 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Fast Low-rank Attention Routing Engine
Aug 18, 2025



The quadratic complexity of self-attention limits its applicability and scalability on large unstructured meshes. We introduce Fast Low-rank Attention Routing Engine (FLARE), a linear complexity self-attention mechanism that routes attention through fixed-length latent sequences. Each attention head performs global communication among $N$ tokens by projecting the input sequence onto a fixed length latent sequence of $M \ll N$ tokens using learnable query tokens. By routing attention through a bottleneck sequence, FLARE learns a low-rank form of attention that can be applied at $O(NM)$ cost. FLARE not only scales to unprecedented problem sizes, but also delivers superior accuracy compared to state-of-the-art neural PDE surrogates across diverse benchmarks. We also release a new additive manufacturing dataset to spur further research. Our code is available at https://github.com/vpuri3/FLARE.py.
Attention to Detail: Fine-Scale Feature Preservation-Oriented Geometric Pre-training for AI-Driven Surrogate Modeling
Apr 27, 2025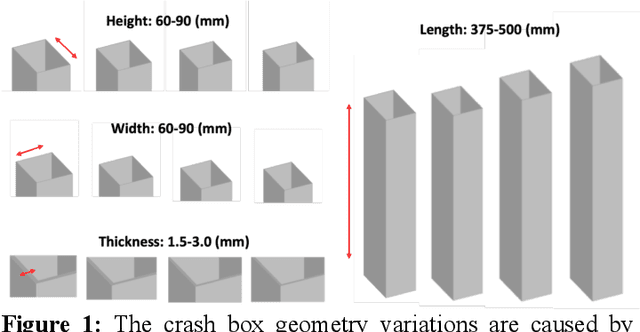
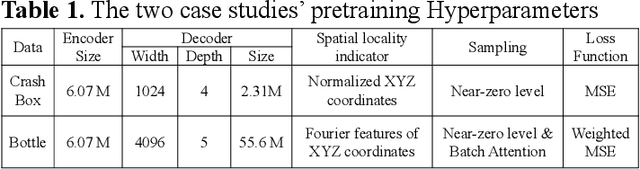

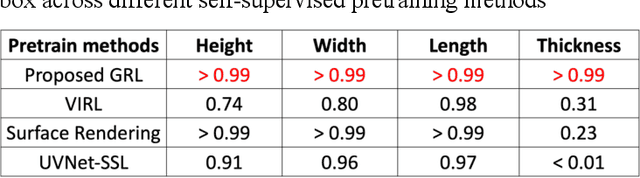
AI-driven surrogate modeling has become an increasingly effective alternative to physics-based simulations for 3D design, analysis, and manufacturing. These models leverage data-driven methods to predict physical quantities traditionally requiring computationally expensive simulations. However, the scarcity of labeled CAD-to-simulation datasets has driven recent advancements in self-supervised and foundation models, where geometric representation learning is performed offline and later fine-tuned for specific downstream tasks. While these approaches have shown promise, their effectiveness is limited in applications requiring fine-scale geometric detail preservation. This work introduces a self-supervised geometric representation learning method designed to capture fine-scale geometric features from non-parametric 3D models. Unlike traditional end-to-end surrogate models, this approach decouples geometric feature extraction from downstream physics tasks, learning a latent space embedding guided by geometric reconstruction losses. Key elements include the essential use of near-zero level sampling and the innovative batch-adaptive attention-weighted loss function, which enhance the encoding of intricate design features. The proposed method is validated through case studies in structural mechanics, demonstrating strong performance in capturing design features and enabling accurate few-shot physics predictions. Comparisons with traditional parametric surrogate modeling highlight its potential to bridge the gap between geometric and physics-based representations, providing an effective solution for surrogate modeling in data-scarce scenarios.
MDDM: A Molecular Dynamics Diffusion Model to Predict Particle Self-Assembly
Jan 28, 2025



The discovery and study of new material systems relies on molecular simulations that often come with significant computational expense. We propose MDDM, a Molecular Dynamics Diffusion Model, which is capable of predicting a valid output conformation for a given input pair potential function. After training MDDM on a large dataset of molecular dynamics self-assembly results, the proposed model can convert uniform noise into a meaningful output particle structure corresponding to an arbitrary input potential. The model's architecture has domain-specific properties built-in, such as satisfying periodic boundaries and being invariant to translation. The model significantly outperforms the baseline point-cloud diffusion model for both unconditional and conditional generation tasks.
Topology-Agnostic Graph U-Nets for Scalar Field Prediction on Unstructured Meshes
Oct 08, 2024



Machine-learned surrogate models to accelerate lengthy computer simulations are becoming increasingly important as engineers look to streamline the product design cycle. In many cases, these approaches offer the ability to predict relevant quantities throughout a geometry, but place constraints on the form of the input data. In a world of diverse data types, a preferred approach would not restrict the input to a particular structure. In this paper, we propose Topology-Agnostic Graph U-Net (TAG U-Net), a graph convolutional network that can be trained to input any mesh or graph structure and output a prediction of a target scalar field at each node. The model constructs coarsened versions of each input graph and performs a set of convolution and pooling operations to predict the node-wise outputs on the original graph. By training on a diverse set of shapes, the model can make strong predictions, even for shapes unlike those seen during training. A 3-D additive manufacturing dataset is presented, containing Laser Powder Bed Fusion simulation results for thousands of parts. The model is demonstrated on this dataset, and it performs well, predicting both 2-D and 3-D scalar fields with a median R-squared > 0.85 on test geometries. Code and datasets are available online.
VIRL: Volume-Informed Representation Learning towards Few-shot Manufacturability Estimation
Jun 18, 2024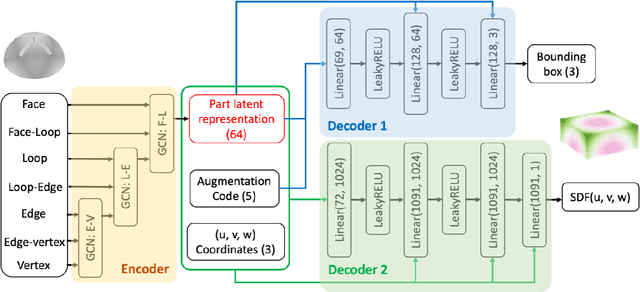

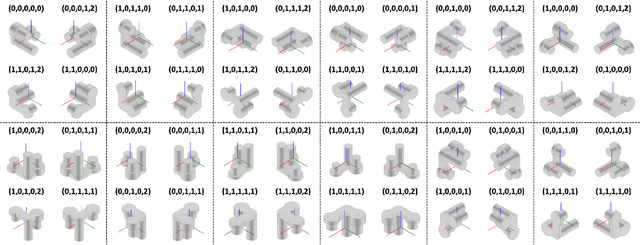
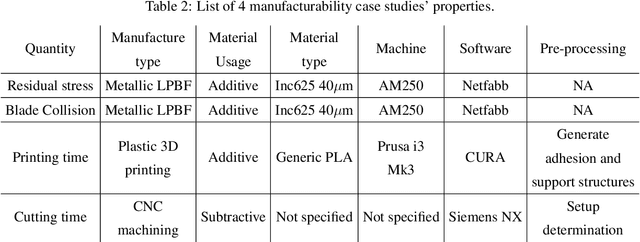
Designing for manufacturing poses significant challenges in part due to the computation bottleneck of Computer-Aided Manufacturing (CAM) simulations. Although deep learning as an alternative offers fast inference, its performance is dependently bounded by the need for abundant training data. Representation learning, particularly through pre-training, offers promise for few-shot learning, aiding in manufacturability tasks where data can be limited. This work introduces VIRL, a Volume-Informed Representation Learning approach to pre-train a 3D geometric encoder. The pretrained model is evaluated across four manufacturability indicators obtained from CAM simulations: subtractive machining (SM) time, additive manufacturing (AM) time, residual von Mises stress, and blade collisions during Laser Power Bed Fusion process. Across all case studies, the model pre-trained by VIRL shows substantial enhancements on demonstrating improved generalizability with limited data and superior performance with larger datasets. Regarding deployment strategy, case-specific phenomenon exists where finetuning VIRL-pretrained models adversely affects AM tasks with limited data but benefits SM time prediction. Moreover, the efficacy of Low-rank adaptation (LoRA), which balances between probing and finetuning, is explored. LoRA shows stable performance akin to probing with limited data, while achieving a higher upper bound than probing as data size increases, without the computational costs of finetuning. Furthermore, static normalization of manufacturing indicators consistently performs well across tasks, while dynamic normalization enhances performance when a reliable task dependent input is available.
Automating Style Analysis and Visualization With Explainable AI -- Case Studies on Brand Recognition
Jun 05, 2023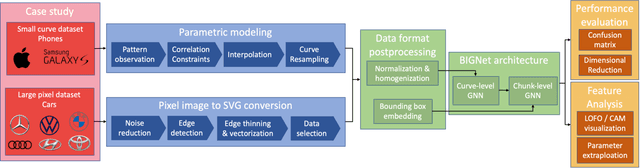

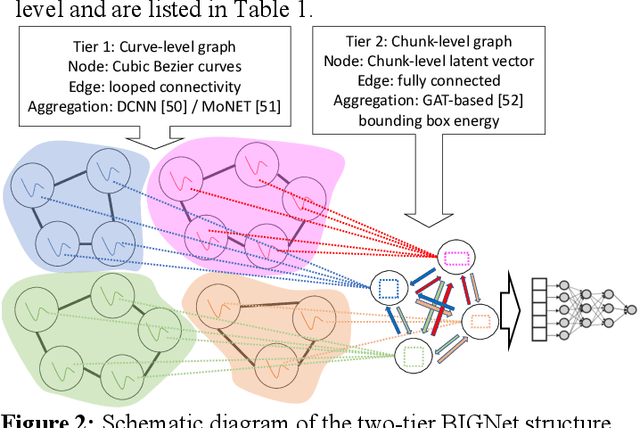

Incorporating style-related objectives into shape design has been centrally important to maximize product appeal. However, stylistic features such as aesthetics and semantic attributes are hard to codify even for experts. As such, algorithmic style capture and reuse have not fully benefited from automated data-driven methodologies due to the challenging nature of design describability. This paper proposes an AI-driven method to fully automate the discovery of brand-related features. Our approach introduces BIGNet, a two-tier Brand Identification Graph Neural Network (GNN) to classify and analyze scalar vector graphics (SVG). First, to tackle the scarcity of vectorized product images, this research proposes two data acquisition workflows: parametric modeling from small curve-based datasets, and vectorization from large pixel-based datasets. Secondly, this study constructs a novel hierarchical GNN architecture to learn from both SVG's curve-level and chunk-level parameters. In the first case study, BIGNet not only classifies phone brands but also captures brand-related features across multiple scales, such as the location of the lens, the height-width ratio, and the screen-frame gap, as confirmed by AI evaluation. In the second study, this paper showcases the generalizability of BIGNet learning from a vectorized car image dataset and validates the consistency and robustness of its predictions given four scenarios. The results match the difference commonly observed in luxury vs. economy brands in the automobile market. Finally, this paper also visualizes the activation maps generated from a convolutional neural network and shows BIGNet's advantage of being a more human-friendly, explainable, and explicit style-capturing agent. Code and dataset can be found on Github: 1. Phone case study: github.com/parksandrecfan/bignet-phone 2. Car case study: github.com/parksandrecfan/bignet-car