 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign before Search: Aligning Ads Image to Text for Accurate Cross-Modal Sponsored Search
Paper and Code
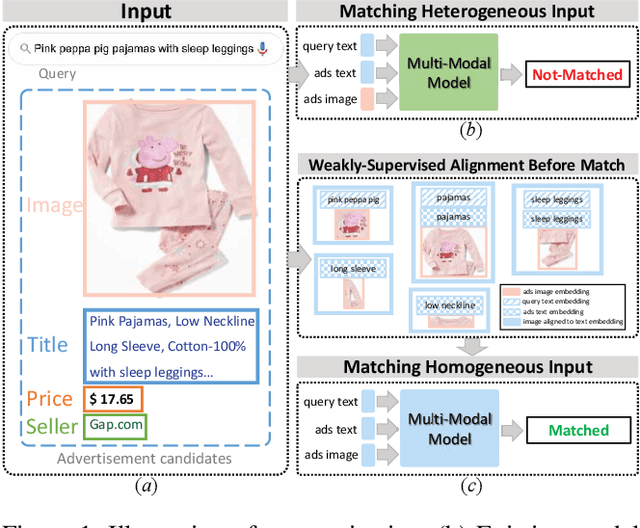
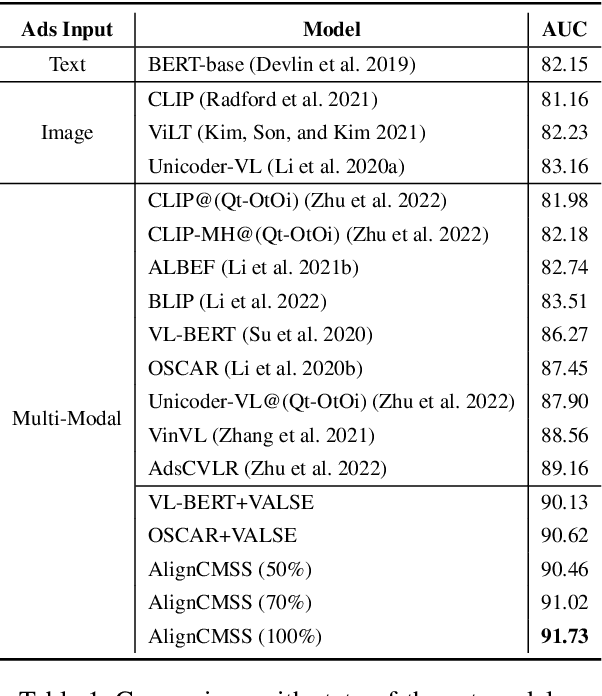
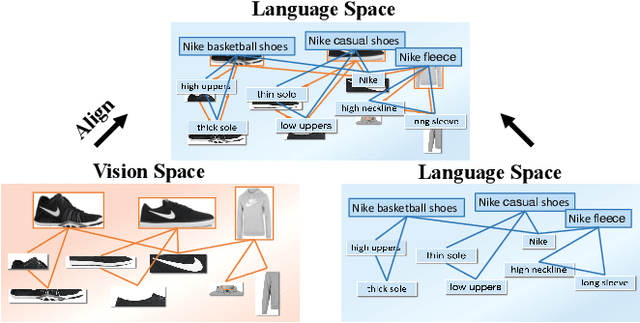
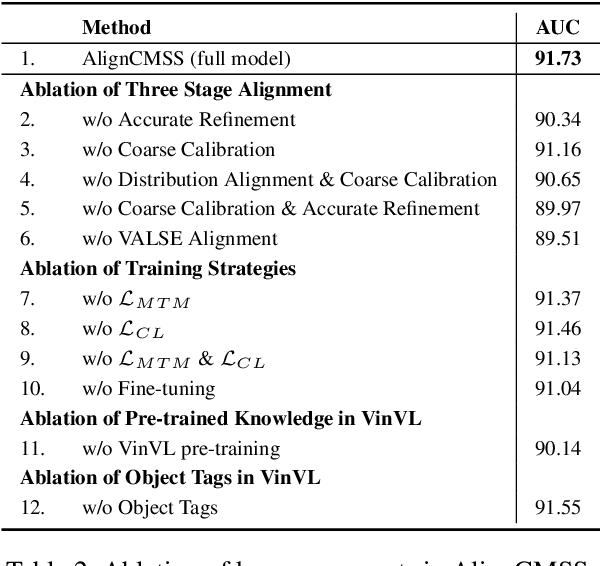
Cross-Modal sponsored search displays multi-modal advertisements (ads) when consumers look for desired products by natural language queries in search engines. Since multi-modal ads bring complementary details for query-ads matching, the ability to align ads-specific information in both images and texts is crucial for accurate and flexible sponsored search. Conventional research mainly studies from the view of modeling the implicit correlations between images and texts for query-ads matching, ignoring the alignment of detailed product information and resulting in suboptimal search performance.In this work, we propose a simple alignment network for explicitly mapping fine-grained visual parts in ads images to the corresponding text, which leverages the co-occurrence structure consistency between vision and language spaces without requiring expensive labeled training data. Moreover, we propose a novel model for cross-modal sponsored search that effectively conducts the cross-modal alignment and query-ads matching in two separate processes. In this way, the model matches the multi-modal input in the same language space, resulting in a superior performance with merely half of the training data. Our model outperforms the state-of-the-art models by 2.57% on a large commercial dataset. Besides sponsored search, our alignment method is applicable for general cross-modal search. We study a typical cross-modal retrieval task on the MSCOCO dataset, which achieves consistent performance improvement and proves the generalization ability of our method. Our code is available at https://github.com/Pter61/AlignCMSS/