 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervising Ralph Wiggum: Exploring a Metacognitive Co-Regulation Agentic AI Loop for Engineering Design
Mar 25, 2026The engineering design research community has studied agentic AI systems that use Large Language Model (LLM) agents to automate the engineering design process. However, these systems are prone to some of the same pathologies that plague humans. Just as human designers, LLM design agents can fixate on existing paradigms and fail to explore alternatives when solving design challenges, potentially leading to suboptimal solutions. In this work, we propose (1) a novel Self-Regulation Loop (SRL), in which the Design Agent self-regulates and explicitly monitors its own metacognition, and (2) a novel Co-Regulation Design Agentic Loop (CRDAL), in which a Metacognitive Co-Regulation Agent assists the Design Agent in metacognition to mitigate design fixation, thereby improving system performance for engineering design tasks. In the battery pack design problem examined here, we found that the novel CRDAL system generates designs with better performance, without significantly increasing the computational cost, compared to a plain Ralph Wiggum Loop (RWL) and the metacognitively self-assessing Self-Regulation Loop (SRL). Also, we found that the CRDAL system navigated through the latent design space more effectively than both SRL and RWL. However, the SRL did not generate designs with significantly better performance than RWL, even though it explored a different region of the design space. The proposed system architectures and findings of this work provide practical implications for future development of agentic AI systems for engineering design.
Adaptive Learning of Design Strategies over Non-Hierarchical Multi-Fidelity Models via Policy Alignment
Nov 16, 2024



Multi-fidelity Reinforcement Learning (RL) frameworks significantly enhance the efficiency of engineering design by leveraging analysis models with varying levels of accuracy and computational costs. The prevailing methodologies, characterized by transfer learning, human-inspired strategies, control variate techniques, and adaptive sampling, predominantly depend on a structured hierarchy of models. However, this reliance on a model hierarchy overlooks the heterogeneous error distributions of models across the design space, extending beyond mere fidelity levels. This work proposes ALPHA (Adaptively Learned Policy with Heterogeneous Analyses), a novel multi-fidelity RL framework to efficiently learn a high-fidelity policy by adaptively leveraging an arbitrary set of non-hierarchical, heterogeneous, low-fidelity models alongside a high-fidelity model. Specifically, low-fidelity policies and their experience data are dynamically used for efficient targeted learning, guided by their alignment with the high-fidelity policy. The effectiveness of ALPHA is demonstrated in analytical test optimization and octocopter design problems, utilizing two low-fidelity models alongside a high-fidelity one. The results highlight ALPHA's adaptive capability to dynamically utilize models across time and design space, eliminating the need for scheduling models as required in a hierarchical framework. Furthermore, the adaptive agents find more direct paths to high-performance solutions, showing superior convergence behavior compared to hierarchical agents.
MSEval: A Dataset for Material Selection in Conceptual Design to Evaluate Algorithmic Models
Jul 12, 2024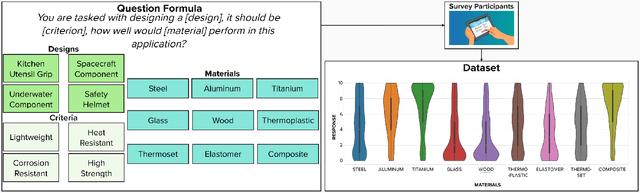
Material selection plays a pivotal role in many industries, from manufacturing to construction. Material selection is usually carried out after several cycles of conceptual design, during which designers iteratively refine the design solution and the intended manufacturing approach. In design research, material selection is typically treated as an optimization problem with a single correct answer. Moreover, it is also often restricted to specific types of objects or design functions, which can make the selection process computationally expensive and time-consuming. In this paper, we introduce MSEval, a novel dataset which is comprised of expert material evaluations across a variety of design briefs and criteria. This data is designed to serve as a benchmark to facilitate the evaluation and modification of machine learning models in the context of material selection for conceptual design.
Smooth Like Butter: Evaluating Multi-Lattice Transitions in Property-Augmented Latent Spaces
Jul 10, 2024Additive manufacturing has revolutionized structural optimization by enhancing component strength and reducing material requirements. One approach used to achieve these improvements is the application of multi-lattice structures, where the macro-scale performance relies on the detailed design of mesostructural lattice elements. Many current approaches to designing such structures use data-driven design to generate multi-lattice transition regions, making use of machine learning models that are informed solely by the geometry of the mesostructures. However, it remains unclear if the integration of mechanical properties into the dataset used to train such machine learning models would be beneficial beyond using geometric data alone. To address this issue, this work implements and evaluates a hybrid geometry/property Variational Autoencoder (VAE) for generating multi-lattice transition regions. In our study, we found that hybrid VAEs demonstrate enhanced performance in maintaining stiffness continuity through transition regions, indicating their suitability for design tasks requiring smooth mechanical properties.
Data Scoping: Effectively Learning the Evolution of Generic Transport PDEs
May 02, 2024Transport phenomena (e.g., fluid flows) are governed by time-dependent partial differential equations (PDEs) describing mass, momentum, and energy conservation, and are ubiquitous in many engineering applications. However, deep learning architectures are fundamentally incompatible with the simulation of these PDEs. This paper clearly articulates and then solves this incompatibility. The local-dependency of generic transport PDEs implies that it only involves local information to predict the physical properties at a location in the next time step. However, the deep learning architecture will inevitably increase the scope of information to make such predictions as the number of layers increases, which can cause sluggish convergence and compromise generalizability. This paper aims to solve this problem by proposing a distributed data scoping method with linear time complexity to strictly limit the scope of information to predict the local properties. The numerical experiments over multiple physics show that our data scoping method significantly accelerates training convergence and improves the generalizability of benchmark models on large-scale engineering simulations. Specifically, over the geometries not included in the training data for heat transferring simulation, it can increase the accuracy of Convolutional Neural Networks (CNNs) by 21.7 \% and that of Fourier Neural Operators (FNOs) by 38.5 \% on average.
Exploring the Capabilities of Large Language Models for Generating Diverse Design Solutions
May 02, 2024Access to large amounts of diverse design solutions can support designers during the early stage of the design process. In this paper, we explore the efficacy of large language models (LLM) in producing diverse design solutions, investigating the level of impact that parameter tuning and various prompt engineering techniques can have on the diversity of LLM-generated design solutions. Specifically, LLMs are used to generate a total of 4,000 design solutions across five distinct design topics, eight combinations of parameters, and eight different types of prompt engineering techniques, comparing each combination of parameter and prompt engineering method across four different diversity metrics. LLM-generated solutions are compared against 100 human-crowdsourced solutions in each design topic using the same set of diversity metrics. Results indicate that human-generated solutions consistently have greater diversity scores across all design topics. Using a post hoc logistic regression analysis we investigate whether these differences primarily exist at the semantic level. Results show that there is a divide in some design topics between humans and LLM-generated solutions, while others have no clear divide. Taken together, these results contribute to the understanding of LLMs' capabilities in generating a large volume of diverse design solutions and offer insights for future research that leverages LLMs to generate diverse design solutions for a broad range of design tasks (e.g., inspirational stimuli).
Evaluating Large Language Models for Material Selection
Apr 23, 2024Material selection is a crucial step in conceptual design due to its significant impact on the functionality, aesthetics, manufacturability, and sustainability impact of the final product. This study investigates the use of Large Language Models (LLMs) for material selection in the product design process and compares the performance of LLMs against expert choices for various design scenarios. By collecting a dataset of expert material preferences, the study provides a basis for evaluating how well LLMs can align with expert recommendations through prompt engineering and hyperparameter tuning. The divergence between LLM and expert recommendations is measured across different model configurations, prompt strategies, and temperature settings. This approach allows for a detailed analysis of factors influencing the LLMs' effectiveness in recommending materials. The results from this study highlight two failure modes, and identify parallel prompting as a useful prompt-engineering method when using LLMs for material selection. The findings further suggest that, while LLMs can provide valuable assistance, their recommendations often vary significantly from those of human experts. This discrepancy underscores the need for further research into how LLMs can be better tailored to replicate expert decision-making in material selection. This work contributes to the growing body of knowledge on how LLMs can be integrated into the design process, offering insights into their current limitations and potential for future improvements.
Capturing Local Temperature Evolution during Additive Manufacturing through Fourier Neural Operators
Jul 04, 2023High-fidelity, data-driven models that can quickly simulate thermal behavior during additive manufacturing (AM) are crucial for improving the performance of AM technologies in multiple areas, such as part design, process planning, monitoring, and control. However, the complexities of part geometries make it challenging for current models to maintain high accuracy across a wide range of geometries. Additionally, many models report a low mean square error (MSE) across the entire domain (part). However, in each time step, most areas of the domain do not experience significant changes in temperature, except for the heat-affected zones near recent depositions. Therefore, the MSE-based fidelity measurement of the models may be overestimated. This paper presents a data-driven model that uses Fourier Neural Operator to capture the local temperature evolution during the additive manufacturing process. In addition, the authors propose to evaluate the model using the $R^2$ metric, which provides a relative measure of the model's performance compared to using mean temperature as a prediction. The model was tested on numerical simulations based on the Discontinuous Galerkin Finite Element Method for the Direct Energy Deposition process, and the results demonstrate that the model achieves high fidelity as measured by $R^2$ and maintains generalizability to geometries that were not included in the training process.
Smoothing the Rough Edges: Evaluating Automatically Generated Multi-Lattice Transitions
Jun 13, 2023Additive manufacturing is advantageous for producing lightweight components while addressing complex design requirements. This capability has been bolstered by the introduction of unit lattice cells and the gradation of those cells. In cases where loading varies throughout a part, it may be beneficial to use multiple, distinct lattice cell types, resulting in multi-lattice structures. In such structures, abrupt transitions between unit cell topologies may cause stress concentrations, making the boundary between unit cell types a primary failure point. Thus, these regions require careful design in order to ensure the overall functionality of the part. Although computational design approaches have been proposed, smooth transition regions are still difficult to achieve, especially between lattices of drastically different topologies. This work demonstrates and assesses a method for using variational autoencoders to automate the creation of transitional lattice cells, examining the factors that contribute to smooth transitions. Through computational experimentation, it was found that the smoothness of transition regions was strongly predicted by how closely the endpoints were in the latent space, whereas the number of transition intervals was not a sole predictor.
AircraftVerse: A Large-Scale Multimodal Dataset of Aerial Vehicle Designs
Jun 08, 2023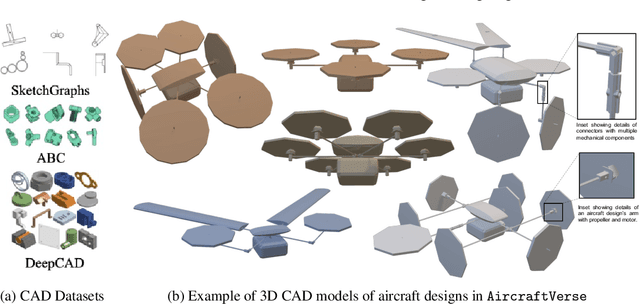
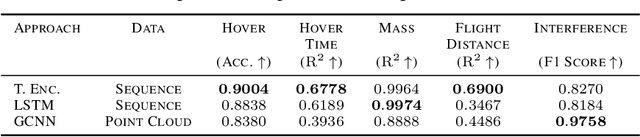
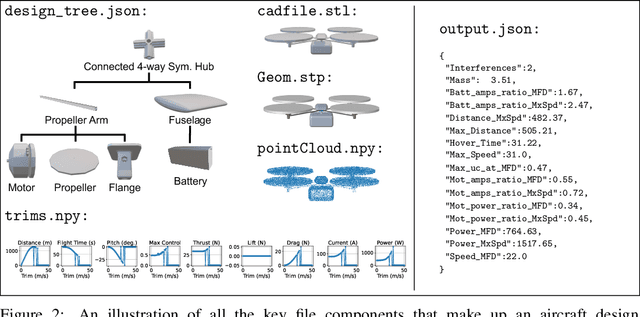

We present AircraftVerse, a publicly available aerial vehicle design dataset. Aircraft design encompasses different physics domains and, hence, multiple modalities of representation. The evaluation of these cyber-physical system (CPS) designs requires the use of scientific analytical and simulation models ranging from computer-aided design tools for structural and manufacturing analysis, computational fluid dynamics tools for drag and lift computation, battery models for energy estimation, and simulation models for flight control and dynamics. AircraftVerse contains 27,714 diverse air vehicle designs - the largest corpus of engineering designs with this level of complexity. Each design comprises the following artifacts: a symbolic design tree describing topology, propulsion subsystem, battery subsystem, and other design details; a STandard for the Exchange of Product (STEP) model data; a 3D CAD design using a stereolithography (STL) file format; a 3D point cloud for the shape of the design; and evaluation results from high fidelity state-of-the-art physics models that characterize performance metrics such as maximum flight distance and hover-time. We also present baseline surrogate models that use different modalities of design representation to predict design performance metrics, which we provide as part of our dataset release. Finally, we discuss the potential impact of this dataset on the use of learning in aircraft design and, more generally, in CPS. AircraftVerse is accompanied by a data card, and it is released under Creative Commons Attribution-ShareAlike (CC BY-SA) license. The dataset is hosted at https://zenodo.org/record/6525446, baseline models and code at https://github.com/SRI-CSL/AircraftVerse, and the dataset description at https://aircraftverse.onrender.com/.