 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-based complete search for nonlinear minimization subject to bounds
Jul 02, 2025This paper introduces a GPU-based complete search method to enclose the global minimum of a nonlinear function subject to simple bounds on the variables. Using interval analysis, coupled with the computational power and architecture of GPU, the method iteratively rules out the regions in the search domain where the global minimum cannot exist and leaves a finite set of regions where the global minimum must exist. For effectiveness, because of the rigor of interval analysis, the method is guaranteed to enclose the global minimum of the nonlinear function even in the presence of rounding errors. For efficiency, the method employs a novel GPU-based single program, single data parallel programming style to circumvent major GPU performance bottlenecks, and a variable cycling technique is also integrated into the method to reduce computational cost when minimizing large-scale nonlinear functions. The method is validated by minimizing 10 multimodal benchmark test functions with scalable dimensions, including the well-known Ackley function, Griewank function, Levy function, and Rastrigin function. These benchmark test functions represent grand challenges of global optimization, and enclosing the guaranteed global minimum of these benchmark test functions with more than 80 dimensions has not been reported in the literature. Our method completely searches the feasible domain and successfully encloses the guaranteed global minimum of these 10 benchmark test functions with up to 10,000 dimensions using only one GPU in a reasonable computation time, far exceeding the reported results in the literature due to the unique method design and implementation based on GPU architecture.
Attention to Detail: Fine-Scale Feature Preservation-Oriented Geometric Pre-training for AI-Driven Surrogate Modeling
Apr 27, 2025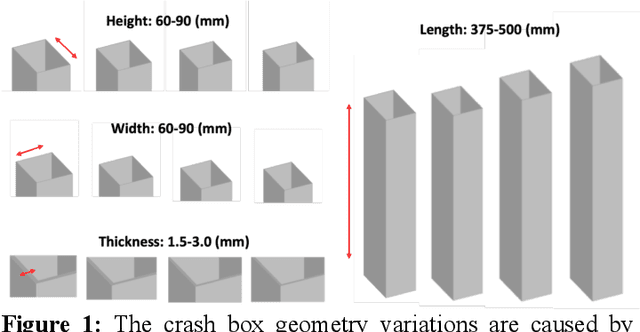
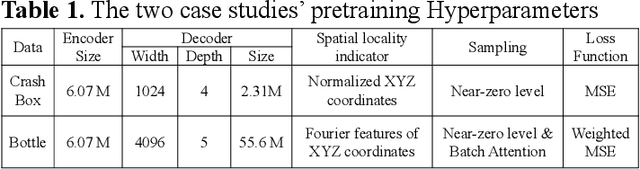

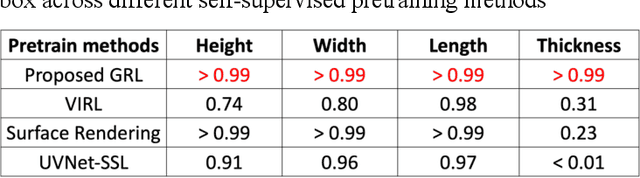
AI-driven surrogate modeling has become an increasingly effective alternative to physics-based simulations for 3D design, analysis, and manufacturing. These models leverage data-driven methods to predict physical quantities traditionally requiring computationally expensive simulations. However, the scarcity of labeled CAD-to-simulation datasets has driven recent advancements in self-supervised and foundation models, where geometric representation learning is performed offline and later fine-tuned for specific downstream tasks. While these approaches have shown promise, their effectiveness is limited in applications requiring fine-scale geometric detail preservation. This work introduces a self-supervised geometric representation learning method designed to capture fine-scale geometric features from non-parametric 3D models. Unlike traditional end-to-end surrogate models, this approach decouples geometric feature extraction from downstream physics tasks, learning a latent space embedding guided by geometric reconstruction losses. Key elements include the essential use of near-zero level sampling and the innovative batch-adaptive attention-weighted loss function, which enhance the encoding of intricate design features. The proposed method is validated through case studies in structural mechanics, demonstrating strong performance in capturing design features and enabling accurate few-shot physics predictions. Comparisons with traditional parametric surrogate modeling highlight its potential to bridge the gap between geometric and physics-based representations, providing an effective solution for surrogate modeling in data-scarce scenarios.
VIRL: Volume-Informed Representation Learning towards Few-shot Manufacturability Estimation
Jun 18, 2024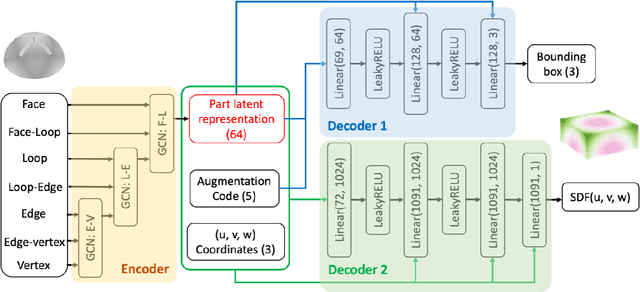

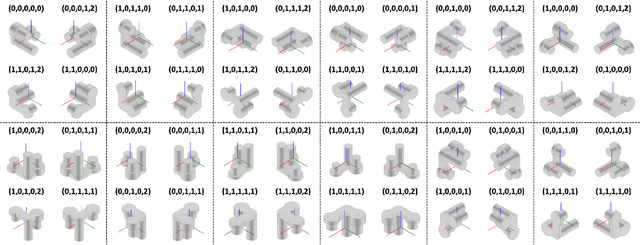
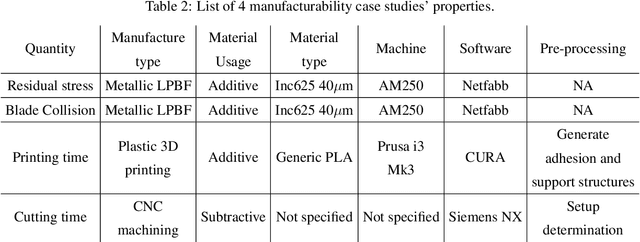
Designing for manufacturing poses significant challenges in part due to the computation bottleneck of Computer-Aided Manufacturing (CAM) simulations. Although deep learning as an alternative offers fast inference, its performance is dependently bounded by the need for abundant training data. Representation learning, particularly through pre-training, offers promise for few-shot learning, aiding in manufacturability tasks where data can be limited. This work introduces VIRL, a Volume-Informed Representation Learning approach to pre-train a 3D geometric encoder. The pretrained model is evaluated across four manufacturability indicators obtained from CAM simulations: subtractive machining (SM) time, additive manufacturing (AM) time, residual von Mises stress, and blade collisions during Laser Power Bed Fusion process. Across all case studies, the model pre-trained by VIRL shows substantial enhancements on demonstrating improved generalizability with limited data and superior performance with larger datasets. Regarding deployment strategy, case-specific phenomenon exists where finetuning VIRL-pretrained models adversely affects AM tasks with limited data but benefits SM time prediction. Moreover, the efficacy of Low-rank adaptation (LoRA), which balances between probing and finetuning, is explored. LoRA shows stable performance akin to probing with limited data, while achieving a higher upper bound than probing as data size increases, without the computational costs of finetuning. Furthermore, static normalization of manufacturing indicators consistently performs well across tasks, while dynamic normalization enhances performance when a reliable task dependent input is available.
Automating Style Analysis and Visualization With Explainable AI -- Case Studies on Brand Recognition
Jun 05, 2023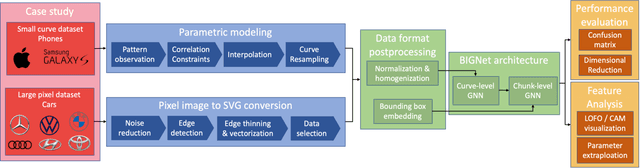

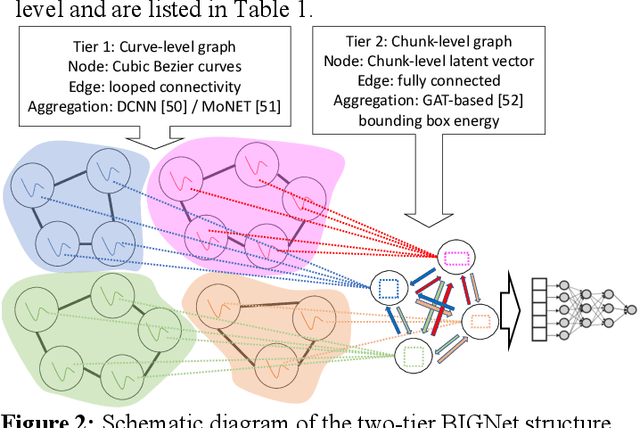

Incorporating style-related objectives into shape design has been centrally important to maximize product appeal. However, stylistic features such as aesthetics and semantic attributes are hard to codify even for experts. As such, algorithmic style capture and reuse have not fully benefited from automated data-driven methodologies due to the challenging nature of design describability. This paper proposes an AI-driven method to fully automate the discovery of brand-related features. Our approach introduces BIGNet, a two-tier Brand Identification Graph Neural Network (GNN) to classify and analyze scalar vector graphics (SVG). First, to tackle the scarcity of vectorized product images, this research proposes two data acquisition workflows: parametric modeling from small curve-based datasets, and vectorization from large pixel-based datasets. Secondly, this study constructs a novel hierarchical GNN architecture to learn from both SVG's curve-level and chunk-level parameters. In the first case study, BIGNet not only classifies phone brands but also captures brand-related features across multiple scales, such as the location of the lens, the height-width ratio, and the screen-frame gap, as confirmed by AI evaluation. In the second study, this paper showcases the generalizability of BIGNet learning from a vectorized car image dataset and validates the consistency and robustness of its predictions given four scenarios. The results match the difference commonly observed in luxury vs. economy brands in the automobile market. Finally, this paper also visualizes the activation maps generated from a convolutional neural network and shows BIGNet's advantage of being a more human-friendly, explainable, and explicit style-capturing agent. Code and dataset can be found on Github: 1. Phone case study: github.com/parksandrecfan/bignet-phone 2. Car case study: github.com/parksandrecfan/bignet-car
Learning to design without prior data: Discovering generalizable design strategies using deep learning and tree search
Nov 28, 2022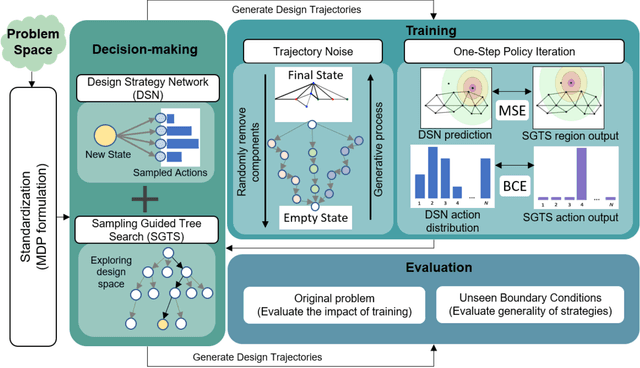
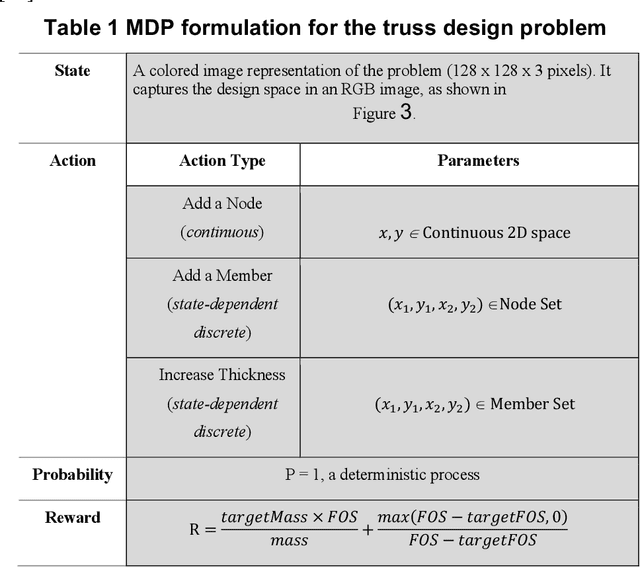

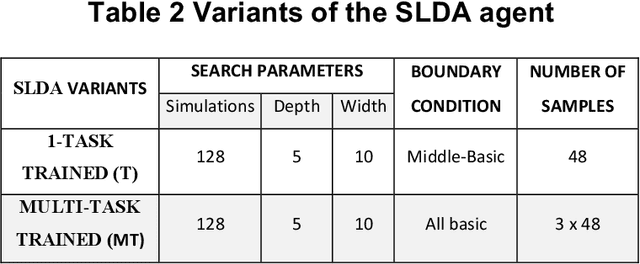
Building an AI agent that can design on its own has been a goal since the 1980s. Recently, deep learning has shown the ability to learn from large-scale data, enabling significant advances in data-driven design. However, learning over prior data limits us only to solve problems that have been solved before and biases data-driven learning towards existing solutions. The ultimate goal for a design agent is the ability to learn generalizable design behavior in a problem space without having seen it before. We introduce a self-learning agent framework in this work that achieves this goal. This framework integrates a deep policy network with a novel tree search algorithm, where the tree search explores the problem space, and the deep policy network leverages self-generated experience to guide the search further. This framework first demonstrates an ability to discover high-performing generative strategies without any prior data, and second, it illustrates a zero-shot generalization of generative strategies across various unseen boundary conditions. This work evaluates the effectiveness and versatility of the framework by solving multiple versions of two engineering design problems without retraining. Overall, this paper presents a methodology to self-learn high-performing and generalizable problem-solving behavior in an arbitrary problem space, circumventing the needs for expert data, existing solutions, and problem-specific learning.
Design Strategy Network: A deep hierarchical framework to represent generative design strategies in complex action spaces
Oct 07, 2021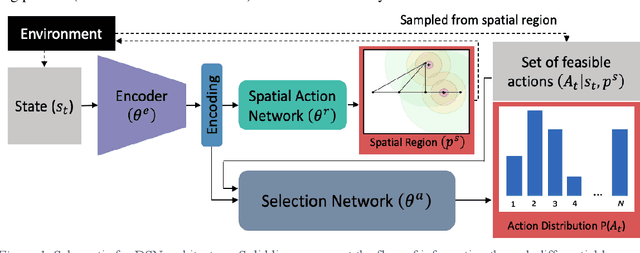
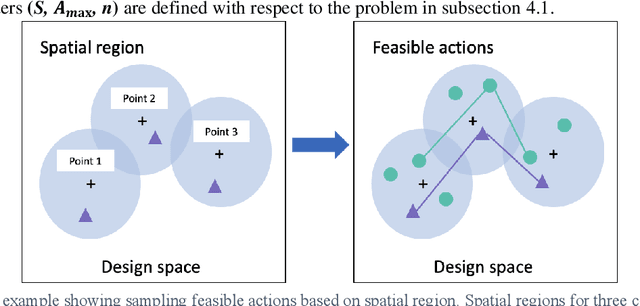

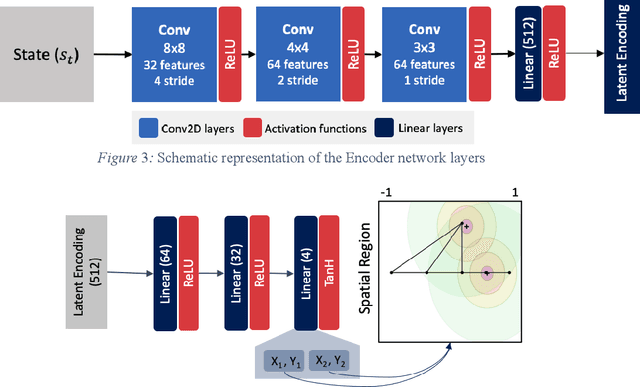
Generative design problems often encompass complex action spaces that may be divergent over time, contain state-dependent constraints, or involve hybrid (discrete and continuous) domains. To address those challenges, this work introduces Design Strategy Network (DSN), a data-driven deep hierarchical framework that can learn strategies over these arbitrary complex action spaces. The hierarchical architecture decomposes every action decision into first predicting a preferred spatial region in the design space and then outputting a probability distribution over a set of possible actions from that region. This framework comprises a convolutional encoder to work with image-based design state representations, a multi-layer perceptron to predict a spatial region, and a weight-sharing network to generate a probability distribution over unordered set-based inputs of feasible actions. Applied to a truss design study, the framework learns to predict the actions of human designers in the study, capturing their truss generation strategies in the process. Results show that DSNs significantly outperform non-hierarchical methods of policy representation, demonstrating their superiority in complex action space problems.
* Published in Journal of Mechanical Design
Goal-Directed Design Agents: Integrating Visual Imitation with One-Step Lookahead Optimization for Generative Design
Oct 07, 2021

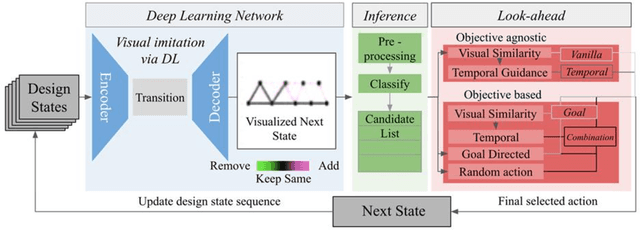
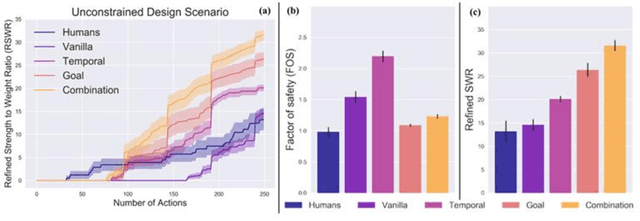
Engineering design problems often involve large state and action spaces along with highly sparse rewards. Since an exhaustive search of those spaces is not feasible, humans utilize relevant domain knowledge to condense the search space. Previously, deep learning agents (DLAgents) were introduced to use visual imitation learning to model design domain knowledge. This note builds on DLAgents and integrates them with one-step lookahead search to develop goal-directed agents capable of enhancing learned strategies for sequentially generating designs. Goal-directed DLAgents can employ human strategies learned from data along with optimizing an objective function. The visual imitation network from DLAgents is composed of a convolutional encoder-decoder network, acting as a rough planning step that is agnostic to feedback. Meanwhile, the lookahead search identifies the fine-tuned design action guided by an objective. These design agents are trained on an unconstrained truss design problem that is modeled as a sequential, action-based configuration design problem. The agents are then evaluated on two versions of the problem: the original version used for training and an unseen constrained version with an obstructed construction space. The goal-directed agents outperform the human designers used to train the network as well as the previous objective-agnostic versions of the agent in both scenarios. This illustrates a design agent framework that can efficiently use feedback to not only enhance learned design strategies but also adapt to unseen design problems.
Learning to design from humans: Imitating human designers through deep learning
Aug 02, 2019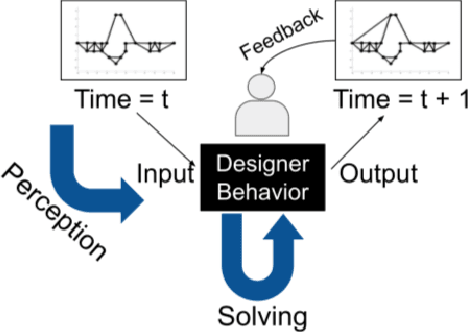
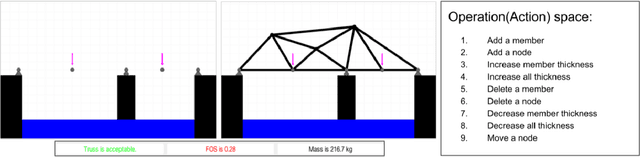
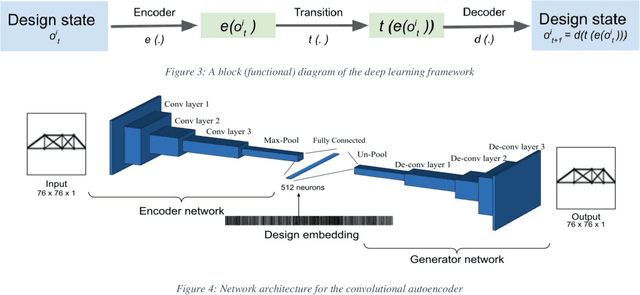

Humans as designers have quite versatile problem-solving strategies. Computer agents on the other hand can access large scale computational resources to solve certain design problems. Hence, if agents can learn from human behavior, a synergetic human-agent problem solving team can be created. This paper presents an approach to extract human design strategies and implicit rules, purely from historical human data, and use that for design generation. A two-step framework that learns to imitate human design strategies from observation is proposed and implemented. This framework makes use of deep learning constructs to learn to generate designs without any explicit information about objective and performance metrics. The framework is designed to interact with the problem through a visual interface as humans did when solving the problem. It is trained to imitate a set of human designers by observing their design state sequences without inducing problem-specific modelling bias or extra information about the problem. Furthermore, an end-to-end agent is developed that uses this deep learning framework as its core in conjunction with image processing to map pixel-to-design moves as a mechanism to generate designs. Finally, the designs generated by a computational team of these agents are then compared to actual human data for teams solving a truss design problem. Results demonstrates that these agents are able to create feasible and efficient truss designs without guidance, showing that this methodology allows agents to learn effective design strategies.