 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
Mars: Situated Inductive Reasoning in an Open-World Environment
Oct 10, 2024
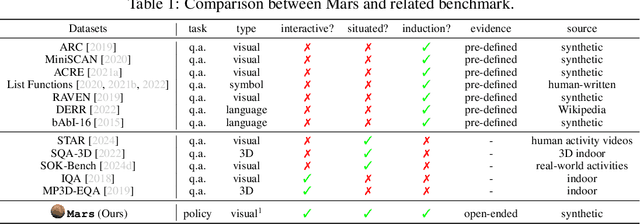
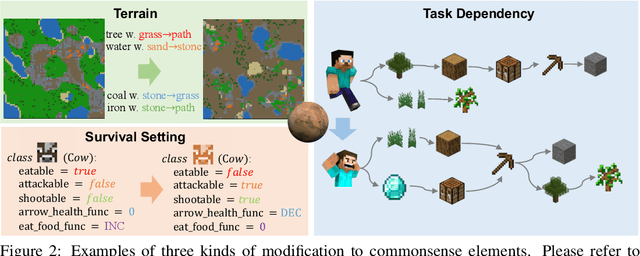
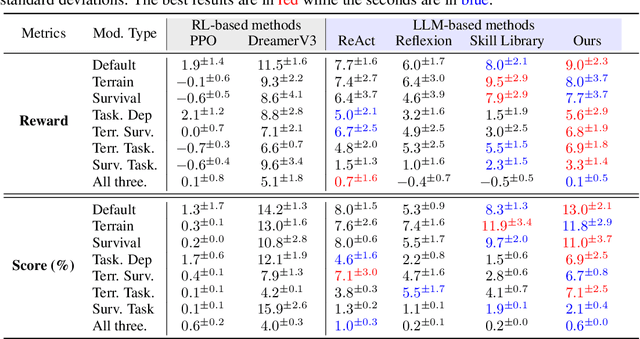
Large Language Models (LLMs) trained on massive corpora have shown remarkable success in knowledge-intensive tasks. Yet, most of them rely on pre-stored knowledge. Inducing new general knowledge from a specific environment and performing reasoning with the acquired knowledge -- \textit{situated inductive reasoning}, is crucial and challenging for machine intelligence. In this paper, we design Mars, an interactive environment devised for situated inductive reasoning. It introduces counter-commonsense game mechanisms by modifying terrain, survival setting and task dependency while adhering to certain principles. In Mars, agents need to actively interact with their surroundings, derive useful rules and perform decision-making tasks in specific contexts. We conduct experiments on various RL-based and LLM-based methods, finding that they all struggle on this challenging situated inductive reasoning benchmark. Furthermore, we explore \textit{Induction from Reflection}, where we instruct agents to perform inductive reasoning from history trajectory. The superior performance underscores the importance of inductive reasoning in Mars. Through Mars, we aim to galvanize advancements in situated inductive reasoning and set the stage for developing the next generation of AI systems that can reason in an adaptive and context-sensitive way.
Case-Based or Rule-Based: How Do Transformers Do the Math?
Feb 27, 2024Despite the impressive performance in a variety of complex tasks, modern large language models (LLMs) still have trouble dealing with some math problems that are simple and intuitive for humans, such as addition. While we can easily learn basic rules of addition and apply them to new problems of any length, LLMs struggle to do the same. Instead, they may rely on similar "cases" seen in the training corpus for help. We define these two different reasoning mechanisms as "rule-based reasoning" and "case-based reasoning". Since rule-based reasoning is essential for acquiring the systematic generalization ability, we aim to explore exactly whether transformers use rule-based or case-based reasoning for math problems. Through carefully designed intervention experiments on five math tasks, we confirm that transformers are performing case-based reasoning, no matter whether scratchpad is used, which aligns with the previous observations that transformers use subgraph matching/shortcut learning to reason. To mitigate such problems, we propose a Rule-Following Fine-Tuning (RFFT) technique to teach transformers to perform rule-based reasoning. Specifically, we provide explicit rules in the input and then instruct transformers to recite and follow the rules step by step. Through RFFT, we successfully enable LLMs fine-tuned on 1-5 digit addition to generalize to up to 12-digit addition with over 95% accuracy, which is over 40% higher than scratchpad. The significant improvement demonstrates that teaching LLMs to explicitly use rules helps them learn rule-based reasoning and generalize better in length.
Large Language Models are In-Context Semantic Reasoners rather than Symbolic Reasoners
May 24, 2023The emergent few-shot reasoning capabilities of Large Language Models (LLMs) have excited the natural language and machine learning community over recent years. Despite of numerous successful applications, the underlying mechanism of such in-context capabilities still remains unclear. In this work, we hypothesize that the learned \textit{semantics} of language tokens do the most heavy lifting during the reasoning process. Different from human's symbolic reasoning process, the semantic representations of LLMs could create strong connections among tokens, thus composing a superficial logical chain. To test our hypothesis, we decouple semantics from the language reasoning process and evaluate three kinds of reasoning abilities, i.e., deduction, induction and abduction. Our findings reveal that semantics play a vital role in LLMs' in-context reasoning -- LLMs perform significantly better when semantics are consistent with commonsense but struggle to solve symbolic or counter-commonsense reasoning tasks by leveraging in-context new knowledge. The surprising observations question whether modern LLMs have mastered the inductive, deductive and abductive reasoning abilities as in human intelligence, and motivate research on unveiling the magic existing within the black-box LLMs. On the whole, our analysis provides a novel perspective on the role of semantics in developing and evaluating language models' reasoning abilities. Code is available at {\url{https://github.com/XiaojuanTang/ICSR}}.
RulE: Neural-Symbolic Knowledge Graph Reasoning with Rule Embedding
Oct 24, 2022



Knowledge graph (KG) reasoning is an important problem for knowledge graphs. It predicts missing links by reasoning on existing facts. Knowledge graph embedding (KGE) is one of the most popular methods to address this problem. It embeds entities and relations into low-dimensional vectors and uses the learned entity/relation embeddings to predict missing facts. However, KGE only uses zeroth-order (propositional) logic to encode existing triplets (e.g., ``Alice is Bob's wife."); it is unable to leverage first-order (predicate) logic to represent generally applicable logical \textbf{rules} (e.g., ``$\forall x,y \colon x ~\text{is}~ y\text{'s wife} \rightarrow y ~\text{is}~ x\text{'s husband}$''). On the other hand, traditional rule-based KG reasoning methods usually rely on hard logical rule inference, making it brittle and hardly competitive with KGE. In this paper, we propose RulE, a novel and principled framework to represent and model logical rules and triplets. RulE jointly represents entities, relations and logical rules in a unified embedding space. By learning an embedding for each logical rule, RulE can perform logical rule inference in a soft way and give a confidence score to each grounded rule, similar to how KGE gives each triplet a confidence score. Compared to KGE alone, RulE allows injecting prior logical rule information into the embedding space, which improves the generalization of knowledge graph embedding. Besides, the learned confidence scores of rules improve the logical rule inference process by softly controlling the contribution of each rule, which alleviates the brittleness of logic. We evaluate our method with link prediction tasks. Experimental results on multiple benchmark KGs demonstrate the effectiveness of RulE.