 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Adversarial Ladder Networks For Semi-supervised Learning
Dec 12, 2017
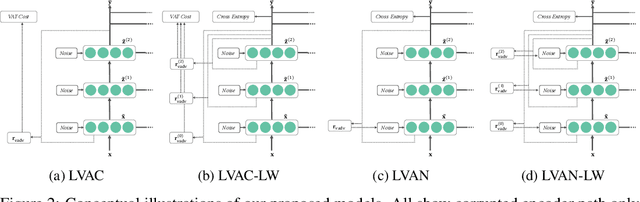
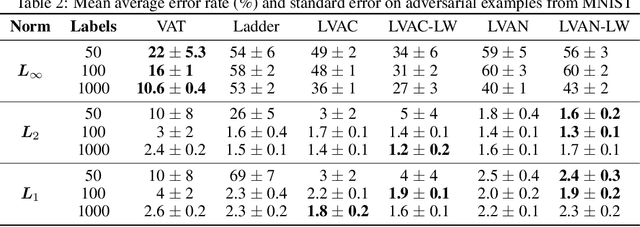
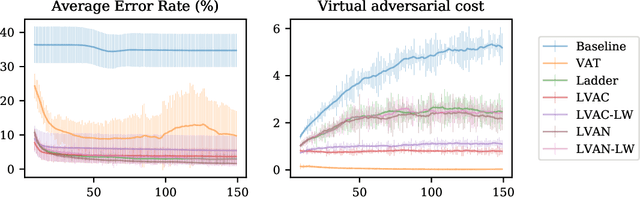
Semi-supervised learning (SSL) partially circumvents the high cost of labeling data by augmenting a small labeled dataset with a large and relatively cheap unlabeled dataset drawn from the same distribution. This paper offers a novel interpretation of two deep learning-based SSL approaches, ladder networks and virtual adversarial training (VAT), as applying distributional smoothing to their respective latent spaces. We propose a class of models that fuse these approaches. We achieve near-supervised accuracy with high consistency on the MNIST dataset using just 5 labels per class: our best model, ladder with layer-wise virtual adversarial noise (LVAN-LW), achieves 1.42% +/- 0.12 average error rate on the MNIST test set, in comparison with 1.62% +/- 0.65 reported for the ladder network. On adversarial examples generated with L2-normalized fast gradient method, LVAN-LW trained with 5 examples per class achieves average error rate 2.4% +/- 0.3 compared to 68.6% +/- 6.5 for the ladder network and 9.9% +/- 7.5 for VAT.