 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Dysarthria Severity Classification for English, Korean, and Tamil
Paper and Code
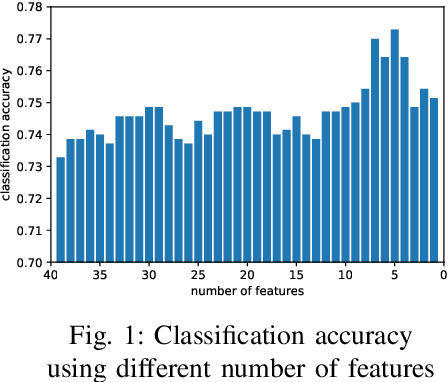

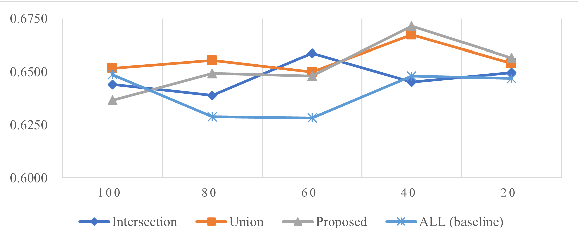
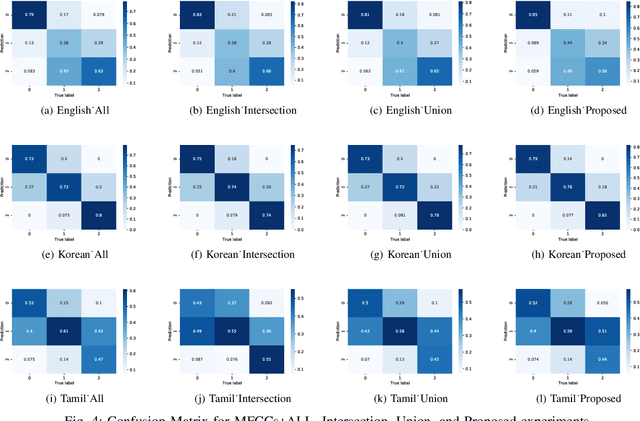
This paper proposes a cross-lingual classification method for English, Korean, and Tamil, which employs both language-independent features and language-unique features. First, we extract thirty-nine features from diverse speech dimensions such as voice quality, pronunciation, and prosody. Second, feature selections are applied to identify the optimal feature set for each language. A set of shared features and a set of distinctive features are distinguished by comparing the feature selection results of the three languages. Lastly, automatic severity classification is performed, utilizing the two feature sets. Notably, the proposed method removes different features by languages to prevent the negative effect of unique features for other languages. Accordingly, eXtreme Gradient Boosting (XGBoost) algorithm is employed for classification, due to its strength in imputing missing data. In order to validate the effectiveness of our proposed method, two baseline experiments are conducted: experiments using the intersection set of mono-lingual feature sets (Intersection) and experiments using the union set of mono-lingual feature sets (Union). According to the experimental results, our method achieves better performance with a 67.14% F1 score, compared to 64.52% for the Intersection experiment and 66.74% for the Union experiment. Further, the proposed method attains better performances than mono-lingual classifications for all three languages, achieving 17.67%, 2.28%, 7.79% relative percentage increases for English, Korean, and Tamil, respectively. The result specifies that commonly shared features and language-specific features must be considered separately for cross-language dysarthria severity classification.