 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dual Mechanisms of Spatial Reasoning in Vision-Language Models
Mar 23, 2026Many multimodal tasks, such as image captioning and visual question answering, require vision-language models (VLMs) to associate objects with their properties and spatial relations. Yet it remains unclear where and how such associations are computed within VLMs. In this work, we show that VLMs rely on two concurrent mechanisms to represent such associations. In the language model backbone, intermediate layers represent content-independent spatial relations on top of visual tokens corresponding to objects. However, this mechanism plays only a secondary role in shaping model predictions. Instead, the dominant source of spatial information originates in the vision encoder, whose representations encode the layout of objects and are directly exploited by the language model backbone. Notably, this spatial signal is distributed globally across visual tokens, extending beyond object regions into surrounding background areas. We show that enhancing these vision-derived spatial representations globally across all image tokens improves spatial reasoning performance on naturalistic images. Together, our results clarify how spatial association is computed within VLMs and highlight the central role of vision encoders in enabling spatial reasoning.
VirtualEnv: A Platform for Embodied AI Research
Jan 12, 2026As large language models (LLMs) continue to improve in reasoning and decision-making, there is a growing need for realistic and interactive environments where their abilities can be rigorously evaluated. We present VirtualEnv, a next-generation simulation platform built on Unreal Engine 5 that enables fine-grained benchmarking of LLMs in embodied and interactive scenarios. VirtualEnv supports rich agent-environment interactions, including object manipulation, navigation, and adaptive multi-agent collaboration, as well as game-inspired mechanics like escape rooms and procedurally generated environments. We provide a user-friendly API built on top of Unreal Engine, allowing researchers to deploy and control LLM-driven agents using natural language instructions. We integrate large-scale LLMs and vision-language models (VLMs), such as GPT-based models, to generate novel environments and structured tasks from multimodal inputs. Our experiments benchmark the performance of several popular LLMs across tasks of increasing complexity, analyzing differences in adaptability, planning, and multi-agent coordination. We also describe our methodology for procedural task generation, task validation, and real-time environment control. VirtualEnv is released as an open-source platform, we aim to advance research at the intersection of AI and gaming, enable standardized evaluation of LLMs in embodied AI settings, and pave the way for future developments in immersive simulations and interactive entertainment.
Behavioural Cloning in VizDoom
Jan 08, 2024This paper describes methods for training autonomous agents to play the game "Doom 2" through Imitation Learning (IL) using only pixel data as input. We also explore how Reinforcement Learning (RL) compares to IL for humanness by comparing camera movement and trajectory data. Through behavioural cloning, we examine the ability of individual models to learn varying behavioural traits. We attempt to mimic the behaviour of real players with different play styles, and find we can train agents that behave aggressively, passively, or simply more human-like than traditional AIs. We propose these methods of introducing more depth and human-like behaviour to agents in video games. The trained IL agents perform on par with the average players in our dataset, whilst outperforming the worst players. While performance was not as strong as common RL approaches, it provides much stronger human-like behavioural traits to the agent.
Learning to design without prior data: Discovering generalizable design strategies using deep learning and tree search
Nov 28, 2022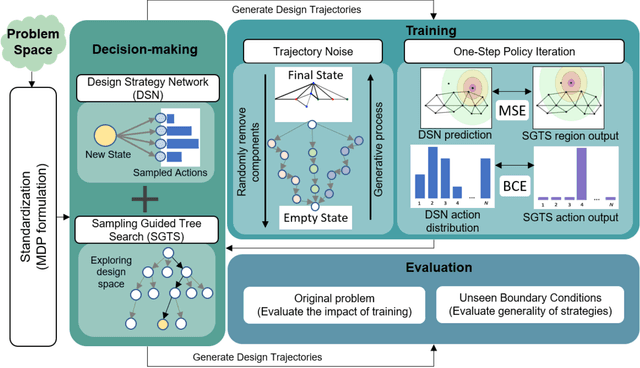
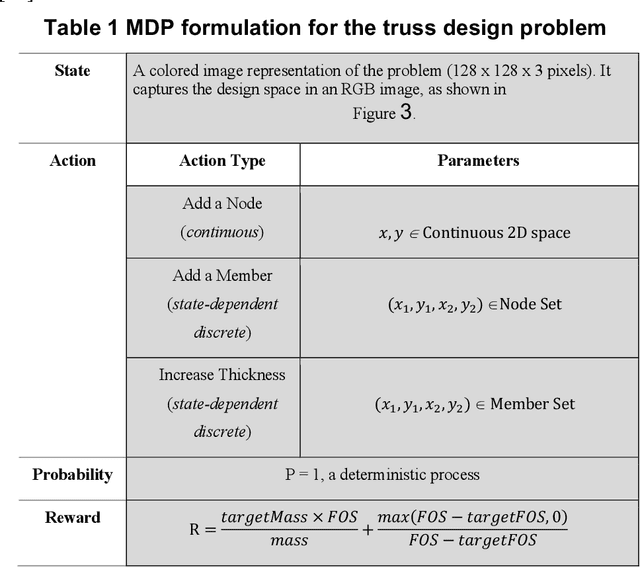

Building an AI agent that can design on its own has been a goal since the 1980s. Recently, deep learning has shown the ability to learn from large-scale data, enabling significant advances in data-driven design. However, learning over prior data limits us only to solve problems that have been solved before and biases data-driven learning towards existing solutions. The ultimate goal for a design agent is the ability to learn generalizable design behavior in a problem space without having seen it before. We introduce a self-learning agent framework in this work that achieves this goal. This framework integrates a deep policy network with a novel tree search algorithm, where the tree search explores the problem space, and the deep policy network leverages self-generated experience to guide the search further. This framework first demonstrates an ability to discover high-performing generative strategies without any prior data, and second, it illustrates a zero-shot generalization of generative strategies across various unseen boundary conditions. This work evaluates the effectiveness and versatility of the framework by solving multiple versions of two engineering design problems without retraining. Overall, this paper presents a methodology to self-learn high-performing and generalizable problem-solving behavior in an arbitrary problem space, circumventing the needs for expert data, existing solutions, and problem-specific learning.
Design Strategy Network: A deep hierarchical framework to represent generative design strategies in complex action spaces
Oct 07, 2021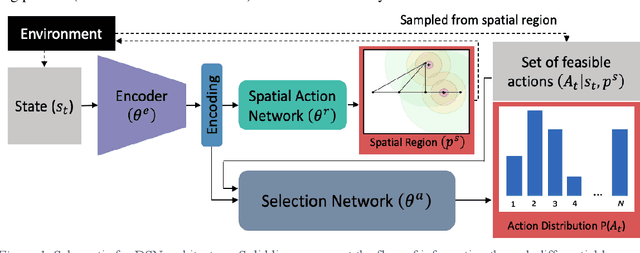
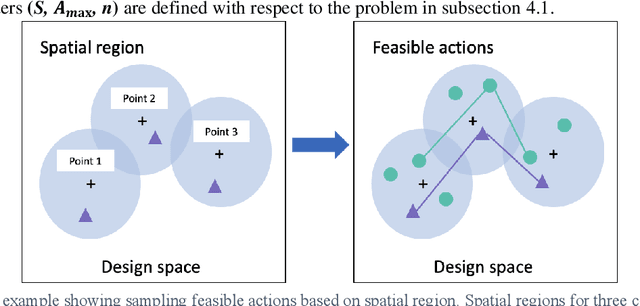

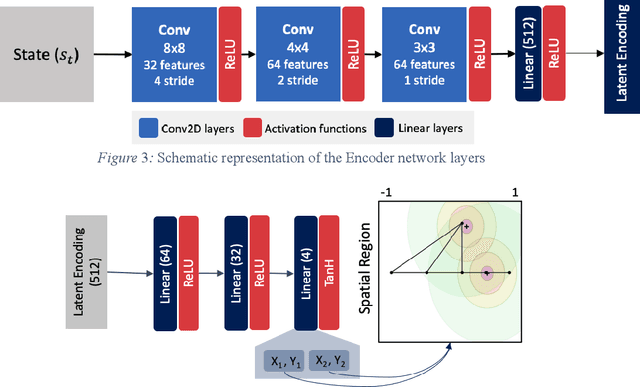
Generative design problems often encompass complex action spaces that may be divergent over time, contain state-dependent constraints, or involve hybrid (discrete and continuous) domains. To address those challenges, this work introduces Design Strategy Network (DSN), a data-driven deep hierarchical framework that can learn strategies over these arbitrary complex action spaces. The hierarchical architecture decomposes every action decision into first predicting a preferred spatial region in the design space and then outputting a probability distribution over a set of possible actions from that region. This framework comprises a convolutional encoder to work with image-based design state representations, a multi-layer perceptron to predict a spatial region, and a weight-sharing network to generate a probability distribution over unordered set-based inputs of feasible actions. Applied to a truss design study, the framework learns to predict the actions of human designers in the study, capturing their truss generation strategies in the process. Results show that DSNs significantly outperform non-hierarchical methods of policy representation, demonstrating their superiority in complex action space problems.
* Published in Journal of Mechanical Design
Goal-Directed Design Agents: Integrating Visual Imitation with One-Step Lookahead Optimization for Generative Design
Oct 07, 2021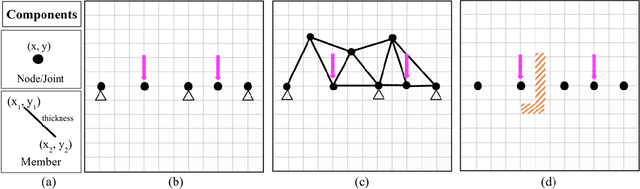

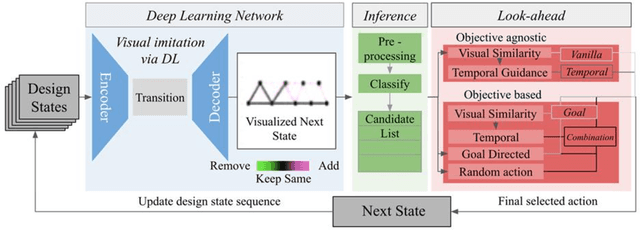
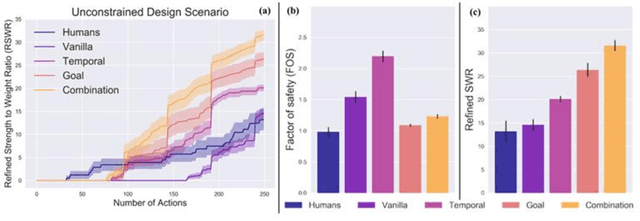
Engineering design problems often involve large state and action spaces along with highly sparse rewards. Since an exhaustive search of those spaces is not feasible, humans utilize relevant domain knowledge to condense the search space. Previously, deep learning agents (DLAgents) were introduced to use visual imitation learning to model design domain knowledge. This note builds on DLAgents and integrates them with one-step lookahead search to develop goal-directed agents capable of enhancing learned strategies for sequentially generating designs. Goal-directed DLAgents can employ human strategies learned from data along with optimizing an objective function. The visual imitation network from DLAgents is composed of a convolutional encoder-decoder network, acting as a rough planning step that is agnostic to feedback. Meanwhile, the lookahead search identifies the fine-tuned design action guided by an objective. These design agents are trained on an unconstrained truss design problem that is modeled as a sequential, action-based configuration design problem. The agents are then evaluated on two versions of the problem: the original version used for training and an unseen constrained version with an obstructed construction space. The goal-directed agents outperform the human designers used to train the network as well as the previous objective-agnostic versions of the agent in both scenarios. This illustrates a design agent framework that can efficiently use feedback to not only enhance learned design strategies but also adapt to unseen design problems.
Learning to design from humans: Imitating human designers through deep learning
Aug 02, 2019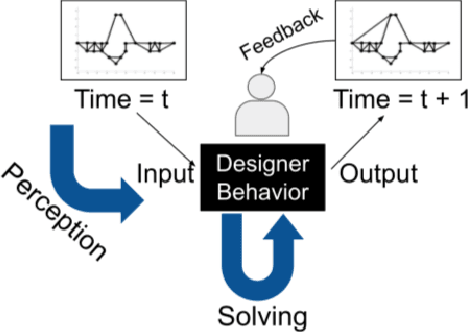
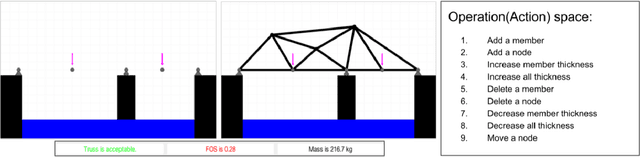
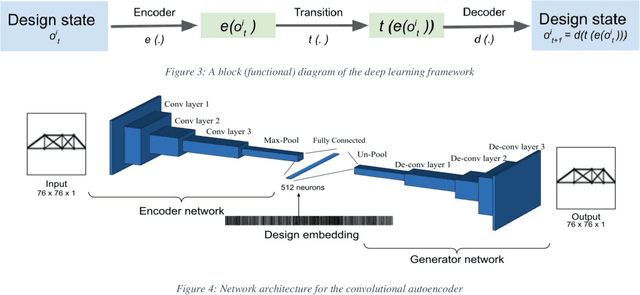

Humans as designers have quite versatile problem-solving strategies. Computer agents on the other hand can access large scale computational resources to solve certain design problems. Hence, if agents can learn from human behavior, a synergetic human-agent problem solving team can be created. This paper presents an approach to extract human design strategies and implicit rules, purely from historical human data, and use that for design generation. A two-step framework that learns to imitate human design strategies from observation is proposed and implemented. This framework makes use of deep learning constructs to learn to generate designs without any explicit information about objective and performance metrics. The framework is designed to interact with the problem through a visual interface as humans did when solving the problem. It is trained to imitate a set of human designers by observing their design state sequences without inducing problem-specific modelling bias or extra information about the problem. Furthermore, an end-to-end agent is developed that uses this deep learning framework as its core in conjunction with image processing to map pixel-to-design moves as a mechanism to generate designs. Finally, the designs generated by a computational team of these agents are then compared to actual human data for teams solving a truss design problem. Results demonstrates that these agents are able to create feasible and efficient truss designs without guidance, showing that this methodology allows agents to learn effective design strategies.