 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping an End-to-End Framework for Predicting the Social Communication Severity Scores of Children with Autism Spectrum Disorder
Aug 30, 2024
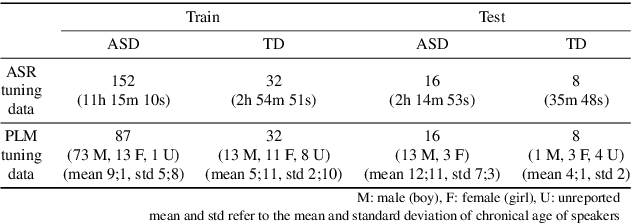
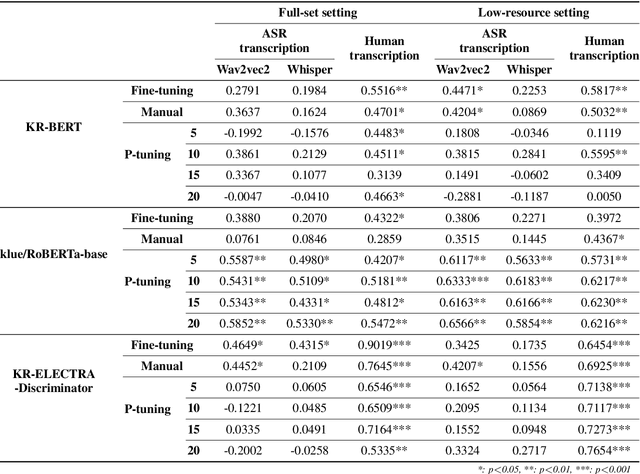
Autism Spectrum Disorder (ASD) is a lifelong condition that significantly influencing an individual's communication abilities and their social interactions. Early diagnosis and intervention are critical due to the profound impact of ASD's characteristic behaviors on foundational developmental stages. However, limitations of standardized diagnostic tools necessitate the development of objective and precise diagnostic methodologies. This paper proposes an end-to-end framework for automatically predicting the social communication severity of children with ASD from raw speech data. This framework incorporates an automatic speech recognition model, fine-tuned with speech data from children with ASD, followed by the application of fine-tuned pre-trained language models to generate a final prediction score. Achieving a Pearson Correlation Coefficient of 0.6566 with human-rated scores, the proposed method showcases its potential as an accessible and objective tool for the assessment of ASD.
Speech Corpus for Korean Children with Autism Spectrum Disorder: Towards Automatic Assessment Systems
Feb 23, 2024



Despite the growing demand for digital therapeutics for children with Autism Spectrum Disorder (ASD), there is currently no speech corpus available for Korean children with ASD. This paper introduces a speech corpus specifically designed for Korean children with ASD, aiming to advance speech technologies such as pronunciation and severity evaluation. Speech recordings from speech and language evaluation sessions were transcribed, and annotated for articulatory and linguistic characteristics. Three speech and language pathologists rated these recordings for social communication severity (SCS) and pronunciation proficiency (PP) using a 3-point Likert scale. The total number of participants will be 300 for children with ASD and 50 for typically developing (TD) children. The paper also analyzes acoustic and linguistic features extracted from speech data collected and completed for annotation from 73 children with ASD and 9 TD children to investigate the characteristics of children with ASD and identify significant features that correlate with the clinical scores. The results reveal some speech and linguistic characteristics in children with ASD that differ from those in TD children or another subgroup of ASD categorized by clinical scores, demonstrating the potential for developing automatic assessment systems for SCS and PP.
Comparison of L2 Korean pronunciation error patterns from five L1 backgrounds by using automatic phonetic transcription
Jun 19, 2023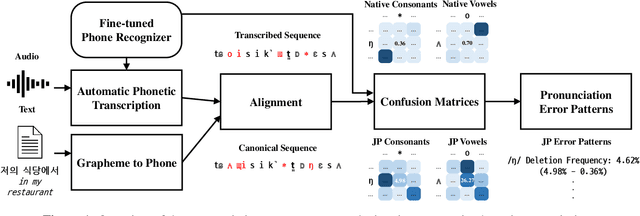



This paper presents a large-scale analysis of L2 Korean pronunciation error patterns from five different language backgrounds, Chinese, Vietnamese, Japanese, Thai, and English, by using automatic phonetic transcription. For the analysis, confusion matrices are generated for each L1, by aligning canonical phone sequences and automatically transcribed phone sequences obtained from fine-tuned Wav2Vec2 XLS-R phone recognizer. Each value in the confusion matrices is compared to capture frequent common error patterns and to specify patterns unique to a certain language background. Using the Foreign Speakers' Voice Data of Korean for Artificial Intelligence Learning dataset, common error pattern types are found to be (1) substitutions of aspirated or tense consonants with plain consonants, (2) deletions of syllable-final consonants, and (3) substitutions of diphthongs with monophthongs. On the other hand, thirty-nine patterns including (1) syllable-final /l/ substitutions with /n/ for Vietnamese and (2) /\textturnm/ insertions for Japanese are discovered as language-dependent.
Speech Intelligibility Assessment of Dysarthric Speech by using Goodness of Pronunciation with Uncertainty Quantification
May 28, 2023



This paper proposes an improved Goodness of Pronunciation (GoP) that utilizes Uncertainty Quantification (UQ) for automatic speech intelligibility assessment for dysarthric speech. Current GoP methods rely heavily on neural network-driven overconfident predictions, which is unsuitable for assessing dysarthric speech due to its significant acoustic differences from healthy speech. To alleviate the problem, UQ techniques were used on GoP by 1) normalizing the phoneme prediction (entropy, margin, maxlogit, logit-margin) and 2) modifying the scoring function (scaling, prior normalization). As a result, prior-normalized maxlogit GoP achieves the best performance, with a relative increase of 5.66%, 3.91%, and 23.65% compared to the baseline GoP for English, Korean, and Tamil, respectively. Furthermore, phoneme analysis is conducted to identify which phoneme scores significantly correlate with intelligibility scores in each language.
A speech corpus for chronic kidney disease
Nov 03, 2022



In this study, we present a speech corpus of patients with chronic kidney disease (CKD) that will be used for research on pathological voice analysis, automatic illness identification, and severity prediction. This paper introduces the steps involved in creating this corpus, including the choice of speech-related parameters and speech lists as well as the recording technique. The speakers in this corpus, 289 CKD patients with varying degrees of severity who were categorized based on estimated glomerular filtration rate (eGFR), delivered sustained vowels, sentence, and paragraph stimuli. This study compared and analyzed the voice characteristics of CKD patients with those of the control group; the results revealed differences in voice quality, phoneme-level pronunciation, prosody, glottal source, and aerodynamic parameters.
Automatic Severity Assessment of Dysarthric speech by using Self-supervised Model with Multi-task Learning
Oct 27, 2022Automatic assessment of dysarthric speech is essential for sustained treatments and rehabilitation. However, obtaining atypical speech is challenging, often leading to data scarcity issues. To tackle the problem, we propose a novel automatic severity assessment method for dysarthric speech, using the self-supervised model in conjunction with multi-task learning. Wav2vec 2.0 XLS-R is jointly trained for two different tasks: severity level classification and an auxilary automatic speech recognition (ASR). For the baseline experiments, we employ hand-crafted features such as eGeMaps and linguistic features, and SVM, MLP, and XGBoost classifiers. Explored on the Korean dysarthric speech QoLT database, our model outperforms the traditional baseline methods, with a relative percentage increase of 4.79% for classification accuracy. In addition, the proposed model surpasses the model trained without ASR head, achieving 10.09% relative percentage improvements. Furthermore, we present how multi-task learning affects the severity classification performance by analyzing the latent representations and regularization effect.
Multilingual analysis of intelligibility classification using English, Korean, and Tamil dysarthric speech datasets
Sep 27, 2022
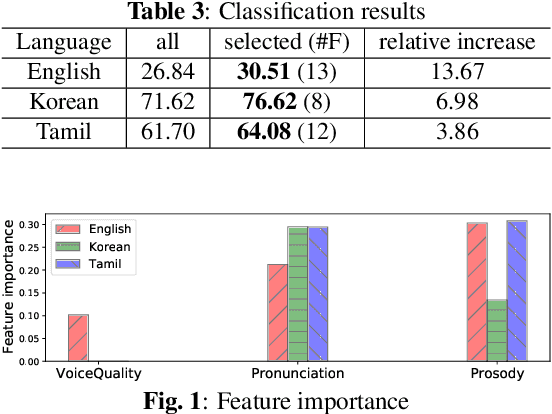
This paper analyzes dysarthric speech datasets from three languages with different prosodic systems: English, Korean, and Tamil. We inspect 39 acoustic measurements which reflect three speech dimensions including voice quality, pronunciation, and prosody. As multilingual analysis, examination on the mean values of acoustic measurements by intelligibility levels is conducted. Further, automatic intelligibility classification is performed to scrutinize the optimal feature set by languages. Analyses suggest pronunciation features, such as Percentage of Correct Consonants, Percentage of Correct Vowels, and Percentage of Correct Phonemes to be language-independent measurements. Voice quality and prosody features, however, generally present different aspects by languages. Experimental results additionally show that different speech dimension play a greater role for different languages: prosody for English, pronunciation for Korean, both prosody and pronunciation for Tamil. This paper contributes to speech pathology in that it differentiates between language-independent and language-dependent measurements in intelligibility classification for English, Korean, and Tamil dysarthric speech.
Cross-lingual Dysarthria Severity Classification for English, Korean, and Tamil
Sep 26, 2022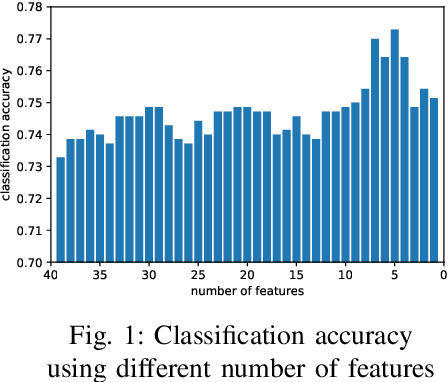

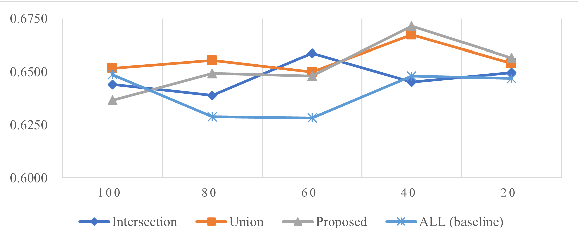
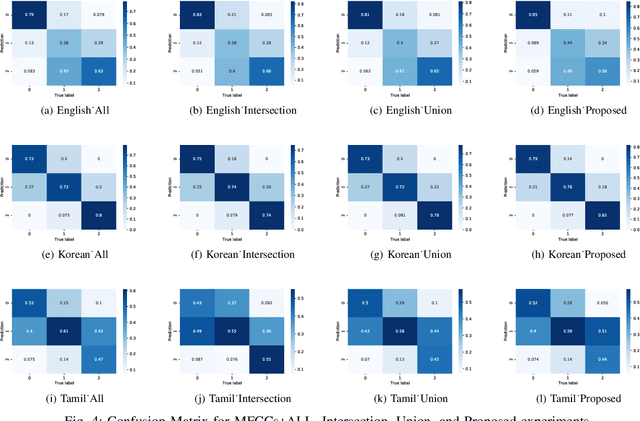
This paper proposes a cross-lingual classification method for English, Korean, and Tamil, which employs both language-independent features and language-unique features. First, we extract thirty-nine features from diverse speech dimensions such as voice quality, pronunciation, and prosody. Second, feature selections are applied to identify the optimal feature set for each language. A set of shared features and a set of distinctive features are distinguished by comparing the feature selection results of the three languages. Lastly, automatic severity classification is performed, utilizing the two feature sets. Notably, the proposed method removes different features by languages to prevent the negative effect of unique features for other languages. Accordingly, eXtreme Gradient Boosting (XGBoost) algorithm is employed for classification, due to its strength in imputing missing data. In order to validate the effectiveness of our proposed method, two baseline experiments are conducted: experiments using the intersection set of mono-lingual feature sets (Intersection) and experiments using the union set of mono-lingual feature sets (Union). According to the experimental results, our method achieves better performance with a 67.14% F1 score, compared to 64.52% for the Intersection experiment and 66.74% for the Union experiment. Further, the proposed method attains better performances than mono-lingual classifications for all three languages, achieving 17.67%, 2.28%, 7.79% relative percentage increases for English, Korean, and Tamil, respectively. The result specifies that commonly shared features and language-specific features must be considered separately for cross-language dysarthria severity classification.