 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Statistical Rates and Provably Efficient Criteria of Latent Diffusion Transformers (DiTs)
Paper and Code
Jul 01, 2024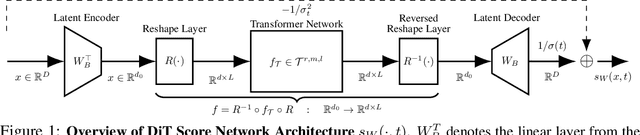
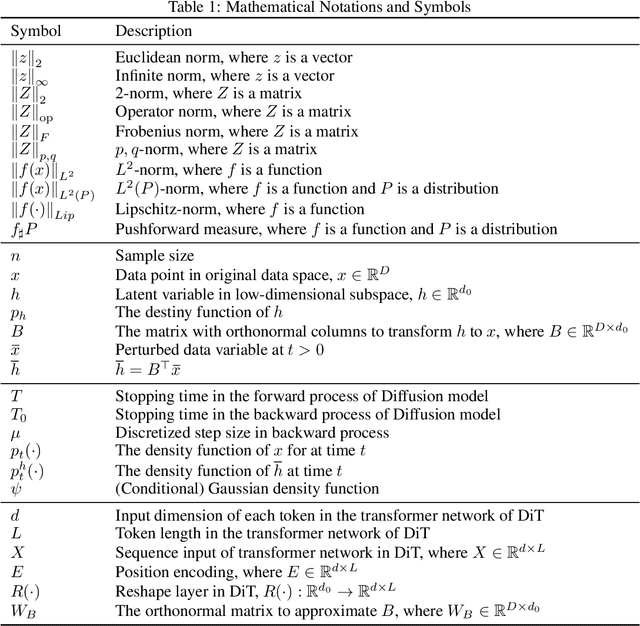
We investigate the statistical and computational limits of latent \textbf{Di}ffusion \textbf{T}ransformers (\textbf{DiT}s) under the low-dimensional linear latent space assumption. Statistically, we study the universal approximation and sample complexity of the DiTs score function, as well as the distribution recovery property of the initial data. Specifically, under mild data assumptions, we derive an approximation error bound for the score network of latent DiTs, which is sub-linear in the latent space dimension. Additionally, we derive the corresponding sample complexity bound and show that the data distribution generated from the estimated score function converges toward a proximate area of the original one. Computationally, we characterize the hardness of both forward inference and backward computation of latent DiTs, assuming the Strong Exponential Time Hypothesis (SETH). For forward inference, we identify efficient criteria for all possible latent DiTs inference algorithms and showcase our theory by pushing the efficiency toward almost-linear time inference. For backward computation, we leverage the low-rank structure within the gradient computation of DiTs training for possible algorithmic speedup. Specifically, we show that such speedup achieves almost-linear time latent DiTs training by casting the DiTs gradient as a series of chained low-rank approximations with bounded error. Under the low-dimensional assumption, we show that the convergence rate and the computational efficiency are both dominated by the dimension of the subspace, suggesting that latent DiTs have the potential to bypass the challenges associated with the high dimensionality of initial data.