 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Paper and Code

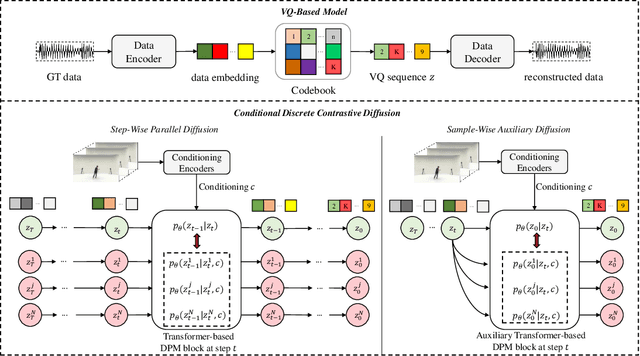
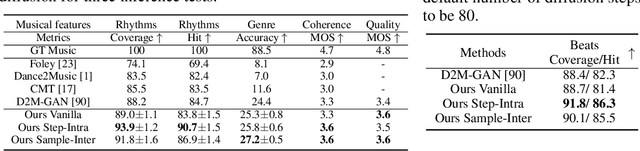
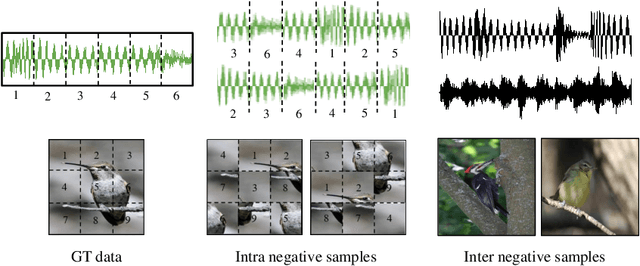
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.