 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of L2 Korean pronunciation error patterns from five L1 backgrounds by using automatic phonetic transcription
Paper and Code
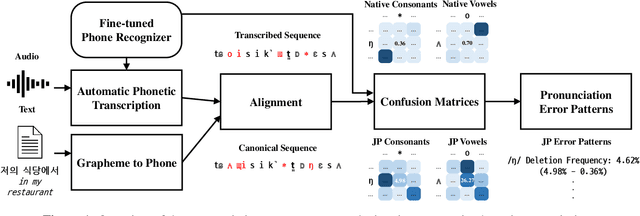



This paper presents a large-scale analysis of L2 Korean pronunciation error patterns from five different language backgrounds, Chinese, Vietnamese, Japanese, Thai, and English, by using automatic phonetic transcription. For the analysis, confusion matrices are generated for each L1, by aligning canonical phone sequences and automatically transcribed phone sequences obtained from fine-tuned Wav2Vec2 XLS-R phone recognizer. Each value in the confusion matrices is compared to capture frequent common error patterns and to specify patterns unique to a certain language background. Using the Foreign Speakers' Voice Data of Korean for Artificial Intelligence Learning dataset, common error pattern types are found to be (1) substitutions of aspirated or tense consonants with plain consonants, (2) deletions of syllable-final consonants, and (3) substitutions of diphthongs with monophthongs. On the other hand, thirty-nine patterns including (1) syllable-final /l/ substitutions with /n/ for Vietnamese and (2) /\textturnm/ insertions for Japanese are discovered as language-dependent.