 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Look is Enough: A Novel Seamless Patchwise Refinement for Zero-Shot Monocular Depth Estimation Models on High-Resolution Images
Mar 28, 2025



Zero-shot depth estimation (DE) models exhibit strong generalization performance as they are trained on large-scale datasets. However, existing models struggle with high-resolution images due to the discrepancy in image resolutions of training (with smaller resolutions) and inference (for high resolutions). Processing them at full resolution leads to decreased estimation accuracy on depth with tremendous memory consumption, while downsampling to the training resolution results in blurred edges in the estimated depth images. Prevailing high-resolution depth estimation methods adopt a patch-based approach, which introduces depth discontinuity issues when reassembling the estimated depth patches and results in test-time inefficiency. Additionally, to obtain fine-grained depth details, these methods rely on synthetic datasets due to the real-world sparse ground truth depth, leading to poor generalizability. To tackle these limitations, we propose Patch Refine Once (PRO), an efficient and generalizable tile-based framework. Our PRO consists of two key components: (i) Grouped Patch Consistency Training that enhances test-time efficiency while mitigating the depth discontinuity problem by jointly processing four overlapping patches and enforcing a consistency loss on their overlapping regions within a single backpropagation step, and (ii) Bias Free Masking that prevents the DE models from overfitting to dataset-specific biases, enabling better generalization to real-world datasets even after training on synthetic data. Zero-shot evaluation on Booster, ETH3D, Middlebury 2014, and NuScenes demonstrates into which our PRO can be well harmonized, making their DE capabilities still effective for the grid input of high-resolution images with little depth discontinuities at the grid boundaries. Our PRO runs fast at inference time.
From-Ground-To-Objects: Coarse-to-Fine Self-supervised Monocular Depth Estimation of Dynamic Objects with Ground Contact Prior
Dec 15, 2023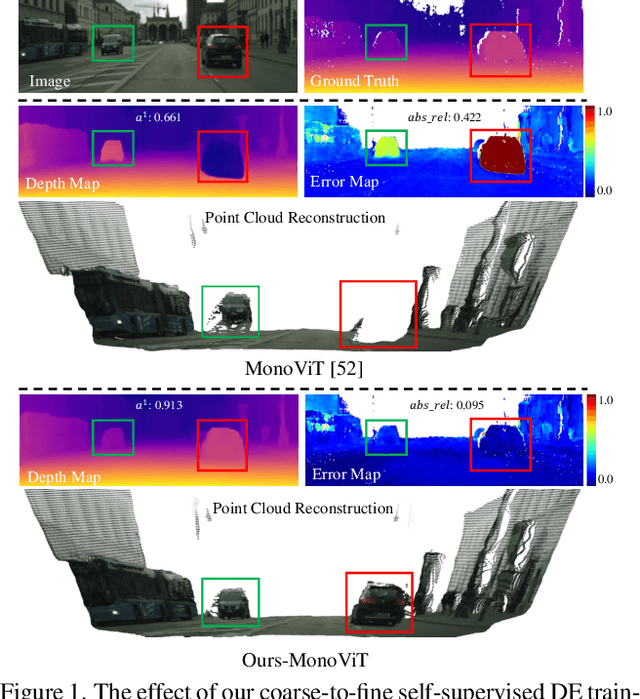
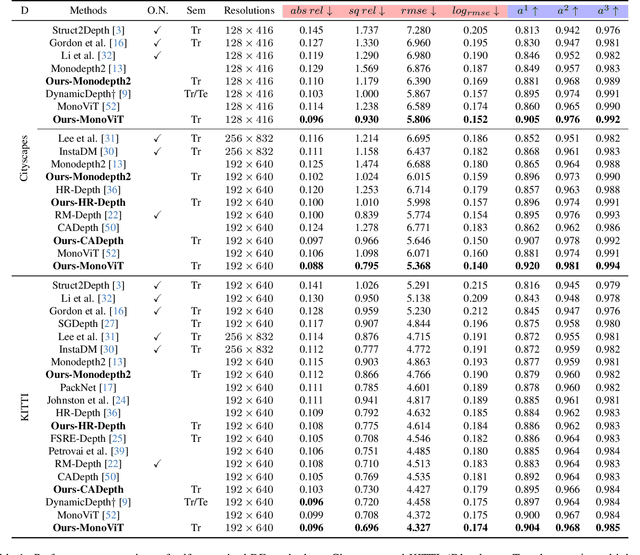
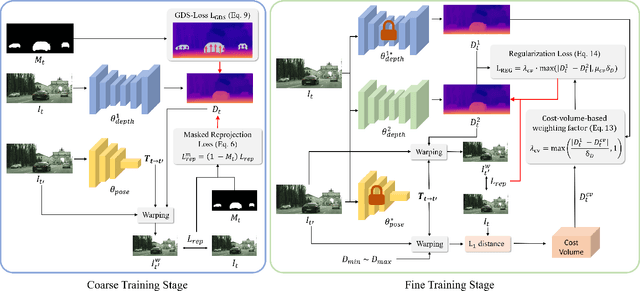
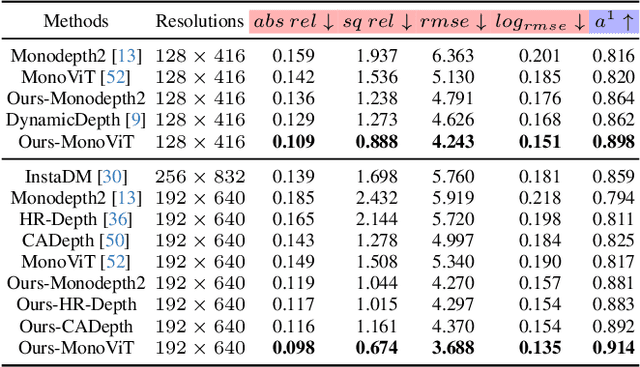
Self-supervised monocular depth estimation (DE) is an approach to learning depth without costly depth ground truths. However, it often struggles with moving objects that violate the static scene assumption during training. To address this issue, we introduce a coarse-to-fine training strategy leveraging the ground contacting prior based on the observation that most moving objects in outdoor scenes contact the ground. In the coarse training stage, we exclude the objects in dynamic classes from the reprojection loss calculation to avoid inaccurate depth learning. To provide precise supervision on the depth of the objects, we present a novel Ground-contacting-prior Disparity Smoothness Loss (GDS-Loss) that encourages a DE network to align the depth of the objects with their ground-contacting points. Subsequently, in the fine training stage, we refine the DE network to learn the detailed depth of the objects from the reprojection loss, while ensuring accurate DE on the moving object regions by employing our regularization loss with a cost-volume-based weighting factor. Our overall coarse-to-fine training strategy can easily be integrated with existing DE methods without any modifications, significantly enhancing DE performance on challenging Cityscapes and KITTI datasets, especially in the moving object regions.
Realistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.