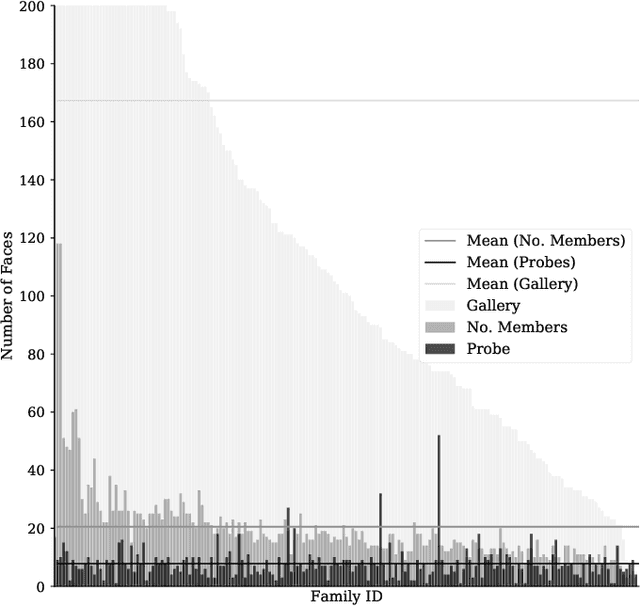
Recognizing Families In the Wild (RFIW): an annual large-scale, multi-track automatic kinship recognition evaluation that supports various visual kin-based problems on scales much higher than ever before. Organized in conjunction with the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG) as a Challenge, RFIW provides a platform for publishing original work and the gathering of experts for a discussion of the next steps. This paper summarizes the supported tasks (i.e., kinship verification, tri-subject verification, and search & retrieval of missing children) in the evaluation protocols, which include the practical motivation, technical background, data splits, metrics, and benchmark results. Furthermore, top submissions (i.e., leader-board stats) are listed and reviewed as a high-level analysis on the state of the problem. In the end, the purpose of this paper is to describe the 2020 RFIW challenge, end-to-end, along with forecasts in promising future directions.